1. 책 목차
- 6.1. k-최근접 이웃
- 6.1.1. 예제: 대출 연체 예측
- 6.1.2. 거리 지표
- 6.1.3. 원-핫인코더
- 6.1.4. 표준화(정규화, z점수)
- 6.1.5. k 선택하기
- 6.1.6. KNN 통한 피처 엔지니어링
2. 본문
머신러닝알고리즘을 설명할 때 나는 딱 2가지 알고리즘 중에 하나를 선택해서 설명을 시작한다. 첫 번째는 중학교 때 배웠던 일차방정식을 적용할 수 있는 선형회귀 그리고 유유상종의 원리를 이용한 k-최근접 이웃 방법(KNN). 사실 선형회귀를 시작으로 머신러닝을 설명하는 것은 어느 책이나 동일할 것이다. 반면 KNN부터 설명하는 책은 박해선님의 혼자공부하는머신러닝+딥러닝 에서 발견했는데 이런 시작 방법도 좋다고 생각한다.
그런의미에서 k-NN은 꽤나 애정이 가는 알고리즘이기도 하고 지금은 일기장에 된 네이버 블로그에도 첫 번째 알고리즘으로 작성한 바가 있다.
https://blog.naver.com/bellepoque7/223041890630
[글또] 분석알고리즘(머신러닝, 딥러닝) 간단 정리해보기 1편
1. 글의 목적 해결하려는 문제가 정의 되어있다면, 분석 방법론을 알고 방법론의 가정, 결과, 장단점 고려...
blog.naver.com
2.1. KNN
어떤 사람의 연봉이 궁금하면 직접 물어보는 방법 말고 어떻게 추측해볼 수 있을까? 주변 사람들의 연봉 수준을 물어볼 수도 있을 것이고 그 사람의 직군을 안다면 해당 직군의 평균연봉을 알면 어느정도 유추할 수 있을 것이다. 이처럼 예측하려는 값 추측하는 쉽고 합리적인 방법 k-최근접 이웃 방법(KNN)이 있다. 이름 그대로 이웃의 데이터를 이용해서 예측한다는 idea를 가지고 있다. 또한 k에 대한 설명을 추가적으로 하자면 다음 그래프를 보자
KNN방법은 다음 시각화 그래프가 너무도 유용해서 한번 더 쓸까한다.

?의 클래스 분류를 위해서는 주변의 데이터를 이용해서 예측한다고 했다. k는 이웃의 갯수이고 k=3이라면 ?는 세모로 예측하는게 합리적이며 k=7이면 별이라고 예측하는게 합리적일 것이다. 그럼 k는 어떻게 정하냐고 그건 이제 분석가의 일이 된다. 여기서 중요한 개념인 하이퍼파라미터를 함께 설명할 수 있다. 하이퍼 파라미터는 알고리즘에서 분석가들이 조정할 수 있는 파라미터를 뜻한다.
그럼 다시 돌아와서 k는 어떻게 정할까? 분류의 경우 정확도나 f1-score와 같은 지표를 이용해서 합리적인 평가가 나올 때 까지 k를 실험을 통해 최적의 값을 도출할 수도 도메인 지식에 따라서 정할 수도 있다. 이게 무슨말이냐면, 만약 아파트에 어떤사람이 직업을 가지고 있느냐 아니냐를 분류하는 문제를 볼 때 주변사람을 몇 명 관찰해야할까?
아주 주관적이지만 내 생각에는 해당 단지의 사람들만 봐도 좋을 것 같다. 이유인 즉슨 보통 직업을 가지고 있으면 가족을 형성했기 마련이며 큰집에 사는 경향이 많아서 k=1000명 정도만 잡아도 좋을 것 같다.
그럼 반문해볼 수 있을 것이다. 아니지 직업이 없으니까 가족에 얹혀사는 사람일 수 도 있지 않을까? 그럼 위 가정이 틀릴 수 있을텐데? 그러면 일반 아파트가 아닌 신혼희망타운과 같은 데이터로 관점을 옮긴다면? 좀 더 합리적인 추론이 될 것이다. 굉장히 뇌피셜이지만 한번 검증해볼만 한 가설이라고 생각한다. 이렇듯 k의 선정하는 근거는 도메인지식과 실험을 통해서 검증해야하는 파라미터이며 이를 근거있게 수립하는 것이 데이터 분석가가 하는 일이라고 할 수 있겠다.
2.2. KNN - 거리지표
최근접이웃 이라는 말마따나 거리가 중요한 측정 수단이다. 거리가 나온다면 가장 중요하게 진행되어야하는 과정이 바로 정규화이다. 사실 KNN뿐 아니라 거리기반의 알고리즘은 정규화를 진행해야한다. 쉽게말해서 단위통일이 필요하다. X 값들의 단위는 천차만별이다. 연봉이 X변수이면 0부터 10억까지 있는 반면, 나이는 0부터 100세까지 있다. 단위가 달라서 이를 통일화 시키는 과정을 정규화라고 한다. 일반적으로 해당하는 값에 평균을 빼고 표준편차를 나누는 정규화를 실행한다.
$Z = \frac{X-\mu}{\sigma}$
이렇게하면 데이터의 평균이 0 이고 퍼져있는 데이터 분포를 가질 수 있다. 반면 정규화가 데이터 분포를 변화시키는 것이 아님을 명심하자. 그러니까 left-skewed되어있다고 정규화를 실행하면 그대로 똑같은 분포형태를 가진다. 이런 경우 log scale 변형이 더 유효하다.
2.2.1. 거리지표 - 마할라노비스 거리
거리지표는 피타고라스정리로 쉽게 이해할 수 있는 유클리드거리, 각 지표간 값의 절대차이 값을 이용한 맨해튼 거리가 유명하다.
유클리디안 거리 : $d_E(\mathbf{x}, \mathbf{y}) = \sqrt{\sum_{i=1}^{n} (x_i - y_i)^2}$
맨하튼 거리 : $d_M(\mathbf{x}, \mathbf{y}) = \sum_{i=1}^{n} |x_i - y_i|$
오늘은 마할라노비스 거리를 한번 정리해보자 한다. 공돌이의 수학노트 마할라노비스 거리 블로그를 참조하였다.
다음 두 분포를 보자
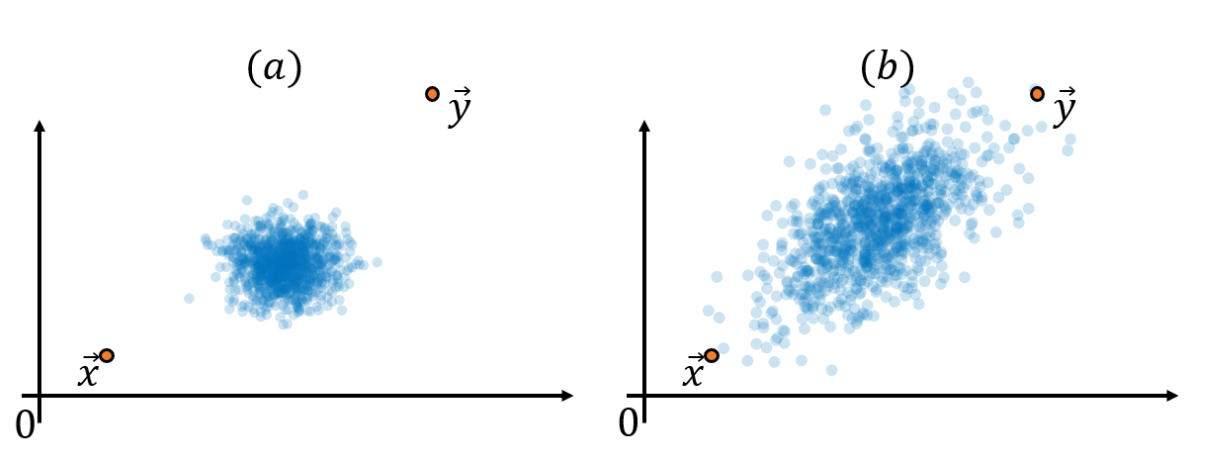
좌측은 데이터가 중심쪽에 모여있는 형태에 x,y 점을 표기한 것 우측은 좀 더 넓게 분포가 있는 형태이다. 이럴때 x와 y의 거리는 두 데이터 분포에서 같다고할 수 있을까? 실제로 유클리드 거리 그러니까 직선의 거리는 똑같다. 반면 마할라노비스 거리는 데이터의 맥락에 따라 좌측 (a) 그래프에서 두 점이 더 멀다는 것을 표현하고 싶다.
하지만 "맥락"이라는 것은 수학적이지 않다. 이 맥락을 수식화 하기 위해서는 단위의 통일이 필요할 텐데, 이 때 다시 등장하는 것이 정규화와 표준편차개념이다.
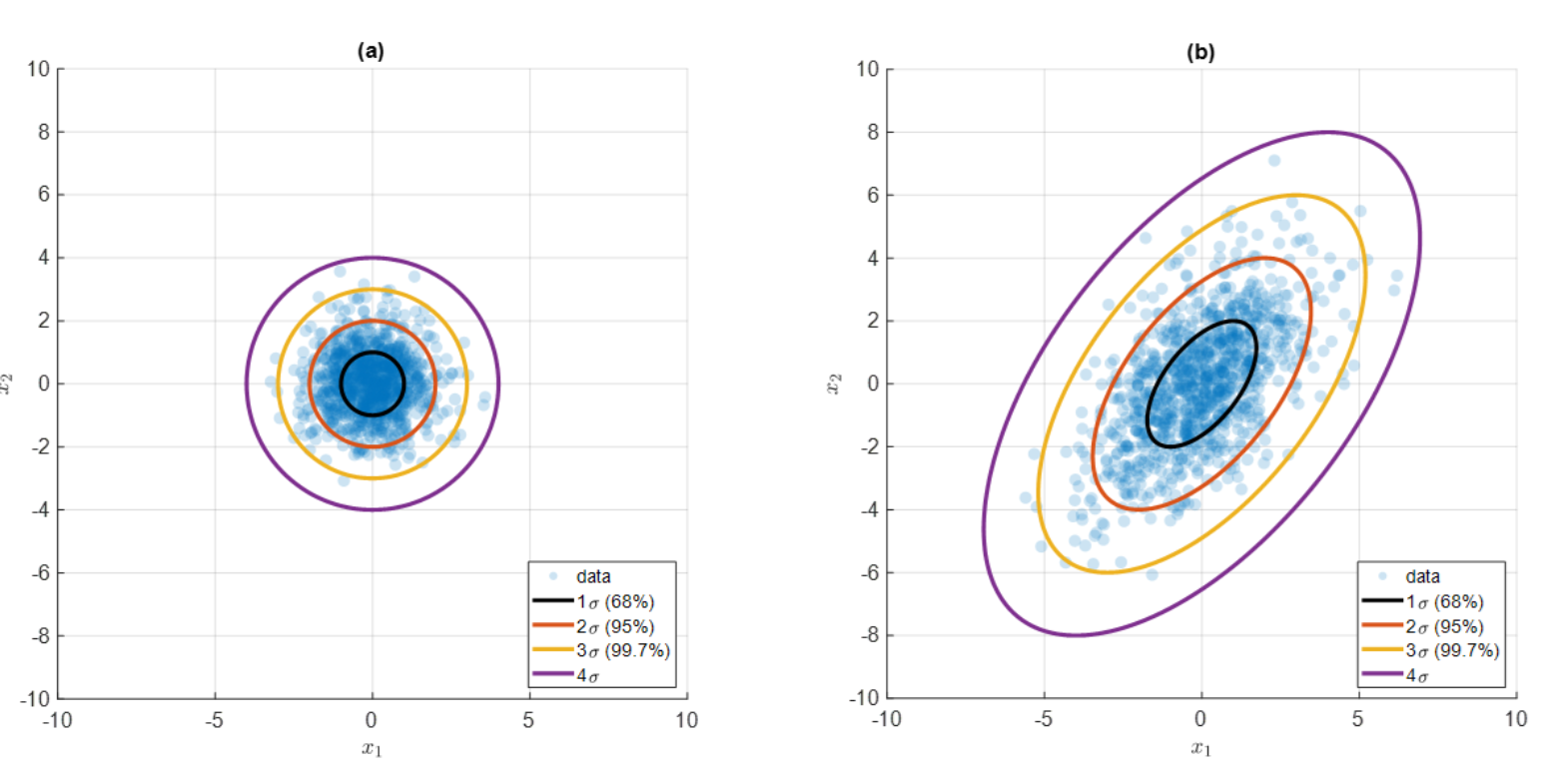
이렇게 보니 더욱 (b) 그래프가 분포가 넓어보이는 것을 알 수 있다. 그럼 (b) 산점도를 정규화를 통해서 (a) 산점도 처럼 바꿔볼 수도 있을 것 같다. 이를 선형대수에서 '선형변환' 이라고 한다.

동일한 그래프인데 좀 더 선형변환을 직관적으로 표현할 수 있는 산점도이다. 좌측 그래프에서는 노란색과 빨간색 점들 사이의 직선의 거리(= 유클리드 거리)는 같다. 반면 데이터의 맥락(퍼저있는 정도)를 고려하여 정규화 하여 선형변환하면 빨간색 점들의 거리가 더 가깝게 된다. 이 방법을 적용한 것이 마할라노비스 거리이다.
$ d_{z} = \sqrt{(x-y)\sum^{-1}((x-y)^{T}} $
중간식의 $\sigma^{-1}$ 는 공분산의 역행렬로 공부산 행렬은 데이터 변수간의 분산의 정보를 포함하여 정규화하는데 사용되며 변수들 간의 상관관계를 표현할 수 있어 사용한다. 예를들어 다음과 같은 2x2 공분산 행렬이 있다고 하면 의미는 다음과 같다.

위 내용은 공돌이의 수학노트 마할라노비스 및 유튜브 영상에서 더 자세히 볼 수 있다. 오늘도 공-멘
2.2.2. 그래서 마할라노비스 거리 어디다씀?
유클리디안거리와 맨하탄 거리보다 마할라노비스 거리는 데이터의 공분산 구조를 반영하기 때문에 맥락을 고려한 거리를 측정할 수 있다. 특히 판별분석이나 주성분 분석가 같은 변수간 관계를 고려할 때나 이상치를 탐지할 때 효과적이라고 알려져져 있다.
반면 데이터의 맥락을 반영한다는 점에서 좋은 거리지표로 보이지만 실제로는 공분산 행렬을 사용하기 떄문데 각 변수들이 독립적이지 않고 상관관계를 가질 때 유용하다. 사실 상관관계가 낮다면 마할라노비스와 유클리디안 거리는 크게 차이가 없다. 애초에 마할라노비스 거리가 데이터를 선형변환 한다음 유클리디안 거리를 측정하는 것이기 때문이다.
'Data Science > 데이터과학을 위한 통계' 카테고리의 다른 글
| (14) DSforS: Chap6. 6.3 배깅과 랜덤포레스트~ 6.4.부스팅 (0) | 2024.06.26 |
|---|---|
| (13)DSforS: Chap6. 6.2 트리 모델 - 정보이득개념 (0) | 2024.06.23 |
| (11) DSforS : Chap5 5.5 불균형 데이터 다루기 (0) | 2024.06.16 |
| (10) DSforS : Chap5. 분류 5.3 ~ 5.4. 로지스틱회귀(LoR), 분류모델 평가 (0) | 2024.06.11 |
| (9) DSforS : Chap5. 분류 5.1 ~ 5.3 나이브베이즈(NB), 선형판별분석(LDA) (0) | 2024.06.10 |