
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 영화
- publicspeaking
- SQLD
- CC#3
- 연설
- 2018계획
- 풀러스
- 데이터
- 구글#빅쿼리#데이터분석
- F분포
- 정형데이터
- 분석
- Public Speaking
- 데분
- 평창
- CC#5
- 인과추론
- 공유경제
- 토스트마스터
- 데이터분석
- 카이제곱분포
- 제약
- 임상통계
- 영어연설
- 취업
- 엘뱌키안
- 대중연설
- PGTM
- Toastmaster
- 사이허브
- Today
- Total
지지플랏의 DataScience
(8) Khan Academy: 유의성 검정과 절차, 통계방법론 정리 본문
이번 글에서는 추론통계의 핵심 유의성 검정과 등장하는 개념, 그리고 일반적인 통계방법론을 정리해본다.
1. 글목차
- 유의성 검정에 필요한 개념
- 1종오류와 2종오류
- 유의성 검정 절차
- 통계검정 절차(Diagram) -연속형 종속변수인 경우, 일반적인 경우
2. 본문
2.1. 유의성 검정의 개념
유의성검정은 연구나 실험에서 관찰된 결과가 우연에 의한 것인지 아니면 실제로 의미있는 차이가 존재하는지를 판단한다는 것이다.
이를 위해 몇가지 기본 개념을 설명하고 진행해야한다.
- 귀무가설($H_{0}$): 일반적으로 받아들여지는 사실
- 대립가설($H_{1}$): 주장하고자 하는 바(귀무가설의 반대)
왜 귀무가설을 상정해야하는가? 수학의 증명방법 중에 귀류법 이라는 것이 있다. 모순에 의한 논증법으로 일단 귀무가설이 사실이라고 치자. 그리고 논리를 전개하다가 모순에 도달하게 되면 대립가설을 채택하게 되고 그렇지 않으면 귀무가설을 지지하게 되는 것이다.
- p-value: 관찰된 데이터가 귀무가설 가설이 참일 때 얻어질 확률이다.
- p-value가 작다면 귀무가설이 참일때 관찰된 데이터가 발생할 확률이 낮다는 의미다. 이는 우연에 의한 사건으로 보기 어렵다고 판단할 수 있으며, 그때는 귀무가설을 기각하고 대립가설을 채택해야한다.
- p-value가 크다면 이는 우연에 의한 사건으로 판단하여 귀무가설을 지지하는 증거가 된다.

그렇다면 그 p-value의 기준은 얼마로 판단해야하는가? 이를 유의수준(significant level, $\alpha$)이라고 한다. 일반적으로 0.05 즉 5% 를 기준으로 그보다 희박한 확률인가 아닌가가 판단 기준이된다.
p-value는 증거의 강도를 나타내지만 확실한 결론을 제공하지는 않는다. 이 때문에 유의수준이라고 하는 우리만의 기준을 만들어서 해석한다고 할 수 있다. 또한, 효과의 크기나 중요성을 표현하진 않는다.
- 검정 통계량(test statistic)
- 검정통계량은 데이터를 단일된 숫자로 요약하여 관찰된 데이터가 귀무가설 하에서 기대되는 것과 얼마나 차이나는 지 평가할 수 있는 척도이다.
- z-검정 통계량
- 사용조건: 모집단의 표준편차($\sigma$)가 알려져 있는 경우
- 표본의 크기가 충분히 큰 경우(경험적 기준 n>30)
$z = \frac{\bar{X} - \mu_0}{\frac{\sigma}{\sqrt{n}}}$
- t검정 통계량
- 모집단의 표준편차($\sigma$)가 알려져 있지 않은 경우
- 표본 크기가 작은 경우
$t = \frac{\bar{X} - \mu_0}{\frac{s}{\sqrt{n}}}$
- 카이제곱 검정 통계량
$\chi^2 = \sum \frac{(O_i - E_i)^2}{E_i}$
- F-검정 통계량
$F = \frac{\text{Between-group variability}}{\text{Within-group variability}} = \frac{\frac{SSB}{df_B}}{\frac{SSW}{df_W}}$
2.2. 1종 오류와 2종 오류
늘 판단은 틀릴 수 있다. 이를 극복하기 위한 것이 혼동행렬이다.
| 판단 \ 실제 상황 | 귀무가설이 사실 | 대립가설이 사실 |
| 귀무가설을 기각하지 못함 | 옳은 채택( ($1-\alpha$) | 2종 오류($\beta$) |
| 귀무가설을 기각함 | 1종 오류($\alpha$) | 옳은 기각($1-\beta$, 검정력 ) |
귀무가설은 일반적으로 우리가 받아들여지는 사실이라고 했다. 유의수준을 0.05로 설정하고 꽤나 까다롭게 설정하였는데도 불구하고 판단은 틀릴 수 있다. 정말 우연하게도. 귀무가설이 사실인데도 불구하고 대립가설을 채택하는 상황을 1종오류 ($\alpha$) 라고 한다. 일반적으로 받아들여지는 사실을 바뀐다는 것은 혼란을 불러온다. 우리는 이를 관리하기 위해서 일반적으로 1종오류를 관리한다.
반면 대립가설이 사실인데도 불구하고 귀무가설을 채택하는 경우를 2종 오류 ($\beta$) 라고 부른다.일반적으로 1종 오류와 2종 오류는 동시에 낮추기 어렵고 상충관계(Trade off)가 존재한다. 귀무가설이 거짓일 때, 이를 옳게 기각할 확률을 검정력(power)라고 하며 $ 1- \beta$로 표현한다.
검정력과 표본크기 계산은 다음 링크를 참조
(6) DSforS : Chap 3 통계적 실험과 유의성 검정 3.4 ~ 3.8.
1. 목차3.4. 통계적 유의성과 p값3.5. t검정3.6. 다중검정3.7. 자유도3.8. 분산분석 2. 본문3.4. 1종오류와 2종오류1종 오류: 귀무가설이 참인데도 불구하고 귀무가설을 채택하지 않는 오류2종 오류:
snowgot.tistory.com
2.3. 유의성 검증 절차
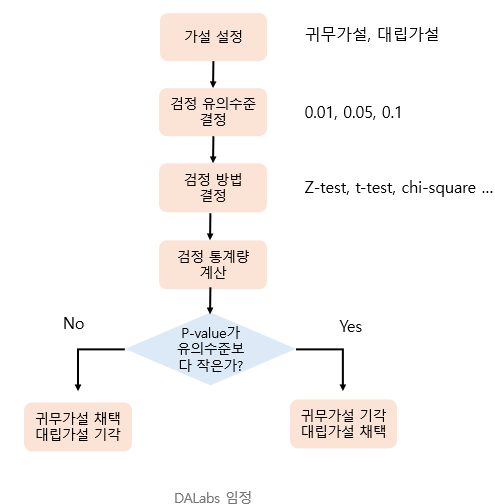
유의성 검증 절차는 다음과 같다.
- 귀무가설, 대립가설을 설정한다.
- 검정 유의수준(1종오류를 관리할 기준)을 세운다.
- 검정 방법을 결정한다(구하려는 문제에 따라 적용)
- 검정 통계량을 계산한다.
- 판단
2.4. 통계 방법론 정리
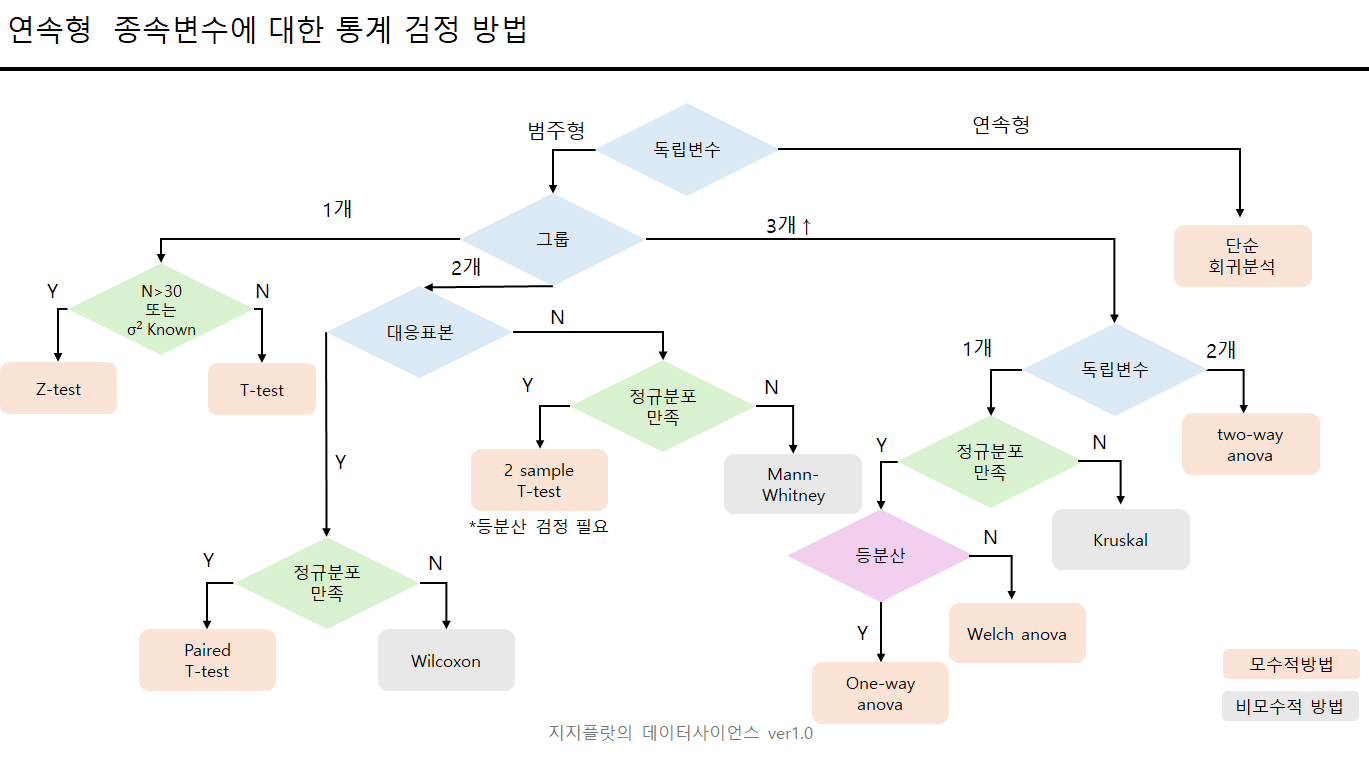
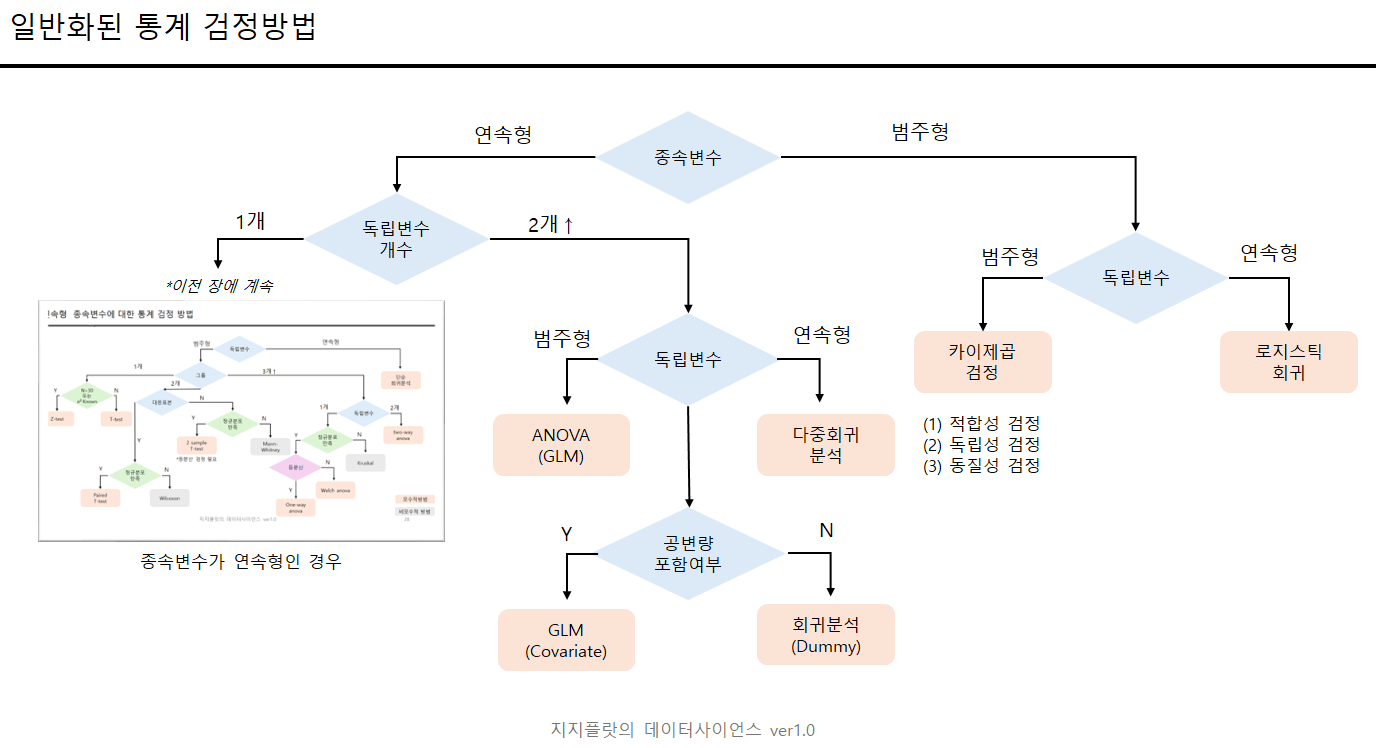
'Data Science > Khan Academy' 카테고리의 다른 글
| (1) 선형대수: 선형대수의 활용분야와 벡터 (0) | 2024.10.21 |
|---|---|
| (9) Khan Academy 카이제곱분포와 검정과 F분포와 분산분석 (0) | 2024.08.19 |
| (7) Khan Academy: 11단원 모평균과 모비율 추론, 신뢰구간 (0) | 2024.08.04 |
| (5) Khan Academy: 9단원 확률변수 (0) | 2024.07.31 |
| (4) Khan Acadmey: 단원7,8: 조합,순열 그리고 확률에 관련된 기호들 (1) | 2024.07.22 |



