글을 쓰는 것이 중요성을 신입 때는 몰랐습니다. 내 기억력은 충분히 좋을줄 알았고 대화로 모든 것을 해결할 수 있을 것 같았습니다. 하지만 기억은 휘발되고 일의 절차와 내용은 문서로 남겨야만 의미가 있다는 것을 알게 되었고 글쓰기 모임은 이런 저의 갈증을 해결할 수 있는 선택지였습니다. 2023년 봄, 글을 쓰지 않는 사람은 사기꾼 이라는 전 팀장님의 말이 떠올라 글또 신청서를 넣고 8, 9 10기까지 진행했습니다. 이번 글은 지난 3년간 개발자 글쓰기 모임을 하면서 했던 활동을 회고하여 좋았던 점과 나의 삶의 방향이 어떻게 바뀌었는지 한번 작성해보고자 합니다.
1. 참여자로서의 8기
왜 하필 글쓰기 모임인가?
왜 하필 개발자의 글쓰기 모임일까? 저는 본래 공학에 대한 관심이 매우 많습니다. 하드웨어와 소프트웨어의 원리, 물체의 이치 등에 관심이 많은 사람이였고 자연스럽게 데이터 분야를 접하면서 이를 기반으로하는 개발 지식도 흡수하길 좋아했습니다. 또한 글쓰기의 중요성은 서두에 기술한 바있지만, 꽤나 생산적인 활동이고 꾸준히 내 지식을 축적해 나간다는 점에서 마음에 들었습니다. 재밌게도 이 기술 블로그의 출발은 대학교 시절 실험 연구 보고서를 아카이빙 하기 위한 목적으로 시작되었습니다.(실제로 화학생명공학 실험 키워드로 여전히 유입이 존재한다..)
운영진을 만나다.
2주마다 글쓰는 것이 대단한 어떤 결과를 만들어준다고는 기대하기 어려울 수 있습니다. 하지만 인생은 적분이라고 작은 변화들이 모여 지금의 나를 크게 변화시켰던 것 같습니다. 특히 IT 와 데이터 과학분야는 변화의 발걸음이 커서 그때 마다 적절한 자료나 레퍼런스를 아카이빙하는 것이 꽤나 도움이 됩니다. 이렇게 조금씩 글을 작성해 나갈때 쯔음 자체 데이터 반상회 모임에서 운영 담당에 지원했습니다. 그렇게 만난 글또의 운영진 정희님께 왜 운영진을 하냐는 질문을 해보았습니다.
성윤님을 옆에서 본다는 것. 그 이상의 이유가 필요할까요?
단순하지만 명확했습니다. 사실 성윤님이라는 한 명의 가치 뿐 아니라, 커뮤니티의 가치에 대해서 생각해보았습니다. 데이터 직군은 신생된지 얼마 되지 않아서 어떤 북극성 지표가 필요했으며, 다른사람이 어떻게 하고 있나라는 메타인지를 통해서 스스로 발전하는 변화가 필요한직군입니다. 그런 점에서 옆에서 함께 많이 배울 수 있는 사람과 환경이라고 생각 되었고 곰곰히 생각한 끝에 9기에는 운영진으로 지원하기로 결심하게 되었습니다.
2. 운영진으로서의 9기
Activation 크루 지원
9기 운영진을 준비하기 위해 내가 무엇을 할 수 있는가 뾰족하게 고민했습니다. 뒤돌아보니 제가 했던 다양한 활동들과 장으로서 일했던 경험이 소규모의 동호회를 유지하고 발전시키는데 장점이 있음을 파악했습니다. 그래서 저는 한장짜리 제안서를 함께 제출했습니다.
사실 이런 아이디어의 근간은 ChatGPT 가 활황이던 23년의 시대적 배경과 함께합니다. 8기 쯤하여 AI 코딩 어시스트 기술이 발전하고 대부분의 IT직군들이 일자리를 잃지 않을까하는 두려움에 다들 만나서 ChatGPT과 일자리에 대한 논의가 활발했습니다. 또한, 이직이나 조직생활 나아가서 밥먹고 사는 문제까지 다들 모여서 고민을을 나누는 시간들이 빈번했습니다. 저는 이런 자유로운 토론과 대화가 글또의 가치를 사용자들에게 주는 경험이라고 생각했고, 이를 좀 더 Global하게 키우는 것이 장기적으로 사용자의 리텐션 향상에 도움이 될 것이라는 가설을 세웠습니다. 실제로 지난 8기에서 오프라인으로 만난 참여자 6명은 글제출을 9.1번으로 평균 이상의 활동량을 보임을 확인했습니다. 이러한 경험을 바탕으로 다음 지원서를 작성했습니다.
9기 운영진 지원 형식
글또 하우스 2회 개최
위 고민을 담아 9기에서 글또하우스를 2회 개최했습니다. 지난 서비스 "클럽하우스" 본따 소수의 스피커와 다수의 청중으로 이루어진 고민상담소로 기획했습니다. 실제로 좋은 반응을 보였고, 1회에는 53명이 지원할 들어올정도로 많은 호응을 받았습니다. 이때 몇가지 회고를 하자면
Zoom으로 진행되어 소수의 스피커로 집중되지만 채팅 참여가 활발해서 다수의 의견을 들을 수 있는 장점
1차에는 인원이 많아서 정해진 시간에 쫓기는 느낌이 들어서 아쉬웠고, 참여자가 적은 2차는 여유로웠음
진행자가 상담을 하는 상황이 자주 벌어지는데 모르는 분야에 대해서 코멘트 다는게 어려운 단점
정해진 시간 내 탐색 -> 수렴 -> 결과 등의 진행방식의 필요성
상담자들의 도전지향형/안정지향형이 해법이 섞여있어서 좋았음
정도로 기억이 납니다. 이런 상담을 하는 와중에 진정 내가 이렇게 사람들에게 조언을 할 수 있는 똑똑한 혹은 대단한 사람인가에 대한 회의가 커졌고, 다음에는 pivot하여 다른 방법으로 기여해보자는 방향을 설정하게 됩니다.
3. 10기의 시작
CRM 크루로 pivot과 글또 내 활동들
Activation 크루는 재밌었고 좋았지만 좀 더 데이터 기반하여서 보길 원했습니다. 그래서 CRM 크루로 일단 이전을 신청했습니다. CRM의 사전적 의미는 고객관계관리이지만, 글또에서는 데이터를 가장 가까이 보고 관심있어하는분들이 많았습니다. 9기에 보냈던, 슬랙기반의 데이터를 활용한 글또 내 활동요약이 핵심 프로젝트 중 하나였고 역시 10기도 추진하게 되었습니다.
특히 10기에는 운영진 역할에 국한하지 않고 적극적으로 스터디와 4채널 활동을 많이 했던 기억이 납니다. 작은 호기심을 가지고 짧은 분석을 해보는 월간 데이터 노트, 테니스모임, 다진마늘 모임, 마인크래프트 서버 운영기, LLM 사이드프로젝트까지 오프라인 모임이 제약되는 상황에서도 다양한 활동을 할 수 있어서 매우 좋았습니다. 각 활동들에 대한 후기는 나중에 한번 정리를... 특히 월간 데이터 노트는 본격적으로 시스템화 해서 월별 루틴으로 올릴 예정이라서 나름 기대하고 있습니다.
처음에는 책과 같은 레퍼런스에서 얻을 수 있는 프로젝트가 다수인데 갈수록 내 호기심과 아이디어로 구현하가는 과정이 흥미롭습니다. 특히 8번 슬랙 봇 커뮤니티 활성하기는 순수하게 호기심과 재미로 시작한 것인데, 글또 내 큐레이션 선정도 되고 공감도 가장 높은 글이라서 작성하던 시기에도 후에도 보람찼던 경험이 있습니다. 역시 사람은 재밌는거 해야해?
사실 회사다닐 때는 책이나 스터디를 등한시 해왔습니다만, 갈수록 AI툴들이 수단을 고도화하고 기존의 툴을 대체하는 시대에 결국 살아남는 가치는 그 원리를 파악하고 잘 이용한는 방법이라는 결론에 도달하게 되었습니다. 에이 무슨 6년차에 스터디야 라고 생각했던 저는 다시 활자를 읽기 시작했고, 기존에 DA,DS에만 국한하던 스터디에서 CS까지 확장하게 되었습니다. 특히 데이터중심어플리케이션 설계(DDIA)는 백엔드 개발자들에게는 필독서로 추앙받는데, 함께 스터디하면서 전공을 다시듣는 그런 재미난 경험이었습니다.
글또의 대부분이 그러하든 나의 역할과 방향성에 고민을 하는 글들이 다수 발견됩니다. ㅋㅋ 생각이 많은 1인... 그런데 활자로 적는것 만큼 또 정리가 잘되는게 없습니다. 초반에는 아 뭐해먹고 살지 데이터분석은 뭘까 라는 등등에 대한 방향성으로 글을 써왔는데 점차 나의 목표가 뚜렷해지니 주제가 더 명확해지는 흐름이 보이네요. 이런 회고도 참 재밌습니다!
4. 갈무리 - 정량적 성과보기
블로그 성과 보기
직무에 대한 고민 글과 프로젝트, 스터디를 하면서 올라간 내면의 질적인 향상도 있지만 명시적으로 오른 지표는 방문자 수와 조회 수입니다. 월 천명, 조회수 2천건의 블로그로 성장했습니다. 데이터 분야 입문할 때만해도 Ratsgo's Blog나 어쩐지 오늘은 같은 데이터 블로그 글들로 공부를 많이했는데 어쩌면 저도 그런 블로그가 될 수 있을까 싶습니다 ㅋ_ㅋ
두번째로는 노출과 CTR입니다. 점점 글을 작성하면서 알게모르게 블로그의 랭크가 높아졌고, 메타 태그 설정, 구글 서치콘솔까지 연결하니 가장 인기 있는 글은 13%의 CTR를 달성하기도 했습니다.
블로그 전체의 CTR
물론 일반 웹서비스와 다르게, 기술블로그 특성상 적절한 주제라고 생각하면 클릭으로 전환하는 비용이 크지 않기 때문에 큰 값은 아니지만 그래도 꽤나 전환율이 좋은 글들이 많습니다. 특히 통계책으로 검색하면 일반 서점 사이트와 교수님이 쓰신 글! 까지 제치고 상위노출하는 쾌거를 이루어서 기분이 좋았네요.
(좌) 상단노출되는 내 글 (우) 인기목록 Top10
글또에서 양질의 컨텐츠를 얻으면서 배웠던 지식과 커피챗을 하면서 얻었던 아이디어등이 결합된 결과라고 생각됩니다. 물론 글또 뿐 아니라 다양한 글을 완성도에 집착하지 않고 일단 하자! 라는 결심으로 차곡히 쌓아온 결실이기도 하구요. 이런 환경을 만들어주신 성윤님께 무한 감사!
그래서 앞으로는?
아마 글또가 마무리되니 압박에 시달려서 2주마다 글을 쓰진 않을 수도 있을 것 같습니다. 하지만 글을 쓰는 것에 대한 가치는 더 커졌고 오픈소스처럼 나의 지식을 나누어주는 것에 대한 기쁨도 동반되고 있습니다. 문득 글을 정리하다가 10기의 목표를 "히언님의 친절한 데이터사이언티스트 되기 강좌" 과 같이 동영상보다 좋은 글을 남기자 였는데 이 목표에 지속해서 다가가려 합니다. 앞으로는 방통대를 입학해서 공부하고 추후에 대학원 고려도 해볼 수 있을 것 같은데 그때마다 떠오르는 생각과 기술들을 한번씩 적어보겠습니다. 그럼 20000
단일 시스템에서 다중시스템으로 확장하는 것은 단순히 공수의 N배가 아니라는 것을 느끼는 단원. 초반에는 네트워크장애에 대한 기술을 서술하나가는데 그 이후는 그만 정신이 혼미해지는 단원입니다. 그야말로 골칫거리군요. 후반은 읽다가 잠시 정신을 잃어서 이만..
신규개념
개념
설명
타임아웃(Timeout)
서버로 요청을 보냈지만 일정 시간동안 답변을 받지 못할 때 발생시키는 오류
TCP
전송 제어 프로토콜(Transmission Control Protocol), 애플리케이션 사이에서 안전하게 데이터를 통신하는 규약. IP(Internet Protocol)와 엮어서 TCP/IP라고 불리기도 하며, 통신속도를 높이면서도 안전성, 신뢰성을 보장할 수 있는 규약
UDP
사용자 데이터그램 프로토콜 (Universial Datagram Protocol). TCP처럼 네트워크 프로토콜이지만 비연결형 프로토콜이라느 차이점.
이더넷
다수의 시스템이 랜선 및 통신포트에 연결되어 통신이 가능한 네트워크 구조(인터넷 ㄴㄴ)
패킷(Packet)
네트워크에서 주고받을 때 사용되는 데이터 조각들
동기식 통신
Synchronous 동시에 일어남. Request를 보내면 얼마나 시간이 걸리든 그 자리에서 Resonse를 받음
비동기식 통신
Asynchronous, Request 보내도 Response를 언제 받아도 상관 없다. 할일이 끝난 후 Callback을 통해 완료를 알림
1. 비공유 시스템의 오류 관리 방법: 타임 아웃
(New) 분산 시스템은 비공유시스템. 즉 네트워크로 연결된 다수의 장비이다. 네트워크는 장비들이 통신하는 유일한 수단이라는 특징을 가지고 있다. 인터넷과 이더넷은 비동기 패킷 네트워크(asynchronouse packet network)다. 이런 종류의 네트워크에서는 다른 노드로 메시지(패킷)을 보낼 수 있지만 네트워크는 메시지가 언제 도착할지 혹은 머세지가 도착하기는 할지 보장하지 않는다. 여기서 패킷이란 네트워크에서 주고받는 데이터의 조각이다.
약간 mRNA 닮은거는 기분탓인가?
패킷의 기본 구조. 익숙한 단어가 보인다.
요청을 보내고 응답을 기다릴 때 여러가지 오류의 상황이 발생할 수 있다.
요청이 손실되었을 수 있다.(누군가 네트워크 케이블을 뽑았을 수도)
요청이 큐에서 대기하다가 나중에 전송될 수 있다.(네트워크나 수신자에 과부화가 걸렸을 수 도 있다.)
원격 노드에 장애가 생겼을 수 있다.(죽었거나 전원이 나갔을 수 있다.)
원격 노드가 일시적으로 응답하기를 멈췄지만 나중에는 다시 응답하기 시작할 수 있다.
원격 노드가 요청을 처리했지만 응답이 네트워크에서 손실됐을 수 있다.
원격 노드가 요청을 처리했지만 응답이 지연되다가 나중에 전솔될 수 있다.(네트워크가 요청을 보낸 장비가 과부하가 걸렸을 수 있다.)
(a) 요청의 손실 1번 사례, (b) 원격 노드 다운 3번 사례, (c) 응답이 손실 5번 사례
이 문맥을 읽으면서 외계 탐사행성을 위해 발사된 보이저1호의 상황이 상상이 되었다. 응답할 것이라고 기대하고 보내는 전파가 돌아오지 않는 상황이 네트워크 오류와 비슷한 느낌이랄까? 출처: https://www.thedailypost.kr/news/articleView.html?idxno=104231
우리의 요청을 오기까지 그럼 무제한 대기해야할까? 그렇지 않다. 발송이 잘못되었는지, 처리는 되었는지 어느 부분에서 장애가 일어난지 모르니 타임아웃을 이용해서 관리한다고 책은 기술한다. 토스페이먼츠 API Read Timeout은 30-60초로 설정한다고 한다. 이는 경험적인 수치인듯?
이런 문제를 다루는 흔한 방법은 타임아웃이다. 얼마간의 시간이 지나면 응답 대기를 멈추고 응답이 도착하지 않는다고(장애라고) 가정한다. 그렇다면 타임아웃은 얼마나 길어야할까? 타임아웃이 길면 노드가 죽었다고 선언될 때까지 기다리는 시간이 길어진다. 그 시간동안 사용자들은 기다리거나 오류 메시지를 보아야한다. 반면 타임아웃이 짧으면 결함을 빨리 발견하지만 노드가 일시적으로 느려졌을 뿐 결함이 아닌데도 죽었다고 선언할 확률이 높아진다. (뭐예요 나 아직 살아있어요) 단순히 오해에 그치는게 아니라 노드가 죽었다고 판단되면 그 역할이 다른 노드로 전달되는 내결함성으로 인하여 연쇄장애의 원인이 될 수 있다.
이때 인터넷 전화(VoIP)는 지연시간이 민감하기 때문에 TCP보다는 UDP를 선택하는 사례에 대해서 기술한다. UDP는 흐름제어를 따로 하지않고 속도가 빠르며 잃어버린 패킷에 대한 부분을 사람 계층에서 재시도 한다는 표현이 재밌었다. 대표적인 VoIP 서비스인 디스코드가 UDP 통신을 선택하고 있다.
2. 패킷이 유실되지 않는 견고한 네트워크는 어때?
(New) 네트워크에서 패킷이 손실될 수 있다는 점이 단점으로 명확해지는데 그럼 견고한 네트워크는 어디 없을까? 이를 고정회선 네트워크의 예시를 가져온다. 전화 네트워크는 극단적인 신뢰성을 가져서 음성이 지연되거나 통화가 유실되는 매우 드물다. (고양이가 전화선을 뜯지 않는다면 말이지)
이러한 견고함을 유지할 수 있는 이유는 통화를 하는 두 명사이에 있는 전체 보장된 대역폭이 할당된다. 언제까지? 통화가 명시적으로 끝날때까지. 이런 네트워크는 동기식으로 큐 대기가 없으므로 종단 지연시간의 최대치가 고정되어 있다. (제한 있는 지연) 따라서 특정 시간의 간격이 지나도 응답이 오지 않는다면 명백한 통신실패임이 확실하다.
반면 TCP연결은 가용한 네트워크 폭을 변화하면서 사용한다. 그러니까 연결이 없다면 어떤 대역폭도 사용하지 않는다. 연결이 있다면 기약없는 지연이 발생할 수 없는 구조이다. 그저 빨리 완료되길 기도하는 메타이다.
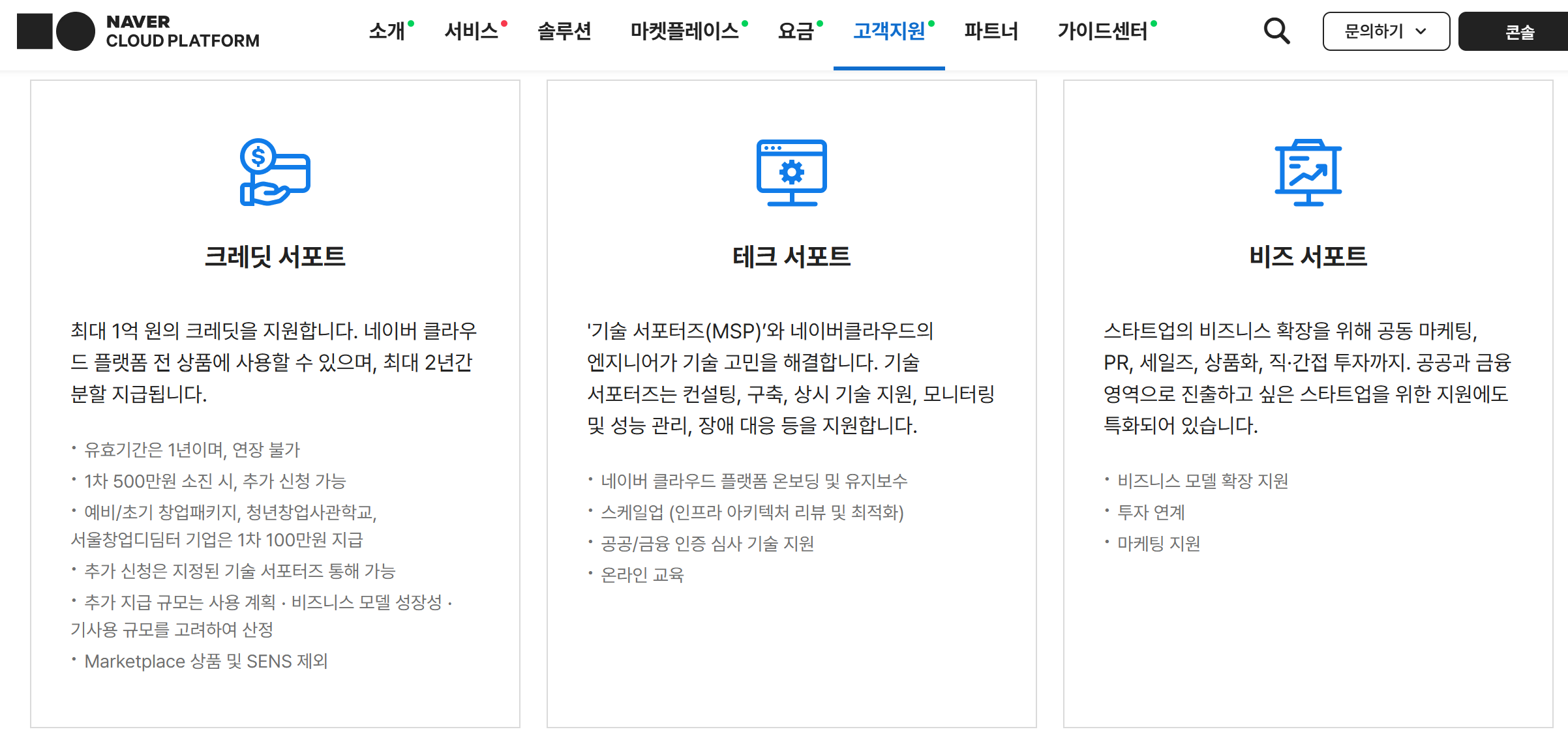
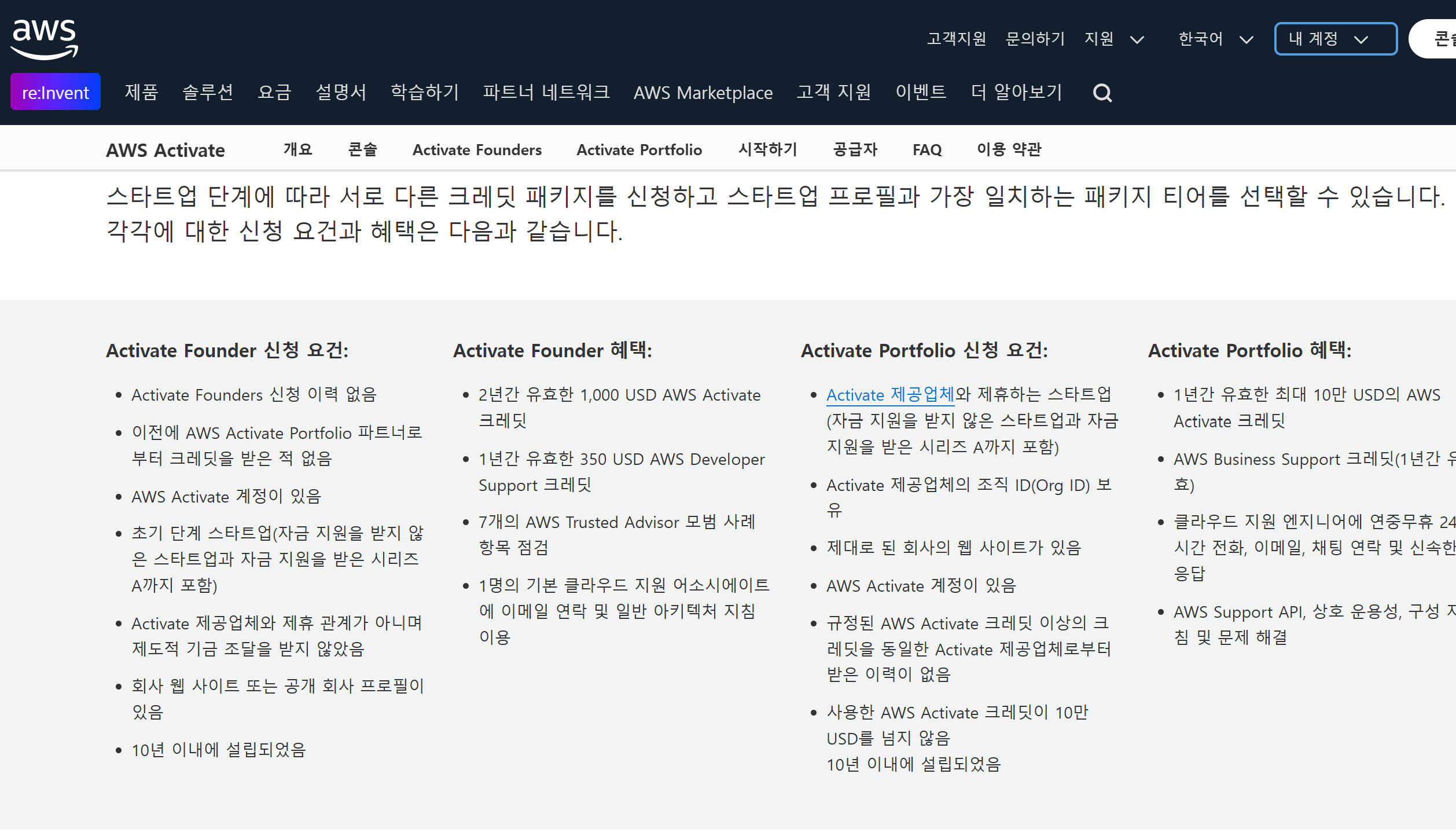
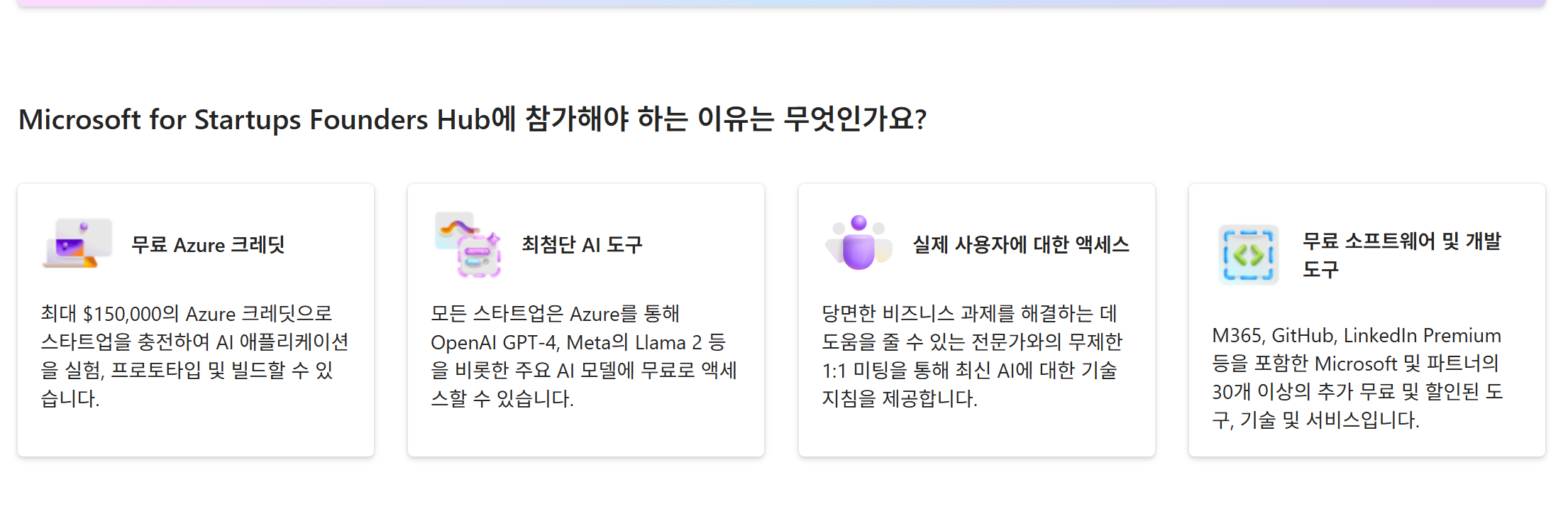
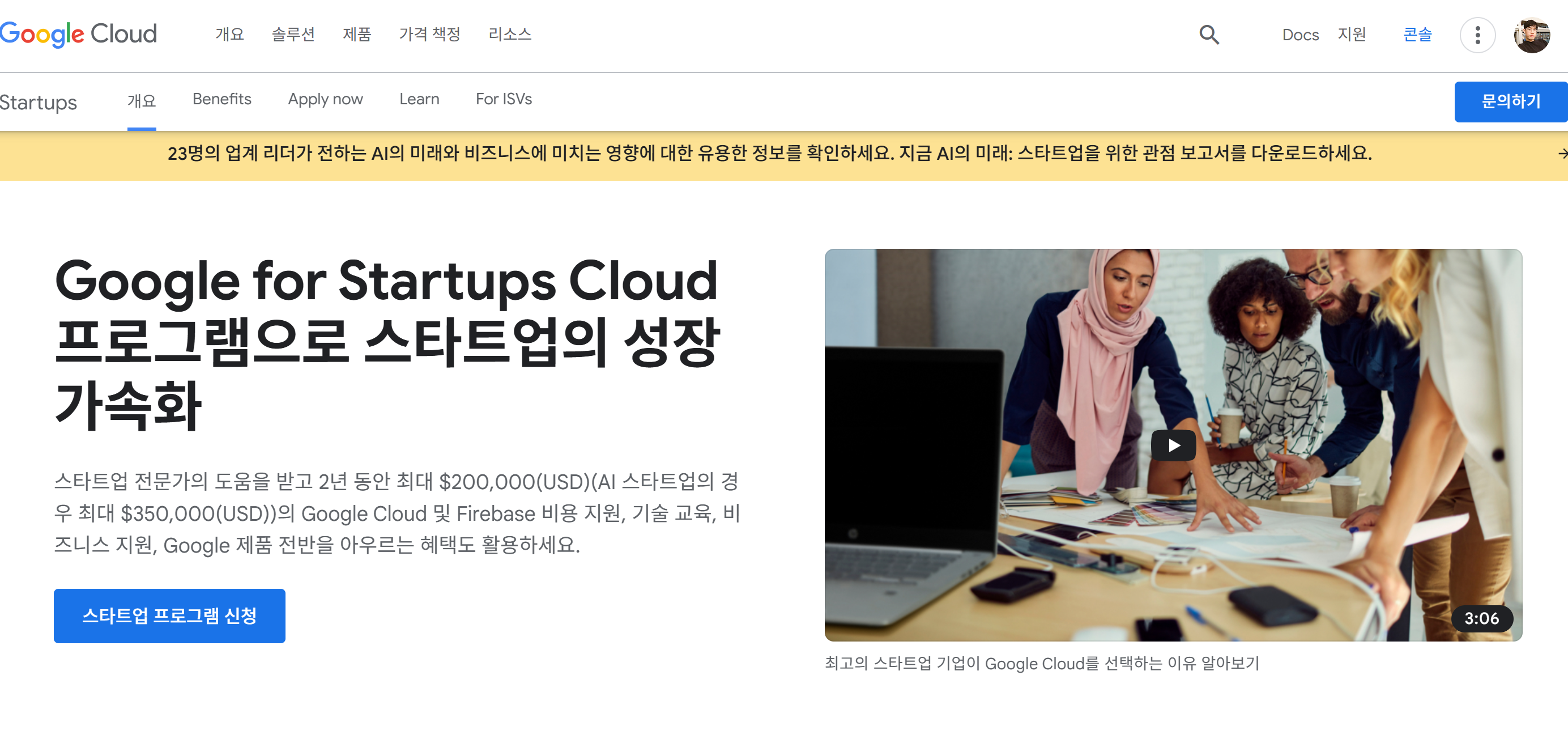
사이드프로젝트 혹은 사내 작은 프로젝트를 하기 위한 클라우드 서비스별 크레딧을 정리해보았습니다. 하기 내용은 정확하지 않을 수 있으며, 해당 서비스의 공식홈페이지를 참고하시는 것을 추천드립니다.
문서버전: 2025-03-24 최초 등록
일반 사용자
NCP 10만원, 3개월
접근성이 쉬움 + Naver API 사용하기도 좋음
GCP 300 달러 크레딧, 3개월
GCP는 Computing resource 하나 조건무관 제공 (Disk 30GiB)
AWS 프리티어 12개월 무료(쿠폰적용시 100달러)
GCP와 달리 1년 지나면 무료 해지인듯!
Azure 200 달러
후발 주자여서 그런지 지원 정책이 올라오고 있는 중
사업자/스타트업
개인의견:
사업자 & 스타트업 신청은 굳이라고 생각하실 수도 있지만, 개인사업자의 경우 국내 홈택스에 쉽게 사업자를 낼 수 있습니다. 다만 청년창업소득세면제와 같은 쿠폰을 써버리는게 아깝다고 사업자를 내는걸 꺼려할 수도 있지만 사실 뭘 안하는것보다 일단 하는게 좋다는 생각입니다. 법인사업자의 경우 절차와 신고 등이 부가적인 것이기 때문에 굳이 추천 드리진 않습니다.
이번 글에서는 복제에 이어 데이터 파티셔닝 방법과 이를 인덱싱하기 위한 전략을 알아봅니다. 특히 데이터가 커지는 경우에는 필수적으로 파티셔닝이 필요하며, 이를 나누기 위한 키-범위 파티셔닝과 해쉬 파티셔닝에 대해서 알아보고, 쓰기와 읽기 성능을 고려한 로컬과 글로벌 이차 인덱스방법에 대해서 기술합니다. 또한 개발이 끝이 아니듯 운영에서 발생할 수 있는 리밸런싱 전략에 대해서 알아봅니다. 전반적으로 대용량 데이터베이스를 설계자 입장에서 고려하고 고민할 것들이 많이 도출 되는 좋은 단원이였습니다!
신규개념
개념
설명
파티셔닝(Partitioning)
성능, 확장성, 유지성을 목적으로 논리적인 데이터를 다수의 엔터티로 분할하는 행위
복제(Replication)
동일한 데이터를 여러 노드에 저장하여 장애 복구를 대비하는 방법
노드(Node)
스토리지 단일 서비스 혹은 네트워크 일부를 구성하는 서버
핫스팟(Hospot)
특정 파티션에 부하가 집중되는 현상
해시 파티셔닝
데이터를 균등하기 분산시키기 위해서 해시 함수를 사용
키 범위 파티셔닝
연속된 키 범위에 따라 데이터를 분배
이차 인덱스 파티셔닝
검색을 위한 인덱스를 파티셔닝하는 방식
리밸런싱(Rebalancing)
노드 추가/삭제 시 데이터를 재분배하는 과정
라우팅(Routing)
네트워크에서 경로를 선택하는 프로세스
1. 파티셔닝의 정의
파티셔닝이란 큰 데이터베이스를 여러 개의 작은 데이터 베이스로 나누는 기법
네트워크 분할(Network Partition)과는 다르며 주 목적은 확장성(Scalability) 확보
대용량 데이터를 효율적으로 관리하고 고 성능 쿼리 처리를 가능하게 한다.
보통 샤딩(Sharding)이라는 용어와 혼동되며 데이터 베이스마다 다르게 불
(Amendment) 사실 파티셔닝이라는 개념은 윈도우 설치할 때 하나의 디스크에 "파티셔닝"하여 C / D드라이브로 만들 때 마주할 수 있다.
이처럼 파티셔닝은 데이터베이스를 논리적으로나 물리적으로 분할하여 관리하는 기술로, 데이터 베이스의 성능응 향상시키고 관리를 용이하게 합니다. 파티셔닝을 통해 데이터 베이스 조회 속도를 높이고 백업 및 복구시간을 단축할 수 있기 때문입니다.
출처: F-lab 데이터 파티셔닝 전략
2. 파티셔닝과 복제
대부분의 시스템에서 파티셔닝과 복제가 함께 사용됨
파티셔닝: 데이터를 여러 노드에 나누어서 저장
복제: 동일한 데이터를 여러 노드에 저장하여 장애 대비
(Amendment) 파티셔닝과 복제가 주로 이루어지는 이유는 각 목적을 살펴보면 된다. 데이터의 크기가 커질수록 한 노드(서버)에 저장할 수 없게 된다. 이를 여러 노드에 나워서 수평 확장을 노려볼 수 있다. 파티션 단위로 데이터 읽기/쓰기 작업을 하여 성능 향상을 하는 한편, 특정 파티션만 검색하도록 최적화하여 쿼리 성능을 향상시킬 수 있다. 이로 인한 단점은 한 노드에 한 개만 저장되므로 노드 장애 시 데이터 유실 위험이 존재한다. 반면, 복제는 고가용성(High Availability)와 내결함성(Fault Tolerance) 확보가 목적으로 동일한 데이터를 여러 노드에 복제하여 데이터 손실을 방지하며, 특정 노드가 장애가 나더라도 복제본의 데이터를 제공을 가능하게 한다. 읽기 부하(Read Load)를 여러 복제본에 분산하여 읽기 성능 향상이 가능하며 특히 리더 -팔로워 모델이 유용하다. 단점으론느 복제된 데이터를 주기적으로 동기화해야하므로 쓰기 성능 저하 가능하며 데이터 일관성의 유지가 필요하다. 따라서, 파티셔닝. 을 통해 확장성을 확보하는 한편 복제를 통해 가용성을 보장하는 것이 대규모 데이터 베이스의 운영의 핵심이라고 할 수 있다.
3. 파티셔닝 전략
1. 키 - 범위 파티셔닝(Key Range Partitioning)
연속적인 키 범위를 기준으로 데이터를 분할
장점: 키 순서가 유지되므로 범위 쿼리에 적합
단점: 특정 키 범위에 쿼리가 집중되면 핫 스팟 발생 가능
쉽게 말하면 백과사전에서 특정 단어를 찾는 과정과 비슷하며, Hbase, RethinkDB, MongDB에 쓰임. 핫스팟의 문제는 센서 데이터의 예를 들면 편한데, 만약 센서 데이터의 파티션이 날짜로 지정해되면 특정 파티션은 과부화가 걸리는 반면 다른 파티션은 유후상태(Idle)이 된다. 이를 보완하기 위해서 센서이름 + 타임스탬프 형태의 키를 구성하면 각 센서별로 파티션에 나뉘고 이후 시간 순서대로 저장되므로 쓰기 부하가 고루 분산될 수 있는 장점이 있다.
2. 해시 파티셔닝(Hash Partitioning)
키를 해시 함수에 통과시켜 균등하게 분산
장점: 데이터가 균등하게 분배되어 핫스팟 발생 가능성 적음
단점: 키 정렬이 깨져서 범위 쿼리의 어려움
skwed된 데이터와 hotspot의 문제 때문에 고안된 데이터 모델. 파티션 간의 고른 데이터 분배를 노릴 수 있음.
4. 파티셔닝과 이차 인덱스
이차 인덱스는 데이터 베이스에서 기본 키 이외에 다른 컬럼을 기준으로 빠르게 데이터를 검색하기 위한 인덱스이다. 파티셔닝이 적용된 데이터베이스에서는 기본 키를 기준으로 데이터를 찾는 것은 쉽지만, 기본 키가 아닌 다른 컬럼으로 검색할 때 문제가 발생할 수 있으며 이를 해결하기 위해 이차 인덱스가 등장한다. (Amendement)
CREATE TABLE users (
user_id INT PRIMARY KEY,
name VARCHAR(100),
email VARCHAR(255),
country VARCHAR(50)
);
위 경우 user_id가 기본키이므로 user_id = 1234 는 빠르게 검색 가능한 반면, where country = 'USA' 같은 쿼리는 효율적으로 실행되지 않으므로, 다음 이차 인덱스를 생성하여 검색 성능 향상을 노린다.
CREATE INDEX idx_country ON users(country);
이런 이차 인덱스를 저장함에 있어서 2가지 방식을 선택할 수 있다. 1. 문서 기반 인덱스( Document-partitioned indexes, Local Index)
각 index를 각 파티션에 저장
이차 인덱스를 해당 데이터가 있는 파티션 내부에 저장
이차 인덱스가 기본키 및 값과 동일한 파티션에 저장됨. 즉 데이터 쓰기를 할때는 해당 파티션 하나만 업데이트하면 되므로 쓰기 성능이 우수하다. 반면 이차 인덱스를 기반으로 조회할 경우 모든 파티션을 검색(Scatter)하고 결과를 모아야(Gather)해야하므로 성능 저하 가능성이 있다. (Amendment) 예를 들어 country = 'USA" 데이터가 각 파티션에 분산되어 있다면 각 파티션 마다 country 인덱스가 생성 됨. 데이터를 추가하거나 수정할 때 해당하는 파티션만 업데이트하면 되므로 쓰기 성능이 좋으나, 데이터 검색할 때는 쿼리 속도가 느려질 수 있다. 2. 용어 기반 인덱스(Term-partitioned indexes, Global Index)
Gloabl 인덱스를 여러 파티션에 나눠 저장
이차 인덱스를 별도의 파티션으로 저장
이 방식에서는 이차 인덱스가 기본키와 독립적으로 분할되어 저장되어 이차 인덱스는 특정 필드 기준으로 별도로 파티셔닝된다. 또한 하나의 인덱스 방식이 여러 개의 파티션에 있는 데이터를 포함할 수 있다. 쓰기 시에는 여러개의 파티션을 업데이트 해야하므로 쓰기 성능이 저하될 수 있으나 읽기 시에는 특정 값을 포함하는 단일 파티션에서만 데이터를 가져올 수 있으므로 조회 성능이 향상된다. (Amendement) where country = 'USA' 검색 시 USA 관련 데이터가 저장된 단일 파티션만 조회하면 되므로 성능이 빠르고 읽기 성능이 최적화, 데이터를 추가할 때, 이차 인덱스가 여러 파티션에 걸쳐 존재하므로 여러 개의 파티션을 업데이트 해야하여 쓰기 성능이 저하될 수 있다.
문서기반(로컬 인덱스)
용어기반(글로벌 인덱스)
쓰기성능
빠름
느림
검색성능
느림
빠름
5. 리밸런싱
개발보다 중요한 것은 운영이라고 했던가 필수적으로 데이터베이스를 운영하다보면 특정 노드에 데이터가 집중되거나 부하가 편향되는 불균형(imbalance)가 일어날 수 있다. 따라서 리밸런싱을 통해서 데이터와 쿼리 부하를 공정하게 분배해야하는 요구사항이 반드시 생겨난다. 또한 리밸런싱을 할 떄 지켜야할 원칙은 ① 리밸런싱 후 노드간의 데이터와 부하가 균등해야하며 ② 리밸런싱 과정에서 읽기와 쓰기에 대한 수행은 계속되어야 하며 ③ 리밸런싱의 속도를 빠르고 네트워크 및 디스크 I/O 부하를 최소화하기 위하여 필요한 데이터 이상의 데이터가 노드 간 이동해서는 안된다. 등 이다. 1. 고정된 파티셔닝(Fixed Partitioning)
데이터베이스를 고정된 파티션으로 나누는 기법. 노드가 추가되거나 삭제되어도 파티션의 갯수는 동일
가장 고전적인 방법으로 고정된 파티션의 갯수를 유지하는 방법이다. 하지만 처음에 너무 적은 파티션을 설정하면 확장시 부담이 커지고 많으면 관리 오버헤드가 커진다. 시간이 지나면 특정 파티션에 데이터가 몰려 일부 파티션에만 과부화가 생길 수 있으며, 초기 설정된 파티션의 갯수가 적절한지 어려운 단점이 있다. 따라서 데이터 양이 일정하고 급격한 변화가 없는 경우, 시스템 운영이 단순해야하는 정형데이터의 경우나 리밸런싱 속도가 중요한 경우 고정된 파티셔닝 방법을 고려할 수 있다. 2. 동적 파티셔닝(Dynamic Partitioning) 동적 파티셔닝은 데이터가 증가하면 자동으로 파티션을 2개로 분할하고 반대로 삭제하면 통합하는 방식으로 관리하는 기법이다. 하지만 데이터가 작은 경우 모든 쓰기의 연산이 하나의 노드에서 처리되며 나머지 노드는 유후(Idle)상태가 된다.
6. 라우팅 요청(Request Routing)
리밸런싱이 필요하고 멋지지만 비싼 작업인건 확인해보았다. 그럼 이렇게 수동/자동 혹은 고정/동적인 리밸런싱 과정 속에서 데이터 읽기/쓰기에 대한 요청이 들어왔을 때 누가 중재해줄 것인가에 대한 질문이 자동으로 생긴다. 이를 Service Discovery 라고 한다.
foo 라는 자료를 찾을 때 시도할 수 있는 방법 3가지
아마 합리적인 방법은 각 파티션이 가지고 있는 key range에 대한 정보를 저장하는 것이고 이를 ZooKeeper 라고 한다.
7. 마무리
사실 데이터에 쿼리를 날려만 봤지 대용량 데이터를 저장하는 설계쪽에서는 생각해본적이 거의 없다. 데이터의 무결성과 정합성을 지키기위한 방법부터 초기 데이터베이스에서 확장가능하면서 성능을 최적화하기 위한 파티셔닝 그리고 그 파티셔닝을 운영단계에서 리밸런싱 하는 과정 등을 한번에 볼 수 있는 너무나 좋은 단원이라고 생각되었다. 물론 SaaS 서비스에서는 이를 서비스에 맡기고 인간의 개입은 최소화하겠지만 이런 이론들을 알고 공부할 수 있는 이 책의 전개 흐름과 다이어그램이 너무 좋았다. 또또 공부해보고 싶은 마음이 든다. 이 단원을 통해 앞으로 알았으면 좋겠는 것들은 다음과 같다.
솔직히 말이죠 이런 책을 읽는다는게 쉽지만은 않습니다만, 특히 이번장에서는 데이베이스의 저장구조와 검색에 대한 테크니컬한 내용이 많이 들어가서 중간에 도망갈뻔 했습니다. 그런데 참고 읽다보니 OLTP와 OLAP에 대한 구조가 너무나도 비교가 잘되었고 최근(?) 유행하게 되었는 칼럼 데이터베이스도 눈 여겨볼 수 있는 좋은 단원이였습니다. 얼마나 좋았나면 분석하는 분들에게 일부 문단을 뜯어서 읽어주고 싶은 느낌이였어요. 필자는 2장에서는 어플리케이션 개발자가 데이터 베이스에 데이터를 제공하는 형식을 설명한다면 3장은 데이터베이스 관점에서 데이터를 저장하는 방법과 요청했을 때 다시 찾을 수 있는 방법에 대해서 안내하고 있습니다. 한번 가보시죠~
신규개념
개념
설명
로그(Log)
컴퓨터 시스템과 네트워크에서 발생하는 활동과 사건에 대한 기록
컴팩션(Compaction)
로그에서 중복된 키를 버리고 각 키의 최신 갱신 값만 유지하는 것을 의미한다.
오버헤드(overhead)
어떤 처리를 하기위해 들어가는 간접적인 처리시간
오프셋(offset)
두번째 주소를 만들기 위해 기준이 되는 주소에 더해진 값(like 상대주소)
병합정렬(mergesort)
하나의 리스트를 균등한 크기로 분할을 하고, 분할된 부분을 정렬한뒤 합치면서 전체 정렬하는 방법
SS테이블(Sorted String Table)
세그먼트 파일 형식에서 키-값 쌍을 가진 테이블 형태의 데이터 구조
LSM 트리
Log Structed merge Tree, 정렬된 파일 병함과 컴팩션 원리를 기반으로 하는 저장소 엔진
OLTP
Online Transaction Processing,인터넷을 통해 많은 사람들이 동시에 데이터베이스를 처리하는 시스템
OLAP
Online Analytical Processing, 온라인상에서 데이터를 분석 처리하는 기술
데이터 웨어하우스
Data Warehouse, 다양한 데이터 소스에서 데이터를 추출, 변환, 요약하여 사용자에게 제공할 수 있는 데이터베이스의 집합체
1. 해시색인, B-tree
(New) 데이터베이스를 가장 쉽게 만드는 방법은 키-값 저장소의 형태로 로그(log)처럼 추가 전용(append only)한 특성을 사용할 수 있다. 하지만 레코드가 많을수록 검색의 비용은 O(n)이기 때문에 성능 최적화 측면에서 바람직하진 않다. 따라서 색인(index)를 이용할 수 있다. 색인은 기본 데이터의 파생된 추가적인 구조이기 때문에, 내용에는 영향을 미치지 않지만 단지 질의 성능에만 영향을 준다.
갑자기 생각난건데, 내가 입사한 회사에서는 의료처방기록을 나라에서 공급받아 분석했었는데, 인덱스가 걸려있는 컬럼이 환자 식별자에만 걸려있냐고 물어보니까, 그냥 모든 컬럼을 걸었다고 답변받았던 기억이난다. 이유는 데이터가 실시간도 아니고 행이 몇 억개밖에 안되어서 그렇다고...
key-value 저장소는 보통 해시 맵(has map)으로 구현하며, 색인 전략은 키를 데이터 파일의 바이트 오프셋에 매핑해 인메모리 해시 맵을 유지하는 전략이다.
하지만 파일에 항상 추가만 한다면 결국 디스크 공간이 부족해진다. 이는 특정 크기의 세그멘트(segment)로 나누는 방식이 좋은 해결책이다. 이를 컴팩션(compaction)을 수행하여 해결할 수 있다. 컴팩션은 로그에서 중복된 키를 버리고 각 키의 최신 갱신 값만 유지하는 것을 의미한다.
고양이(mew) 동영상의 조회수가 1082 최신값으로 업데이트
내가 운영하는 마인크래프트 서버도 latest.log파일에 저장이 되고 일정 수준이 넘어가면 2025-02-21-(1), (2)와 같이 Segemet가 저장되는데 이것도 일부의 compaction 이라 할 수 있을까? 생각했지만 정보를 덮어쓰거나 하지 않으므로 거리가 있다고 생각했다.
(궁금한 점) Youtube 도 Compaction을 이용해 조회수를 업데이트 할까? 근데 그럼 1시간 전의 조회수나 24시간의 조회수는 나중 시점에 알 수 없는걸까? 갓 구글이 이런 데이터가 없을리 없을 것 같고...그냥 log별로 따로 저장할까? 책의 예시를 Youtube에 저장하려니 조금 결이 안맞는 것 같은 생각이 든다.
2. SS테이블과 LSM트리
(New) 해시테이블은 메모리에 저장해야하므로 키가 너무 많으면 문제가된다. 무작위 접근이 많이 필요하고 가득찼을 때 확장비용이 비싸기 때문. 또한 해시 테이블은 범위 질의(range query)에 효율적이지 않다. 키를 정렬하여 이를 보완한 것이 정렬된 문자 테이블(Sorted String Table)이다. 세그멘트 병합은 병합정렬과 비슷하다(다음 그림)
(Difficulty) 그리고 이 SS테이블과 memtable(쓰기가 들어오면 인메모리 균형트리 데이터구조?)의 동작의 단점으로 memtable의 가장 최신 쓰기가 손실되어 분리된 로그를 디스크 상에 유지하기 위하여 LSM(log-structed Merge Tree)가 나왔다는데 memtable에서 이해가 멈췄다....
데이터 웨어하우스(Data Warehouse)는 분석가들이 OLTP 작업에 영향을 주지 않고 마음껏 질의할 수 있는 개별 데이터베이스이며, OLTP 시스템에 있는 데이터의 읽기 전용 복사본이다.
솔직히 이 단원을 보기 전까지는 웹어플리케이션에서 발생하는 데이터에 대한 경험이 다소 적었기 때문에 OLTP와 OLAP에 대한 특별한 구분점을 찾지 못하였다. 하지만 OLTP 시스템 자체가 비즈니스 데이터 처리(Ex 전자 상거래)를 위해 즉 서비스 운영을 위해 만들어진 본래의 목적을 가지고 있다면, 분석을 그 자체에서 수행한다는 것은 매우 위험한 일임을 이제야 깨닫게 되었다. 따라서 이를 "복제"하여 데이터의 복사본을 가지고 분석을 수행해야함을 이해할 수 있었고, 또한 분석이라는 쿼리 자체의 특성 예를 들면 일부 컬럼을 가져오고 대량의 행을 가져오는 등의 특성에 필요한 데이터베이스의 설계가 필요한 점을 이해할 수 있었다.
(Amendment) 스타스키마(star schema) 다음 databrick 블로그의 인용문구로 대체!
스타 스키마는 데이터베이스에서 데이터를 정리하는 데 사용하는 다차원적 데이터 모델로, 쉽게 이해하고 분석할 수 있습니다. 스타 스키마는 데이터 웨어하우스, 데이터베이스, 데이터 마트 등의 툴에 적용할 수 있습니다. 스타 스키마는 대규모 데이터 세트에 대한 쿼리를 최적화하도록 설계되었습니다. Ralph Kimball이 1990년대에 도입한 스타 스키마는 반복적 비즈니스 정의의 복제를 줄여 데이터 웨어하우스에서 데이터를 빠르게 집계하고 필터링하도록 지원하므로 데이터 저장, 내역 관리, 데이터 업데이트에 효율적입니다. https://www.databricks.com/kr/glossary/star-schema
5. 컬럼지향 데이터베이스
(New) 대부분의 OLTP는 로우 지향의 방식으로 데이터를 배치. 문서 데이터와비비슷하며, 컬럼 지향 저장소는 칼럼 별로 모든 값을 함께 저장함. 또한 압축에 능함!!
특히, 나는 Pandas라는 모듈을 자주 사용하곤 하는데 이 문단에서 Pandas의 자료형이 생각났다. 해당 모듈에서는 DataFame이라는 행열 구조의 matrix와 Series라는 열구조 2가지의 데이터 자료형을 선언해놓았다. 왜 하필 행 구조가 아닌 열구조인 Series로 선언했을까 고민했을 때 얼핏 보았던, 분석은 컬럼단위로 진행된다는 이 공감이 가서 그렇게 이해했는데 이게 OLAP의 특성과 비슷하다고 생각했다.
6. 마무리
초반에는 지끈지끈 했지만 데이터베이스의 저장과 검색 관점에서 차근히 풀어가는 책의 전개방식이 되게 좋았다. 발생 -> 문제 -> 해결 -> 발전으로 이루어지는 데이터베이스의 발전 방향과 특히 데이터 분석 쪽에 이렇게 연결되어 있는 (책 발간당시는 꽤나 과거) 자료를 이제야 찾다니 그것도 흥미로웠다. 생각보다 어플리케이션 분석은 유래가 오래되었고 이를 잡마켓 수면위로 올라온지 얼마안된 것 뿐이구나 라고 생각했다
대부분의 데이터분석의 자료의 출처는 관계형 데이터베이스(RDB)를 말합니다. 정형데이터를 관리할 수 있는 Standard로 여겨졌고 실제로도 Oracle을 필두로한 데이터베이스 시스템이 과거 주류를 차지했습니다. 하지만 RDB의 정규화의 특징으로 나타나는 문제들이 발생할 수 있고 그에 따라 파생된 NoSQL 데이터 모델들이 등장했습니다. 이번 글에서는 데이터 모델의 역사와 종류 그리고 어플리케이션을 설계할 때 있어서 어떤 데이터 모델을 선택해야하는지에 대한 근거를 알아보도록 하겠습니다. 본 글에서는 New, Difficulty, Amendment 형식에 따라 작성하겠습니다.
1. 관계형 데이터베이스
관계형 데이터베이스(RDB)는 1980년대부터 약 30년간 주류를 이뤄왔습니다. 트랜잭션(transection)는 데이터베이스의 상태를 변경시키는 작업단위로, 원자성(Atomicity), 일관성(Consistency), 격리성(Isolation), 지속성(Durability) 의 ACID의 개념을 중심으로한 특징을 가지고 있으며 다음 링크에 잘 설명되어있습니다.
비즈니스 데이터 처리에 중점을 둔 RDB가 장기간 집권하였습니다. 반면, 컴퓨터를 더 다양한 목적으로 사용함에 따라 쓰기 확장성, 특수 질의, 동적이고 풍부한 표현력을 가진 데이터베이스 니즈에 따라 2010년 NoSQL의 탄생이 이루어졌습니다. 다음은 링크드인을 예시로하는 링크드인 예시로 보는 관계형과 문서형 DB의 구조 차이입니다.
(좌) RDB 의 구조 / (우) 문서형 DB의 구조
3. 문서형 데이터베이스
관계형 데이터베이스의 Schema는 엄격하지만 또한 성능의 저하도 일으키는 문제를 가지고 있습니다. 예컨데 ALTER TABLE을 통한 스키마 변경을 위해서는 테이블 사용을 중단해야하는 등의 이슈가 있습니다. 이를 대안으로 가져온 Schemaless한 구조가 NoSQL이였고 Elasticc Search 가 대표적인 서비스로 Kibana는 이와 호환되는 시각화 툴 입니다.
EK의 파이프라인 흐름
(Amendment) 실제로현대에는 관계형 데이터베이스와 문서형 데이터베이스의 혼합이 이루어지고 있으며, 종종 프로젝트 주제로 나오는 starbuck 데이터에서 Table안에 JSON 형식을 가지고 있는 것이 생각났습니다. 또한 빅쿼리의 구조체(Structure)도 이런 일환 중 하나일까 생각이 들었습니다.
데이터를 위한 질의 언어 질의 언어는 SQL와 같은 선언형 질의 언어와 흔히 말하는 프로그래밍과 유사한 명령형 코드로 나눌 수 있습니다. 명령어는 특정 순서로 연산을 하게끔 구체적으로 지시합니다. Loop을 돌리며 조건을 만족하는지 판단하고 추가 Loop를 지속하거나 중단하는 등의 분기점을 나눕니다. 반면 선언형 질의언어에서는 방법이 아닌 알고자하는 패턴에 대해서 기술하게 됩니다. 다음은 선언형 질의언어의 예시인 SQL 의 문법 구조입니다.
SELECT {컬럼}, {집계함수}
FROM {테이블}
WHERE {조건}
GROUP BY {컬럼}
이 점에서 SQL이 LLM의 자연어 질의와 비슷하다고 생각했습니다. 두 질의언어 모두 구체적인 명령이나 절차에 대해서 명시하지 않으며 상징적으로 선언하며 그 내부의 로직을 LLM이나 쿼리최적화에 맡긴다는 점이 공통적이였기 때문입니다. 또한, 웹에서 CSS 선택자(selector), XPATH 표현식 역시 선언형 질의언어라는 형식이라는 것이 재미있었네요.
4. 그래프 데이터베이스
그래프 데이터 예시: https://www.gov-ncloud.com/marketplace/AgensGraph
어플리케이션이 주로 일대다 관계이거나 레코드 간에 관계가 없다면 문서 모델이 적합 할 것입니다. 하지만 다대다 관계가 일반적인 소셜네트워크와 같은 경우면 그래프형 모델링이 더 자연스럽다고 할 수 있겠습니다. 그래프는 Vertex(정점 혹은 노드, 엔터티라고 불림)과 Edge(간선 혹은 관계)의 개념을 중심으로 하는 모델입니다. 예를 들어 자동차 네비게이션과 같이 도로 네트워크에서 두 지점간 최단 경로를 검색하는 등의 동작이 그래프 모델의 활용 방법이 될 수 있으며 그래프의 장점은 동종 데이터에 국한되지 않는다는 점입니다.
Neo4j 의 핵심개념은 노드(Node), 관계(Relationship), 속성(Properties), 라벨(Label)등으로 이루어져있으며, Cypher 쿼리 언어로 노드와 관계를 탐색하고 조작합니다. 대표적으로 Cypher 쿼리 언어의 코드는 다음과 같습니다.
1. 노드 생성
CREATE (n:Person {name: '홍길동', age: 30})
2. 관계 생성
MATCH (a:Person {name: '홍길동'}), (b:Company {name: 'ABC기업'}) CREATE (a)-[:WORKS_AT]->(b)
3. 데이터 조회
MATCH (n:Person)-[:FRIEND_OF]->(friend) WHERE n.name = '홍길동' RETURN friend.name
4. 데이터 업데이트
MATCH (n:Person {name: '홍길동'}) SET n.age = 31
5. 노드 및 관계 삭제
MATCH (n:Person {name: '홍길동'}) DETACH DELETE n
5. 데이터 모델의 차이점
관계형 데이터베이스
문서형 데이터베이스
그래프 데이터베이스
핵심키워드
SQL, 정규화, 테이블, 관계
JSON, 비정형 데이터, Schemaless
Vertex, Edge
장점
강력한 데이터 무결성, 복잡한 쿼리(SQL) 가능, 데이터 구조가 명확함
유연한 스키마, 직관적인 데이터 저장 가능, 수평 확장 용이
복잡한 관계(N:N) 데이터 빠르게 탐색, 네트워크 분석
단점
스키마 변경 어려움, 대규모 데이터 처리 시 성능 저하
데이터 중복 가능성, N:1 관계 적합하지 않음
대규모 데이터셋에서 성능 튜닝 필요
사용 예시
금융 시스템, 전통적인 웹 어플리케이션 백엔드(MySQL)
콘텐츠 관리 시스템, 로그 및 이벤트 데이터, 전자상거래(MongoDB)
추천시스템, 지식 그래프
종합적으로 각 데이터 모델을 살펴보니 어플리케이션의 목적에 따라 데이터 모델을 선택해야하는 점을 명확히 할 수 있었습니다. 고전적인 비즈니스 데이터 처리에는 관계형 데이터베이스를 컨텐츠 보관과 schemaless한 빠른 저장은 문서형 데이터 베이스, 다대다 관계를 염두에 둔 처리는 그래프 데이터베이스를 선택해야할 것입니다. 모호한 데이터 모델들에 대해서 이해할 수 있는 과목이였고, 물론 그래프 데이터베이스를 직접 마주한 적은 없어서 모호한 면이 있었지만 재미있게 읽었습니다.
해당 카테고리와 글은 데이터 중심의 어플리케이션 설계 책을 Pair reading하는 스터디의 결과물을 저장합니다. 사실 데이터라는 말에 혹해서 선택한 책이지만 백엔드 관점에서 이상적인 설계가 무엇인지 다루는 책이긴 합니다. 그럼에도 불구하고 한번 읽어보려고 용기있게 스터디를 모았습니다. 해당 스터디는 다음 템플릿을 이용해 매주 작성할 예정입니다.
1. 스터디 방안
모집인원: 최대 10명
기간
매주 약 chapter 1개 분량( 40 ~ 60 page)
Part1: 2025. 02. 09(일) ~ 2025.03.02(일) / 총 4주
Part2: 2025. 03. 09(일) ~ 2025.04.06(일) / 총 5주
Part3: 2025. 04. 13(일) ~ 2025.04.27(일) / 총 3주
진행방식
매 주 1단원씩 책을 읽고 다음 템플릿(NDA)를 이용하여 본인의 블로그, 노션, 줄글로 주차별 스레드 등에 작성합니다.
새롭게 알게된 점(New)
어려웠거나 이해하지 못한 부분(Difficulty)
추가 내용(Amendment): 학습이 도움이 되었던 블로그, 유튭, 사례 등
매주 일요일 22시에 허들로 모셔 학습에 대한 간단한 talk을 합니다. 30분정도?
2. 본문
일단 본인은 CS를 그냥 아는 데이터 분석가임을 밝힙니다. 그럼에도 불구하고 CS지식을 읽는데 그렇게 어려움을 느끼진 않습니다. 하지만 본 책을 읽는데는 확실히 기초지식이 떨어지기 때문에 용어와 흥미로운 레퍼런스 위주로 찾아보면서 꼬리 학습을 진행할 예정입니다.
Part1는 데이터 시스템의 기초로 Chatper 1은 신뢰할 수 있고 확장 가능하며 유지보수하기 쉬운 어플리케이션 이라는 거창한 제목으로 시작합니다. 마지 완벽한 이상향을 찾는 것 같지만 그래도 이상향을 추구해야 남는 쪼가리라도 이쁜 것이니 한번 살펴보려고합니다. 여기서 말하고자하는 데이터 시스템의 3가지 요소는 신뢰성(Reliability), 확장성(Scalability), 유지보수성(Maintainability) 3가지 입니다.
3. New
메시지 큐(Messae Queue): 큐(Queue)를 이용해서 메세지를 전달하는 시스템이며 메시지 지향 미들웨어(MOM)을 구현한 시스템이다. 라고 합니다. 근데 솔직히 API와 구별점을 잘 못찾겠어서 물어봤습니다.
메시지 큐(Message Queue)
API
정의
비동기적인 메시지를 주고 받을 수 있는 큐 시스템
한 시스템이 다른 시스템의 기능을 호출할 수 있도록 정의된 인터페이스
주요 특징
메시지를 임시 저장하고 필요한 시점에 소비 가능
실시간 요청 - 응답 방식으로 동작
예시
이메일 전송 요청 -> 메시지 큐에 저장 -> 이메일 서버가 가서 처리
사용자가 웹 사이트에서 버튼 클릭 -> 서버에 API 요청 전송 -> 응답 반환
둘이 동등 비교하는 항목은 아닌 것 같은데 가장 핵심적인 부분은 동기 & 비동기 시스템이지 않을까 라고 생각했습니다. Kafka 와 같은 소프트웨어가 메시지를 저장하고 처리하는 브로커의 대표명사인 것 같습니다.
Core Components of a Message Queue
4. Difficulty
이번 챕터에서 흥미로우면서도 명확하게 이해하지못 한 것은 확장성 단원의 부하기술하기 - 트위터 사례입니다.
트윗 작성과 홈 타임라인의 처리를 위한 기존 레거시 구조는 다음과 같다고 합니다.
1. 트윗 작성은 새로운 트윗 전역 컬렉션에 삽입한다. 사용자가 자신의 홈 타임라인을 요청하면 팔로우하는 모든 사람을 찾고, 이 사람들의 모든 트윗을 찾아서 시간순으로 정렬해서 합친다. 그럼 그림 1-2와 같은 관계형 데이터베이스 에서는 다음과 같이 질의를 작성한다.
2. 각 수신 사용자용 트윗 우편함처럼 개별 사용자의 홈 타임라인 캐시를 유지한다.(그림 1-3 참고) 사용자가 트윗을 작성하면 해당 사용자를 팔로우하는 사람들을 모두 찾고 팔로워 각자의 홈 타임라인 캐시에 새로운 트윗을 삽입한다. 그러면 홈 타임라인의 읽기요청은 요청 결과를 미리 계산했기 때문이 비용이 저렴하다.
하기 문단은 책의 해설을 보고 제가 생각한 내용입니다.
위 내용을 보면 결국 트위터는 1,2번을 혼합한(Hybrid) 구조로 만들었다고 합니다. 생각해보건데 1번 지문에서 팔로우하는 모든 사람을 찾고 부분이 full scan이며, 시간순으로 정렬한다는 점 시간복잡도 관점에서 성능이 떨어지는 요인에 기인하지 않았을까 생각이 들긴합니다. 1번은 홈타임라인을 보는 시점에 부하가 많고 2번은 트위터를 쓰는 시점에 부하가 많으므로, 팔로워가 매우 많은 소수 사용자들은 1번을 이용해 보는 시점에 리소스를 쓰고(수많은 팔로워가 한번에 보진 않을거고 시점을 나눠서 타임라인을 볼꺼니까?) 그리고 대부분의 사용자들은 팔로워가 적으니까 2번처럼 쓰는 시점에 부하를 높혀 상호보완적으로 하지 않았을까 라는 생각이 들었습니다.
5. Amendement
- 샌드박스(Sandbox): 라이브 환경에 영향을 미치지않고 소프트웨어나 어플리케이션을 테스트하고 개발할 수 있는 제어된 환경. 번역 그대로는 나무나 플라스틱으로 만들어진 모래가 담긴 공간이며 간이 놀이터라는 의미를 담고 소프트웨어 쪽에서 사용되는 듯.
흔히 정부사업에서 (규제) 샌드박스라는 단어가 등장하는데, 이는 특정 산업의 육성을 위해 일정구간 규제를 면제하거나 유예하는 것을 의미함. 토스는 "선불전자지급수단으로 상품 구매 시 결제부족분에 대한 소액후불 결제 서비스"의 서비스명으로 규제 샌드박스를 지정받고 성과 낸 경험이 있음
이번 글은 슬랙 기반 커뮤너티에서 참여자들에게 독려의 CRM 메세지를 보낸 경험과 커뮤너티 안의 게임채널에서 방문알람 봇을 만든 사례를 작성합니다. CS에 대한 개념이 살짝 필요하긴 하지만 기본적인 API 개념과 파이썬을 활용하여 쉽게 만들어볼 수 있는 사례라서 API를 제공하는 커뮤너티 어플리케이션에서 유용하게 쓰는데 도움이 되길 바랍니다!
1. 개요
필자는 개발자의 글쓰기 모임인 글또10기에 참여하고 있으며 또한 운영진으로 활동하고 있다. 아무래도 개발자 기반의 커뮤니티다 보니까 글쓰는 활동이나 내부 커뮤너티 활동들을 봇을 이용해서 활용할 기회가 많다. 예를 들면, 글 제출을 한다던지 혹은 제출된 글에 대해서 LLM으로 피드백을 해준다던지 자동화가 되어 있는 기능들이 많다. 이번 글에서는 Customer Relational Managment(a.k.a. CRM) 운영진의 일환으로 설날 맞이 보낸 CRM 메세지와 게임채널에서 마인크래프트를 이용한 서버를 운영하고 출석체크 봇을 만든 경험을 남기고자 한다.
2. 글또 CRM 메세지 보내기
2.1. CRM 메시지 기획하기
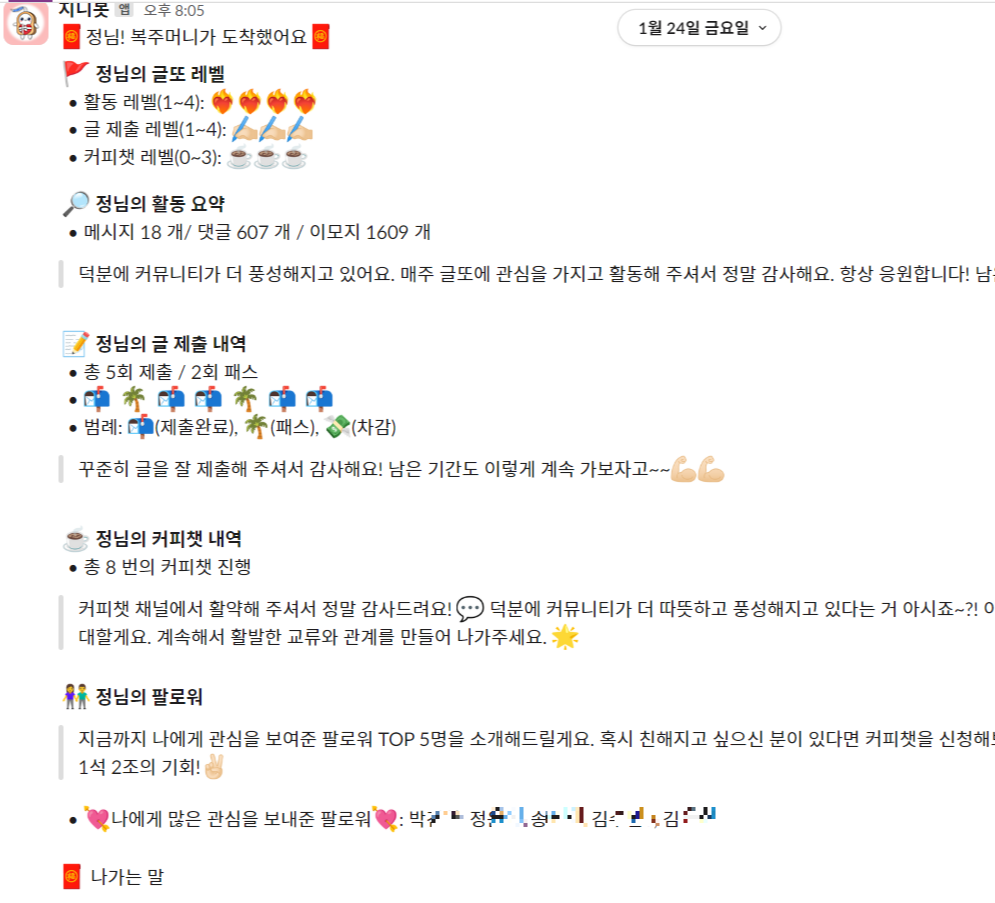
우리의 커뮤너티는 글쓰기를 주제로 약 4-6개월간 지속되는 활동으로 그 기간동안 활동한 내역을 집계하면 재밌는 얘기가 많이 나온다. 글또에서는 CRM 봇인지니 봇이 비정기적으로 지금까지의 활동내역을 보여주고 Activation을 넛지하는 전통(?)이 있다. 지난 기수도 역시 소소하게 이런 메세지를 보냈었고 반응이 되게 좋았었다. 아래는 이번기수에 내가 받은(사실 내가 보낸) 메세지이다.
10기 실제로 보낸(그리고 내가 받은) 메시지
역시 10기에도 보내자고 얘기가 계속 나왔고 결국 설날에 맞춰 보내기로 하였다. 내가 CRM 팀으로 이전한 건 이번이 처음이었기 때문에 추상적으로 어떻게 하겠다는 감은 있어도 실제로 해본적은 없기 때문에 좀 더 명확하게 이 프로세스를 전수 받고자 자처하여 메세지 봇을 만드는데 지원하였다. 사실 메세지를 보내는 시스템은 구축이 되어있었다. CRM 팀이 처음인 나는 지니봇이 작동하는 프로세스를 명확하게 하고 팀원들에게 공유하면 좋겠다고 생각했고 figjam을 이용해서 다음과 같이 정리했다. 참고로 우리의 지니봇은 주로 커뮤너티에서 전달하는 쿠폰이나 개인화 메세지에 초점을 맞춰 전달하고 있다.
이 과정에 크게는 3가지의 단계가 있는데
(데이터 마트 구축): 기존 또봇이 수집한 데이터 Log를 기반으로 참여자들의 글 제출, 메시지, 스레드 댓글, 이모지의 데이터를 집계하여 Data Mart를 만드는 과정
(지표 생성) 정보를 가지고 활동, 글, 커피챗 레벨을 지표로 만들고 친한 사람(팔로우)을 정의하는 과정
(메시지 전송) 참여자의 정보를 토대로 총합된 1,2의 정보를 불러와 각자의 지표에 맞춰 슬랙 봇으로 전송하는 과정
각자의 R&R이 나뉘고 나의 역할인 메시지 전송에서 작업을 시작했다. 이는 동민님의 Github에 잘 정리되어 있어서 답습하기 편했다. 하지만, 지니 봇은 특정 이벤트에만 작동시키는 경우가 많기 때문에 CRM 팀에서도 자주 사용하는 스크립트는 아니다. 따라서, 먼저 이를 파악하기 위해 동민님의 Github 레포를 뜯기 시작했다.
여기서 자주 사용하는 script는 /core/bigquery.py로 글또의 데이터는 빅쿼리에 적재되기 때문에 데이터를 저장하고 불러오는 등에 대한 메소드가 구현되어 있다. 빅쿼리와 슬랙을 주고 받는 기능에 대하여 개념적으로는 알지만 희미해서 새롭게 스크립트(message_basic.py)를 만들었다.
'''
genie봇이 메세지를 보내는 기본기능을 정의합니다. token은 관리자 문의
해당 스크립트를 실행하면 번호로 선택하여 실행하며, 기능을 수행할 대상에 대한 정보(user_id 혹은 스레드정보)를 전달해야합니다.
'''
import sys
import os
print(sys.version)
from slack_sdk import WebClient
from slack_sdk.errors import SlackApiError
from core.bigquery import BigqueryProcessor
bigquery_client = BigqueryProcessor(
env_name="GOOGLE_APPLICATION_CREDENTIALS", database_id="geultto_10th"
)
SLACK_BOT_TOKEN = os.getenv("SLACK_BOT_TOKEN") # 윈도우 로컬 - 시스템 - 환경변수에 저장
USER_ID = "" # 메시지를 보낼 대상의 Slack User ID
#하기 두개의 인자는 스레드의 링크복사 URL에 정보가 저장되어있음
URL = ''# 개인정보 이슈 삭제
URL_LIST = URL.split('/')
CHANNEL_ID = URL_LIST[4] # 채널 ID
THREAD_TS = URL_LIST[5][1:-7] + '.' + URL_LIST[5][-7:] # 스레드 메시지의 timestamp
# WebClient 초기화
client = WebClient(token=SLACK_BOT_TOKEN)
def send_message_to_user(user_id, message):
'''
Slack 메세지 전송 함수
'''
try:
response = client.chat_postMessage(
channel=user_id,
text=message
)
# print(f"메시지가 성공적으로 전송되었습니다: {response['ts']}")
return response['ts']
except SlackApiError as e:
print(f"오류 발생: {e.response['error']}")
def send_reply_to_thread(channel_id, thread_ts, message):
'''
스레드에 댓글 남기는 함수
'''
try:
response = client.chat_postMessage(
channel=channel_id,
text=message,
thread_ts=thread_ts
)
print(f"스레드에 댓글이 성공적으로 전송되었습니다: {response['ts']}")
except SlackApiError as e:
print(f"오류 발생: {e.response['error']}")
def get_bigquery(query):
'''
단순 빅쿼리 조회용
'''
try:
result = bigquery_client.run_query_to_dataframe(query)
print('Big query 조회 성공')
# print(result)
return result
except Exception as e:
print(f'Bigquery 오류 발생 {e}')
def send_bigquery_to_slack(user_id, query):
data = get_bigquery(query)
if data:
for row in data:
message = f'Bigquery 데이터: {row}'
send_message_to_user(user_id,message)
else:
print('전송할 데이터가 없습니다.')
# 메뉴 기반 실행
if __name__ == "__main__":
print("실행할 기능을 선택하세요:")
print("1. 사용자에게 메시지 보내기")
print("2. 스레드에 댓글 달기")
print("3. Bigquery 데이터 조회")
print("4. Bigquery 데이터 사용하여 사용자에게 전송")
choice = input("번호를 입력하세요: ")
if choice == "1":
message = "안녕하세요! Slack Bot에서 보낸 메시지입니다."
send_message_to_user(USER_ID, message)
elif choice == "2":
message = "스레드에 댓글 달기 테스트중입니다."
send_reply_to_thread(CHANNEL_ID, THREAD_TS, message)
elif choice == "3":
query = 'SELECT * FROM geultto.geultto_10th.user_super_mart LIMIT 1;'
get_bigquery(query)
elif choice == "4":
query = 'SELECT * FROM geultto.geultto_10th.user_super_mart LIMIT 1;'
send_bigquery_to_slack(USER_ID, query)
else:
print("잘못된 입력입니다. 다시 실행해주세요.")
2.2. 사전 테스트 진행
최종적으로 우리가 보낼 메세지는 총 639명을 대상으로한 Direct Message이다. 사실 이정도의 많은 사람들에게 메세지를 보내는게 부담이여서 먼저 운영진 34명을 대상으로 설 일주일 전 테스트를 진행했다. 초안의 메세지는 다음과 같고 몇 가지 문제를 발견할 수 있었다.
모바일 기준 메시지, 확실히 개행이 빡빡하다.
컨텐츠 문제
들여쓰기 내여쓰기가 들쭉 날쭉함
요약하여 쓸 수 있는 내용이 서술형으로 작성 됨
1번을 고민해보자면 슬랙은 멀티플랫폼이기 때문에 데스크톱, 모바일에서의 개행이 다르다는 점이다. 특히, 사람들에게 보내는 메세지가 처음 설계에서는 짧지 않았기 때문에 불릿포인트는 들여쓰기가, 줄글은 내어쓰기가 되어 가독성이 좋지 않았다.
2번은 불릿 포인트는 개조식, 그 밖은 서술형인 형식이 무너진 탓이였다. 되도록 불릿 포인트는 요약하여 작성하고 줄글은 문단마다 맨 뒤로 빼는 한편 "인용" Syntax를 이용해서 대화형임을 강조했다. CRM 메시지이기 때문에 사람마다 줄글이 미묘하게 다르기 때문에 이를 맞추려고 말 그대로 메세지를 2시간정도 "깍았다". 밑에 메세지가 최종본인데 나름 깔끔해졌다.(활동요약 개행이 좀 거슬린다.)
정리된 메시지 최종본
두 번째로는 테크적인 관점인데, 운영진 30명 정도에 보내는 정도야 별 문제 없었지만, 639명에게 보내게 되면 꽤나 골치아픈 경우의 수가 떠올랐다.
slack api 의 초당 메세지 limit으로 인한 끊김
누구에게 어떤 메세지를 보냈다는 로그
너무 느린 속도..
1번은 API TOKEN 발급받은 동민님께 확인 받았다. 제일 좋은 tier라고 하셔서 문제는 없을 거라고 하셨고 나중에 확인해본결과 3 Tier 였다. 실제로 보내는 것도 문제가 없었긴 했는데 살짝 아슬한 정도가 아닐까 싶다. 다음에 체크해볼 것!
2번은 혹여나 전송 시 에러가 날 수 있는 상황을 가정한다면, 누구까지 보냈는가가 중요했다. 그래야 받지 못한 사람부터 다시 시작할 수 있기 때문이다. 게다가 CRM 메세지 답게 모든 사람들이 다양한 경우의 수의 메시지를 받을 수 있기 때문에 확인 수단이 필요했다. 그래서 loop안에 받은사람, 메세지 내용, 해당 스레드의 ts식별자등을 저장한 csv파일을 로컬에 저장하는 로직을 추가했다.
#코드 중 일부
#for문
cnt += 1
df_temp = pd.DataFrame({'name':name_list,'text':text_list,'ts':ts_list})
if cnt % 100 == 0:
time.sleep(1)
print(f'{cnt}명, {row[1]}까지 전달완료')
time_record = time.strftime("%Y%m%d_%H%M%S", time.localtime(time.time()))
pd.concat([df_sended,df_temp]).to_csv(f'./history/message_sended_{time_record}.csv', encoding = 'utf-8-sig')
print(f'최종 {cnt}명 전달완료')
end = time.time()
print(round(end - start), '초 소요됨')
3번은 사실 해결못한 부분이기도 했는데, 속도가 너-무 느렸다. 빅쿼리에서 데이터를 불러오는건 그렇다고 쳐도 가져온 데이터를 Pandas DataFrame을 .iterrow()로 접근하여 루프를 돌리는데 운영진 34명에게는 23초였으니 639명은 5분이 넘어갈께 뻔했다. 병렬식으로 보낼 수도 있을 것 같은데 굳이 지금 프로세스에서 바꾸고 싶지 않았다. 잘 작동하니까.. 🤣 그리고 이걸 깨달을 때 쯤이면 이미 보내기로한 due date 직전이였다.
그정도까진 아니긴해 ~
결국 6분에 걸쳐 모든 사람들에게 메시지는 정상적으로 전송되었지만 후문으로는 왜 비동기식으로 하지 않았는가 에 대한 물음이 있었다고 한다 ㅋ_ㅎ (역시 개발자분들 ! 다음엔 그렇게 해볼게요) 사실 비동기식 처리 방법에 대해서 얼마안된 수민님의 글을 읽은 적이 있는데 사람은 망각의 동물이 맞나보다.
설 전날 결국 메시지를 보내 마무리 했다. 배포하는 날 기도하는 심정이 이런걸까? 금요일날 보내기 위해서 점심부터 계속 에러는 없을까 그 짤막한 코드를 보면서 계속 체크해봤다. 점점 쌓이는 지니봇의 DM..
6분은 좀 너무하긴 하네요
정확히 저녁 8시에 보내기 시작한 봇은 무리없이 6분간 순차 전송을 마무리하였고 사람들의 반응도 좋았어서, CRM팀으로서 뿌듯함을 느꼈다.
3. 갑자기 마인크래프트크요?
3.1. 마크 활동 시작
슬랙 봇에 이어지는 이야기인데, 서론은 이렇다. 갑자기 어떤분의 권유로 마인크래프트가 흥하기 시작했다. 그것도 설연휴에. 그렇게 정수님은 GCP을 가입하신 무료 크레딧 $400달러로 서버를 팠고 약 5 일차 정도 재밌게 진행했다. 근데 마인크래프트에서는 채팅기능에 더하여 사람이 접속하는 정보나 업적달성, 죽음 표시 등이 표기된다. 어 이거 데이터잖아? 하는 생각이 들었고 GCP 내부에 접근하면 LLM을 이용해서 인게임에서 마인크래프트 공략 등을 물어보는 세팅도 가능할 것 같아서 정수님께 문의 했다.
그렇다 나는 말벌 아니 데이터 아저씨다..호다닥 🏃♂️
/Logs 파일을 확인해보니 날짜별로 분할되어있는 파일과 최신 log 2가지가 존재했다. 현재 기록들은 latest.log에 실시간으로 적히고 일정 용량이 차면 날짜별로 압축파일 .gz 파일로 저장되는 모양이였다.
Logs 디렉토리의 파일들
여기서 재밌는 생각이 난게 채팅기록을 가지고 있으니 이걸 가지고 3-4일동안 진행된 정보를 요약하면 재밌겠다는 생각이 들었다. 게임채널이지만 시간이 나지 못해 참여 못한 사람들에게 안의 상황을 공유하면서 공감대를 키우고 유입 유도를 하는 한편, 기존 참여자들에겐 정보 요약을 통해 추억을 회상하는 넛지를 줄 수 있을 것 같아서 날짜별로 로그를 이용해서 LLM 에 태웠다.
초기 요약은 깔끔하다
여기서 재밌는 이슈가 있는데, 채팅파일이 워낙 길다보니까 무료버전의 ChatGPT, Claude, 뤼튼(OPEN AI 기반이긴 하지만)에서 모두 텍스트 Length 초과로 거절당했다... 반면 Perplexity 와 Gemini는 토큰이 넉넉한지 요약은 해주더라. 결국 Gemini에게 요약하는 형식을 가지고 3일차 정도 밀어 넣어봤는데 Context Length 이슈로 3일차 정도 뒤에는 자기 멋대로 요약을 하기 시작했다... 아놔. 결국 마음편하게 ChatGPT를 다시 구독했다.
Context가 길어진 후, 응답 구조가 변경되었다.반응 감사해요 ~
좀 더 프롬프트를 깍고 일정하게 형식을 few shot해놓으면 퀄리티가 좋아지겠지만 그렇게 까지 시간을 쓰고 싶지 않았고 날짜도 5일차 정도 밖에 되지 않았기 때문에 간단하게 정리만 했다.
3.2 접속 알림 봇을 만들까?
어쩌다보니 마인크래프트 GCP 서버 관리까지 참여하고 있어서, 이 때를 틈타 CRM에서 했던 연장으로 간단하게 출석 체크 봇을 만들고 싶어졌다. 사실 생존게임이라는게 혼자하기보다는 누구랑 같이 할때 제일 재밌는거라 함께 하는게 젤 중요하다 생각했다. (그리고 2주정도 하다 말꺼니까) 그러던 중 문득 생각난 것이, 마인크래프트가 꽤나 API에 적극적이라, 실제로 인터넷 방송에서는 도네이션을 연결해서 스트리머에게 필요한 물품을 준다던가 갑자기 점프를 시킨다더가 즉사를 시킨다던가 하는 식으로 재미를 더하고 있었던 장면이 생각났다.
위 내용을 조합해서 2번을 만들면 아주 쉽게 다음과 같이 만들 수 있다. 마인크래프트와 파이썬 스크립트의 위치는 동일한 GCP 이기 때문에 Localhost를 이용해서 어렵지 않게 서버정보를 불러올 수 있다. 이렇게 정보를 가져올 수 있다는걸 확인했으니, 이제 슬랙 봇 api를 이용해서 보내기만 하면된다.
import os
import time
import requests
import json
from mcstatus import JavaServer
# 🛠 환경변수에서 Slack Bot Token 불러오기
SLACK_BOT_TOKEN = os.getenv("SLACK_BOT_TOKEN")
if not SLACK_BOT_TOKEN:
raise ValueError("❌ 환경변수 SLACK_BOT_TOKEN이 설정되지 않았습니다.")
# 🛠 Slack 설정
CHANNEL_ID = "C01XXXXXX"
THREAD_TS = "000000.00000" # 기존 메시지 thread_ts 값
# 🛠 마인크래프트 서버 설정
SERVER_IP = "127.0.0.1"
QUERY_PORT = 25565
server = JavaServer.lookup(f"{SERVER_IP}:{QUERY_PORT}")
# 🛠 ID → 이름 매핑 (등록되지 않은 경우 ID 그대로 출력)
player_name_map = {
"ID" : "이름"
}
# 🔄 이전 접속자 목록 저장
previous_players = set()
# 📌 Slack 스레드에 댓글 남기기
def send_slack_reply(message):
url = "https://slack.com/api/chat.postMessage"
headers = {"Authorization": f"Bearer {SLACK_BOT_TOKEN}", "Content-Type": "application/json"}
data = {
"channel": CHANNEL_ID,
"text": message,
"thread_ts": THREAD_TS # 기존 메시지의 스레드에 댓글 작성
}
response = requests.post(url, headers=headers, data=json.dumps(data))
response_data = response.json()
if response_data["ok"]:
print(f"✅ Slack 스레드에 댓글 작성 완료: {message}")
else:
print("❌ Slack 댓글 작성 실패:", response_data)
# 📌 서버 인원 체크 루프 실행
def monitor_minecraft_server():
global previous_players
print("🔄 마인크래프트 서버 접속 감지 시작...")
while True:
try:
# 서버 상태 가져오기
status = server.status()
current_players = set(player.name for player in status.players.sample) if status.players.sample else set()
# 🔹 새로운 플레이어 입장 확인
new_players = current_players - previous_players
left_players = previous_players - current_players
message_list = []
# ✅ 여러 명이 동시에 입장하면 한 번에 메시지 출력
if new_players:
joined_names = [player_name_map.get(player, player) for player in new_players]
joined_message = f"🎉 {', '.join(joined_names)} 님이 입장했습니다!"
message_list.append(joined_message)
# ✅ 여러 명이 동시에 퇴장하면 한 번에 메시지 출력
if left_players:
left_names = [player_name_map.get(player, player) for player in left_players]
left_message = f"👋 {', '.join(left_names)} 님이 퇴장했습니다!"
message_list.append(left_message)
# ✅ 현재 인원도 한 번만 출력
if message_list:
total_players = len(current_players)
message_list.append(f"🔹 현재 접속 인원: {total_players}명")
send_slack_reply("\n".join(message_list))
# 🔹 접속자 목록 업데이트
previous_players = current_players
except Exception as e:
print(f"❌ 서버 정보를 가져오는 중 오류 발생: {e}")
time.sleep(5)
# 🔥 실행
if __name__ == "__main__":
monitor_minecraft_server()
위 코드를 실행하여도 GCP SSH가 닫기면 떨어지기 때문에 screen을 이용해서 백그라운드에서도 돌게 만들었다.
# screen 생성
screen -S mc_slack_bot
# 파이썬 스크립트 실행
source /가상환경명/bin/activate
python monitor_sendmsg.py
# CTL + A , D를 통해 screen 빠져나오기
#스크린 확인(사용자 디렉토리 귀속)
screen -ls
완성!
4. 마무리
Slack API가 잘 되어있고 GCP같은 클라우드 환경도 언제든지 쉽게 접속할 수 있는 환경이라 쉽게 배웠다. 더불어 옆에 있는 개발자분들에게 물어가면서 배워가는 점도 한 몫하고, 아이디어만 있다면 ChatGPT 를 이용해서 코드 구현부분을 외주 줄 수 있다는 점도 좋은 것 같다. 최적화나 설계 부분에 대해서는 여전히 CS적인 지식이 필요하지만 짧게 짧게 Prototype을 만들고 구현하는 경험이 재미있었다. 예전에는 프로그램을 만들기 위해서 가능한 기능성이 높은 구조를 높게 잡고 하다보니 지치거나 포기하는 경우가 많았는데 이제 경험이 쌓이다보니 작은 단위로 Divide(&Validation) and Conquer 를 하는 개발도 익숙해진 것 같다. 남은 글또 기간이나 내 일에서도 SaaS 활용과 엔지니어링을 지속적으로 키워나가면 확실한 무기가 될 수 있을 것 같다.
흔히 데이터 분석가라는 공고의 많은 부분이 프로덕트 분석을 지향하고 A/B test 의 지식과 경험을 요합니다. 도대체 A/B test가 무엇이길래 이렇게 신봉되는 걸까요? 연구의 큰 종류인 관찰연구와 실험연구의 구분와 실험연구의 대표적인 방법인 RCT 그리고 온라인 환경에 이식된 온라인통제실험(OCE)의 흐름을 살펴보고 A/B test가 왜 중요해졌는지 알아보겠습니다.
1. 태초에 관찰과 실험이 있노라: 관찰연구
Grimes, D. A., & Schulz, K. F. (2002). An overview of clinical research: the lay of the land. The Lancet, 359(9300), 57–61. doi:10.1016/s0140-6736(02)07283-5
분석이라는 관점에서 개입유무에 따라 관찰연구(Observational Study)와 실험연구(Experimental Study) 가 존재합니다. 대부분의 분석은 집계로 부터 시작하고, SQL과 같은 쿼리문은 Descriptive하게 정보를 보는 것이 중점을 둡니다. 물론 그 과정에서 비즈니스에 적용할 수 있는 지표나 잘 정의된 문제를 보는 입장에서는 이만한 기술이 없죠. 덜 논쟁적(중요..)이고 우리는 그 정보를 가지고 어떻게 행동(Action)해야하는지 고민하면 됩니다. 집계된 데이터에 관심을 가지지 왜 이렇게 나왔는지에 대해서 논쟁하진 않거든요. 심플하고 간단하고 이해하기 쉬우니까요. 하지만 분석의 본질은 단순 집계만 머물지 않습니다.
우리는 관찰하고 인과관계를 밝혀내길 희망합니다. 관찰연구는 연구자 혹은 분석가가 직접적으로 개입하지 않고 자연스럽게 발생하는 데이터를 관찰하여 분석하는 연구 설계라고 하며, 피험자 혹은 연구 대상자에게 위해가 아주 적습니다. 흡연자와 건강 상태를 비교하는 연구, 웹사이트에서 사용자들이 자발적으로 클릭한 광고의 효과를 분석하는 경우가 해당됩니다. 이 관찰연구는 이미 주어진 데이터로 기술통계를 내거나 확인하는 연구이므로 이미 있는 데이터를 후향적(respective)으로 연구한다는 특징을 가지고 있습니다. 하지만 우리는 어떤 변화를 일으켜서 그 영향을 비교하고 싶은 것에 관심이 더 많습니다. "여기 버튼을 우측 하단으로 옮기면 어떨까?" , "만약 할인 쿠폰을 발행한다면 얼만큼 반응할까" 와 같은 관점 말입니다. 예를 들어 당근마켓의 사례를 보죠. 뱃지 획득 유무에 따른 잔존율의 상관관계를 밝혀 냈다고 합시다. 뱃지를 획득한 사람은 잔존율이 높아! 굉장히 합리적으로 들리는데요.
출처: Choi Bokyung, Medium, Simpson’s Paradox and Confounding
하지만 현실은 그렇게 녹록하지 않습니다. 상관관계를 방해하는 녀석이 있는데 이를 교란변수(Counfounding)이라고 합니다. 이게 모든 관찰연구의 한계의 근본인 녀석입니다. 아주 흉악한 녀석이죠. 우리는 교란변수를 제어(Control)하고 싶습니다. 하지만 두가지 문제가 있습니다.
먼저 교란변수는 측정되지 않는 경우가 많습니다. 회원가입할 때 성별, 나이, 전화번호부 등 마케팅 동의 다 하시나요? 애초에 데이터가 존재하지 않으면 제어하는 것이 어렵습니다. 두 번째 문제는 인과관계는 여러가지 요소가 뒤엉켜 껴안고 있어서 이거를 생선 살 발라내듯 발라내는 것이 어렵습니다. 이를 내생성 문제(Endogeneity problem)라고 합니다.
2. 교란변수 극복하기 - 인과추론(Casual Inference)
인과추론은 이 내생성 문제를 어떻게든 해결할려고 뜯어말리는 시어머니와 같습니다. 말 그대로 X-Y의 인과관계를 밝혀내는 방법입니다만, 관찰된 데이터를 가지고 교란변수를 통제하는 방법론(Ex. PS 매칭, 차분법) 등이 필수적으로 요구됩니다.인과추론은 멋진 이상향을 보여주지만 어려운 학문입니다.
그럼 교란변수에 우리는 손 들고 항복을 선언해야할까요? 그렇지 않습니다. 우리 잘생긴 피셔형님이 좋은 대책을 가져왔습니다. 바로 실험연구 중 무작위 대조실험입니다. 실험연구는 연구가 실험 대상을 처치에 따라 두 그룹으로 배정하여 결과를 비교하는 연구이며, 실험연구가 중요한 이유는 모든 변수를 통제(Control)하고 우리가 원하는 개입(Intervention)에 따른 영향을 분석할 수 있기 때문입니다. 임상시험은 대표적인 실험연구이자 무작위 대조 실험의 한 예시이며, 이를 차용하여 온라인에 적용하면 온라인 통제 실험(Online Controlled Experiment, OCE)라고 합니다.
임상시험에서 고혈압 약제를 투여한 그룹과 플라시보(Placebo)를 투여한 그룹 간의 혈압 개선 연구처럼 의학적 분야에서는 RCT(Random Clinical Trial) 라고 불리우며, 웹사이트 A/B 테스트에서 두 가지 페이지를 무작위로 보여주고 클릭율을 비교하는 연구는 OCE의 예시 라고 할 수 있겠습니다. 위 실험설계는 모두 나머지 모든 변수를 통제(Contol)하고 처치(독립변수)로 인한 결과(종속변수)에 관심이 있고 데이터를 전향적(Prospective)하게 수집하여 연구한다느 특징을 가지고 있습니다. 종합적으로 정리하자면 다음과 같습니다.
관찰연구
RCT(실험연구)
개입 여부
연구자가 직접 개입하지 않고 자연스러운 데이터 관찰
대조군과 실험군을 무작위로 할당 실험군에 개입
인과 관계 규명
어려움
가능
교란 변수 통제
교란변수 어려움, PSM 등을 통한 제어 방법 도입 必
무작위할당으로 교란변수를 통제 가능
윤리 문제
거의 없음
발생할 수 있음 (Ex 신약 개발)
실행 비용
비용이 적고 시간이 덜 소요
시간과 비용이 많이 듬
적용 예시
흡연이 건강에 미치는 영향
임상시험, 온라인 통제실험
4. 마무리
인과추론과 기존에 배웠던 지식을 합치면서 자연스럽게 Product Anlaysis 분야가 A/B test 집착하는 이유도 이해가 잘가게되었습니다. 실제로 저는 임상시험은 아니지만 공학대학에서 약 3년간 실험연구만 전공으로 했었기 때문에 이런 정리가 좀 더 와닿는 면이 있었습니다. 근본적으로 과학은 통제가능한 실험을 좋아하고 그 분야에 리소스를 많이 투여할 수 밖에 없는그만의 매력이 있는 것 같습니다.
A/B test는 아마 데이터 직무 분야에서 Gold Standard로 정말 오랫동안 영속될 것 같은 느낌이 듭니다. 반면 이런 OCE를 못하는 환경에서의 대안으로 인과추론이 역시 부상할 것이라는 것을 더 마음에 와닿게 되었습니다. 지식의 상아탑을 올라가려면 아마 꽤 오랜시간 저를 괴롭힐 것 같은데, 이미 한번 스터디를 하면서 완벽하게 이해하지 못했기 때문입니다. 국내에는 인과추론의 데이터과학 Youtube와 가짜연구소의 인과추론 스터디가 좋은 레퍼런스를 남겨주고 있는데, 더더 좋은 자료가 나올 것이라 믿고 확인하며 실업무에서 도입 사례에 대해서 연구해볼 가치가 있을 것 같네요. 그럼 다음에 깨달음의 언덕에 다다를때 쯤 다시 한번 포스팅 해보겠습니다. https://www.youtube.com/@causaldatascience
이번 글에서는 A/B 테스트를 비롯한 데이터 과학에서 자주 사용되는 신뢰구간이 등장한 이유를 알아봅니다. 또한, 신뢰구간의 t-분포 기반 방법과 부트스트래핑 기법을 비교하여 설명합니다. 부트스트래핑은 컴퓨터 자원을 활용한 현대적 방법으로, 데이터 과학에서 왜 중요한지를 알아봅시다.
1. 글목차
점추정의 한계와 구간 추정의 필요성
신뢰구간의 등장
현재 데이터과학에서 부트스트래핑의 중요성
2. 본문
2.1. 점추정의 한계와 구간 추정의 필요성
통계학의 기본은 모집단을 알아내는 방법론입니다. 하지만 모집단에 대한 전수조사가 불가능에 가깝기 때문에 표본을 가지고 모집단에 대한 특징 평균,표준편차를 구하는 것이 추론통계의 기초라고 하겠습니다 . 표본데이터로 모평균은 쉽게 구할 수 있는 법칙이 있는데 Law of Large Number 라는 대수의 법칙으로 표본 평균은 표본의 크기가 증가할수록 모평균에 수렴하는 경향을 나타낸다는 법칙입니다. 다음은 대수의 법칙을 확인하기 위하여 동전 뒤집기를 예시를 10000번 수행해가면서 평균이 0.5로 수렴하는 그래프입니다.
import random
import matplotlib.pyplot as plt
def law_of_large_numbers(n_trials):
heads_counts = []
proportions = []
for i in range(1, n_trials + 1):
flip_results = [random.randint(0, 1) for _ in range(i)] # 0: tails, 1: heads
heads_count = sum(flip_results)
heads_counts.append(heads_count)
proportions.append(heads_count / i)
plt.figure(figsize=(10, 6))
plt.plot(range(1, n_trials + 1), proportions)
plt.axhline(y=0.5, color='r', linestyle='--', label='Expected Proportion (0.5)')
plt.xlabel('Number of Trials')
plt.ylabel('Proportion of Heads')
plt.title('Law of Large Numbers Demonstration (Coin Flips)')
plt.legend()
plt.grid(True)
plt.show()
law_of_large_numbers(10000)
그런데 단순히 표본평균이 같다는 이유로 같은 분포라고 할 수 있을까? 라는게 구간 추정의 등장의 이유입니다. 데이터의 산포도(분산이나 표준편차)가 다르다면, 평균만으로는 데이터를 완전히 설명하기 어렵기 때문입니다. 구간 추정은 이러한 불확실성을 포함하여 데이터를 표현하는 방법론으로 등장하게 되었습니다. 다음은 두 평균이 비슷한 두 데이터가 산포도가 다른 예시입니다.
그렇다면 점추정된 평균을 단순히 제시하는 것보다 구간을 포함하여 표현하는게 더 Data Scientific한 방법론이라고 할 수 있겠습다. 그러면 구간을 잘 표현한다는 것은 무엇일까요? 무작위로 선택된 30명의 남성의 평균 키가 170이라고 해봅시다. 표본평균을 구했으니 구간을 포함하여 설명할 때, 남성은 0 cm ~ 200cm에 반드시 존재합니다. 라고한다면 이는 별로 좋은 표현방법이 아닐 것입니다. 따라서, 좀 더 "합리적인" 표현방법이 필요하게 되었습니다.
2.2. 신뢰구간의 등장
신뢰구간은 정규분포를 기반으로 계산되며, 이를 위해 Z-점수(Z-score)를 사용합니다. 전체 데이터의 95%정도만 설명한다고 하면 표준정규분포 Z score 를 기준으로 +- 1.96의 값에 해당하는 수치를 이용해서 신뢰구간 추정이 가능합니다.
만약 모표준편차를 안다면 다음식으로
모 표준편차를 모른다면 표본 표준편차를 가지고 대체하여 계산합니다.
코드로 구현하자면 다음과 같습니다.
import numpy as np
from scipy import stats
korean_men_heights = [
170, 172, 174, 168, 176, 175, 169, 171, 173, 177,
165, 180, 178, 174, 172, 173, 169, 168, 176, 175
]
# 표본 평균구하기
sample_mean = np.mean(korean_men_heights)
sample_std = np.std(korean_men_heights, ddof=1) # ddof=1 for sample std
# 데이터사이즈
n = len(korean_men_heights)
# 표준오차 구하기
standard_error = sample_std / np.sqrt(n)
# 95% 신뢰구간 구하기
confidence_level = 0.95
t_critical = stats.t.ppf((1 + confidence_level) / 2, df=n-1) # t critical value
margin_of_error = t_critical * standard_error
confidence_interval = (sample_mean - margin_of_error, sample_mean + margin_of_error)
# Print results
print("Point and Interval Estimation for Korean Men's Height:")
print(f"Sample Mean: {sample_mean:.2f} cm")
print(f"Sample Standard Deviation: {sample_std:.2f} cm")
print(f"Sample Size: {n}")
print(f"Standard Error: {standard_error:.2f} cm")
print(f"Margin of Error: {margin_of_error:.2f} cm")
print(f"95% Confidence Interval: ({confidence_interval[0]:.2f}, {confidence_interval[1]:.2f})")
'''
Point and Interval Estimation for Korean Men's Height:
Sample Mean: 172.75 cm
Sample Standard Deviation: 3.82 cm
Sample Size: 20
Standard Error: 0.85 cm
Margin of Error: 1.79 cm
95% Confidence Interval: (170.96, 174.54)
'''
결과적으로 신뢰구간 95%라는 뜻은 전체 모집단에서 100번 추출을 수행할 때 해당 통계량은 95번 신뢰구간에 들어온다는 뜻이다. 신뢰구간은 편리했지만 가정이 필요했습니다. 바로, 표본 데이터가 정규분포를 따르거나 충분히 큰 표본을 가지고 있어야만 계산이 가능하다는 가정이 필요했습니다. 이는 컴퓨터가 등장하기 이전의 상황이라고 할 수 있습니다. 컴퓨터파워가 높아진 현재는 부트스트래핑방법을 이용하여 신뢰구간을 구하기 시작했습니다.부트스태립(bootstrap)이란 '외부의 도움 없이 스스로'라는 사전적인 정의를 가진 방법론으로 표본 데이터에서 복원추출을 통해서 데이터셋을 생성하여 마치 모집단에 있을법 하지만 새로운 데이터셋을 만드는 방법론입니다. 대표적으로 Random Forest는 이 부트스트랩에 집계를 더한 배깅 방법으로 고안되었습니다.
자기의 일을 스스로하자!
절차는 다음과 같습니다.
데이터에서 복원추출 방식으로 크기 n인 표본을 뽑는다.(재표본추출)
재표본 추출한 표본에 대해서 평균을 구한다.
1~2번을 10000번 반복한다.
95% 신뢰구간을 구하기 위하여 10000개의 표본결과 분포 양쪽 끝 2.5%, 97.5%의 백분율을 구한다.
# 평균과 표준편차
sample_mean = np.mean(korean_men_heights)
sample_std = np.std(korean_men_heights, ddof=1) # ddof=1 for sample std
# 부트스트래핑 파라미터 정하기
n = len(korean_men_heights)
n_bootstraps = 10000
bootstrap_means = []
#부트스트래핑 시행
np.random.seed(42)
for _ in range(n_bootstraps):
bootstrap_sample = np.random.choice(korean_men_heights, size=n, replace=True)
bootstrap_means.append(np.mean(bootstrap_sample))
# 부트스트래핑으로 신뢰구간 구하기
confidence_level = 0.95
lower_bound = np.percentile(bootstrap_means, (1 - confidence_level) / 2 * 100) # 2.5%
upper_bound = np.percentile(bootstrap_means, (1 + confidence_level) / 2 * 100) # 97.5%
bootstrap_confidence_interval = (lower_bound, upper_bound)
# 결과출력
print("Bootstrap Confidence Interval for Korean Men's Height:")
print(f"Sample Mean: {sample_mean:.2f} cm")
print(f"Sample Standard Deviation: {sample_std:.2f} cm")
print(f"95% Confidence Interval (Bootstrap): ({bootstrap_confidence_interval[0]:.2f}, {bootstrap_confidence_interval[1]:.2f})")
'''
Bootstrap Confidence Interval for Korean Men's Height:
Sample Mean: 172.75 cm
Sample Standard Deviation: 3.82 cm
95% Confidence Interval (Bootstrap): (171.15, 174.35)
'''
t분포를 이용한 값과 부트스트래핑을 이용한 방법이 유사한 결과를 나타냄을 볼 수 있습니다.
2.3. 현대 데이터과학에서 부트스트래핑의 중요성
Product analyst 의 방법론 중 A/B test는 부트스트래핑의 혜택을 받은 방법 중 하나이다. 일반적으로 A/B test는 두 웹페이지의 방문 비율의 차이 등을 검정하는 경우가 많은데 비율의 차이가 항상 정규분포를 따르는 것은 아니며, 대부분 비대칭이거나 이항분포를 따르는 경우가 많습니다. 이처럼, 부트스트래핑은 데이터의 분포에 관계없이 적용가능하며, 복잡한 통계량에도 유연하게 사용할 수 있다는 점이 장점입니다. 여담으로 Seaborn 의 Error bar 튜토리얼을 보면 신뢰구간(c.i.)를 부트스트래핑으로 계산된다는 걸 확인할 수 있습니다.