
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- F분포
- CC#5
- PGTM
- 취업
- 영화
- 엘뱌키안
- Toastmaster
- 구글#빅쿼리#데이터분석
- 대중연설
- Public Speaking
- 데분
- 데이터분석
- SQLD
- 카이제곱분포
- 제약
- 공유경제
- 인과추론
- 임상통계
- 풀러스
- 토스트마스터
- 정형데이터
- 평창
- 사이허브
- 연설
- CC#3
- 데이터
- publicspeaking
- 2018계획
- 영어연설
- 분석
- Today
- Total
지지플랏의 DataScience
(4) DSforS : Chap 2 탐색적 데이터분석 2.4 ~ 2.8 본문
- 2.9.이항분포
- 2.10. 카이제곱분포
- 2.11. F분포
- 2.12. 푸아송 분포와 그 외 관련 분포들
- 2.13. 마치며
2. 본문
2.9. 이항분포
베르누이분포는 1회 실행하였을 때, 결과를 0 또는 1로 표현한 분포이다. 반면, 이항분포는 각 시행마다 성공확률(p)가 정해져있을때 주어진 시행 횟수(n) 중에서 성공한 횟수(x)의 도수 분포를 말한다. 따라서 n,p에 따라 다양한 이항분포가 존재한다.
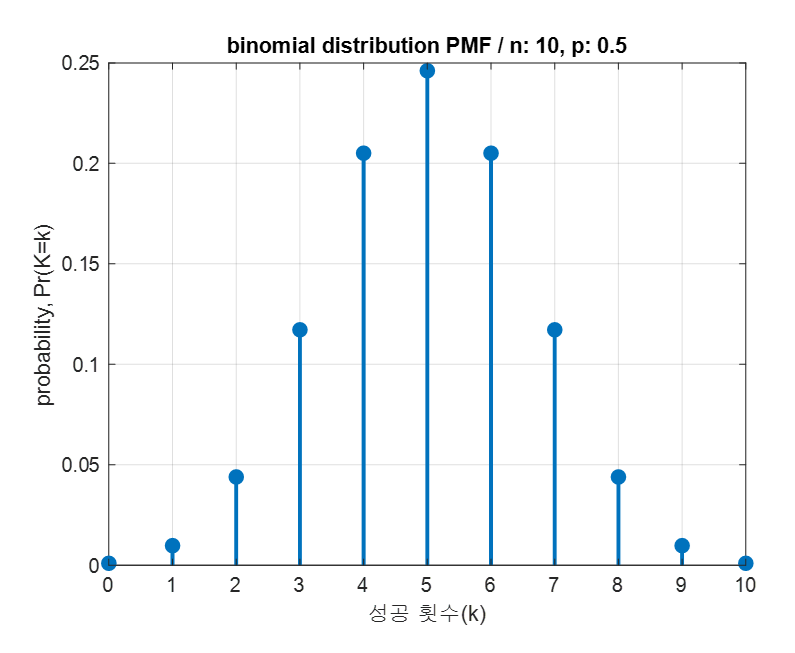
이항분포의 평균은 n * p 이며 분산은 n * p * (1-p) 이다. N이 커지면 정규분포로 근사할 수 있다.
관련용어
- 시행(trial): 독립된 결과를 가져오는 하나의 사건(예: 동전 던지기)
- 성공(sucees): 시행에 대한 관심의 결과(유의어:1, 즉 0에 대한 반대)
- 이항식(binomial): 두 가지 결과를 갖는다.(유의어: 예/아니요, 0/1, 이진)
- 이항시행(bionmial trial): 두 가지 결과를 가져오는 시행(유의어: 베르누이 시행)
- 이항분포(binomial distribution): n번 시행에서 성공한 횟수에 대한 분포(유의어: 베르누이 분포)
2.10. 카이제곱분포
표준정규분포를 따르고 서로 독립인 m개의 확률변수 Z1, ...Zm 을 각각 제곱하여 합치면 그 합은 자유도 m인 카이제곱 분표를 따른다. 카이제곱통계량을 이용해 자료가 어떤 특정한 확률 모형으로 나온 것인지 검정할 수 있다.
카이제곱검정은 상자의 내용 구성이 알려져 있을 때, 관측된 자료를 이 상자로부터 무작위 추출한 결과로 볼 수 있는지 그 판단 근거를 제공한다.
z-검정, t-검정은 상자의 평균이 주어져있을 때 관측된 자료를 이 상자로부터 무작위를 추출한 결과로 볼 수 있는지 그 판단 근거를 제공한다.
여러 범주에 거쳐 관측된 도수와 기대도수의 차이는 카이제곱통계량으로 측정한다.

- 가설
- 귀무가설 : H0 = 범주형 데이터가 나타날 확률이 다 같다(차이가 없다).
- 대립가설 : H1 = 범주형 데이터가 나타날 확률이 같지 않다(차이가 있다).

- 정규분포의 합이 카이제곱분포임을 보여주는 수행과정
- 5개의 표준 정규분포 샘플을 10000개 생성합니다.
- 각 샘플의 제곱합을 계산합니다.
- 그 결과의 히스토그램을 그리고, 이론적인 카이제곱 분포와 비교합니다.
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from scipy.stats import norm, chi2
# Set the parameters
num_samples = 10000
num_normals = 5
# Generate num_samples samples of num_normals standard normal variables
normal_samples = np.random.normal(0, 1, (num_samples, num_normals))
# Sum of squares of the samples
sum_of_squares = np.sum(normal_samples**2, axis=1)
# Plot the histogram of the sum of squares
plt.figure(figsize=(10, 6))
sns.histplot(sum_of_squares, bins=50, kde=True, color='blue', stat='density', label='Sum of Squares of Normals')
# Plot the theoretical chi-squared distribution
x = np.linspace(0, 20, 1000)
plt.plot(x, chi2.pdf(x, df=num_normals), 'r-', lw=2, label=f'Chi-squared (df={num_normals})')
plt.xlabel('Value')
plt.ylabel('Density')
plt.title('Sum of Squares of Standard Normal Distributions vs. Chi-squared Distribution')
plt.legend()
plt.show()
- 예시(일원 카이제곱검정)


검정결과 식품별 선호도가 다름을 알 수 있다.
https://angeloyeo.github.io/2021/12/13/chi_square.html#google_vignette
카이제곱 분포와 검정 - 공돌이의 수학정리노트 (Angelo's Math Notes)
angeloyeo.github.io
- 동질성 검정: 여러 개의 동일한 분포를 따르는지 확인하는 것이 목적
- 절차:
- 각 그룹의 관측된 빈도 데이터를 수집합니다.
- 기대 빈도는 각 그룹이 동일한 분포를 따를 때의 빈도로 계산합니다.
- 카이제곱 검정을 수행하여 관측된 빈도와 기대 빈도가 얼마나 다른지를 평가합니다.
- 검정 통계량이 카이제곱 분포를 따르며, 그 값이 임계값을 넘으면 귀무가설(모든 그룹이 동일한 분포를 따른다)을 기각합니다.
- 절차:
- 독립성 검정: 두 범주형 변수 간에 독립적인지, 즉 서로 연관성이 없는지 검정하는 목적
- 절차:
- 두 범주형 변수의 교차표(contingency table)를 작성합니다.
- 각 셀의 기대 빈도를 계산합니다.
- 카이제곱 검정을 수행하여 관측된 빈도와 기대 빈도가 얼마나 다른지를 평가합니다.
- 검정 통계량이 카이제곱 분포를 따르며, 그 값이 임계값을 넘으면 귀무가설(두 변수는 독립이다)을 기각합니다.
- 절차:
2.11. F분포




위 정의된 F 값의 분포가 F분포이다. 그럼 어떤 의미가 있는 것일까? 분모와 분모는 X,Y의 분산이다. 동일한 모집단에서 추출한 집단의 분산 비율이다. 따라서 여러 데이터 집단이 동일한지, 평균이 같은지 아니지를 검정(분산분석)하는데 사용한다.
- 귀무가설: 두 집단의 모분산은 동일하다.
- 대립가설: 두 집단의 모분산은 동일하지 않다.

F분포 어디에 쓰일까?
※이전글 카이제곱 분포 관련글 확률, 확률변수 그리고 확률분포 1. 들어가며 통계학은 기술통계와 추론통계로 구분되는데, 기술통계와 추론통계를 연결해주는 것이 확률분포이다. 그런데 확률
diseny.tistory.com
https://angeloyeo.github.io/2020/02/29/ANOVA.html#fn:2
F-value의 의미와 분산분석 - 공돌이의 수학정리노트 (Angelo's Math Notes)
angeloyeo.github.io
그룹간변동, 그룹내 변동 구하기 샘플 식
import numpy as np
# 예제 데이터
group1 = np.array([20, 21, 19, 18, 20])
group2 = np.array([22, 23, 21, 20, 22])
group3 = np.array([19, 20, 18, 17, 19])
# 모든 데이터를 하나의 배열로 합침
all_data = np.concatenate([group1, group2, group3])
# 전체 평균 계산
overall_mean = np.mean(all_data)
# 각 그룹의 평균 계산
mean1 = np.mean(group1)
mean2 = np.mean(group2)
mean3 = np.mean(group3)
# 그룹 내 변동(SSE) 계산
sse = np.sum((group1 - mean1)**2) + np.sum((group2 - mean2)**2) + np.sum((group3 - mean3)**2)
# 그룹 간 변동(SSB) 계산
n1, n2, n3 = len(group1), len(group2), len(group3)
ssb = n1 * (mean1 - overall_mean)**2 + n2 * (mean2 - overall_mean)**2 + n3 * (mean3 - overall_mean)**2
sse, ssb
2.12. 푸아송 분포와 그 외
용어정리
- 람다(lambda): 단위 시간이나 단위 면적단 사건이 발생하는 비율
- 푸아송분포(Poisson distribution): 표집된 단위 시간 혹은 단위 공간에서 발생한 사건의 도수 분포
- 지수분포(exponential distribution): 한 사건에서 그다음 사건까지의 시간이나 거리에 대한 도수 분포
- 베이불분포(Weibull distribution): 사건 발생률이 시간에 따라 변화하는 지수 분포의 일반화된 버전
2.12.1 푸아송 분포
- 푸아송분포는 단위 시간 안에 어떤 사건이 몇번 발생할 것인지 표현하는 이산 확률 분포이다.
- 정해진 시간 안에 어떤 사건이 일어날 횟수에 대한 기대값을 λ 라고 했을 때 그 사건이 k번 일어날 확률은 다음과 같다.


https://www.youtube.com/watch?v=0aMlpmkZsck&t=309s
2.12.2 지수분포
2.12.3 고장률 추정

- 지수분포: 사건이 서로 독립일때 일정시간동안 발생하는 사건의 횟수가 푸아송 분포를 따른다면, 다름 사건이 일어날 때까지 대기시간의 분포

사건 발생비율 람다는 알려져 있거나 추정할 수 있지만 드물게 발생하는 사건은 그렇지 않다. 이를 추정하는 방법을 고장률 추정이라고한다.
2.12.4 베이블 분포

수명 데이터 분석에 사용되며 산업현장의 부품의 수명을 추정하는데 사용한다.

'Data Science > 데이터과학을 위한 통계' 카테고리의 다른 글
| (6) DSforS : Chap 3 통계적 실험과 유의성 검정 3.4 ~ 3.8. (0) | 2024.05.27 |
|---|---|
| (5) DSforS : Chap 3 통계적 실험과 유의성 검정 3.1 ~ 3.3. (0) | 2024.05.22 |
| (3) DSforS : Chap 2 탐색적 데이터분석 2.4 ~ 2.8 (1) | 2024.05.15 |
| (2) DSforS : Chap 1 탐색적 데이터분석 1.5 ~ 2.3 (2) | 2024.05.13 |
| (1) DSforS : Chap 1 탐색적 데이터분석 1.1 ~ 1.4 (6) | 2024.05.08 |



