
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- Public Speaking
- 사이허브
- 구글#빅쿼리#데이터분석
- 영화
- 인과추론
- 분석
- 임상통계
- CC#3
- 풀러스
- Toastmaster
- 카이제곱분포
- 토스트마스터
- 영어연설
- 대중연설
- 공유경제
- 데이터
- CC#5
- SQLD
- 평창
- 취업
- 2018계획
- 연설
- 엘뱌키안
- 제약
- PGTM
- publicspeaking
- F분포
- 정형데이터
- 데이터분석
- 데분
- Today
- Total
지지플랏의 DataScience
DDIA Chapter 6: 파티셔닝 본문
이번 글에서는 복제에 이어 데이터 파티셔닝 방법과 이를 인덱싱하기 위한 전략을 알아봅니다. 특히 데이터가 커지는 경우에는 필수적으로 파티셔닝이 필요하며, 이를 나누기 위한 키-범위 파티셔닝과 해쉬 파티셔닝에 대해서 알아보고, 쓰기와 읽기 성능을 고려한 로컬과 글로벌 이차 인덱스방법에 대해서 기술합니다. 또한 개발이 끝이 아니듯 운영에서 발생할 수 있는 리밸런싱 전략에 대해서 알아봅니다. 전반적으로 대용량 데이터베이스를 설계자 입장에서 고려하고 고민할 것들이 많이 도출 되는 좋은 단원이였습니다!
신규개념
| 개념 | 설명 |
| 파티셔닝(Partitioning) | 성능, 확장성, 유지성을 목적으로 논리적인 데이터를 다수의 엔터티로 분할하는 행위 |
| 복제(Replication) | 동일한 데이터를 여러 노드에 저장하여 장애 복구를 대비하는 방법 |
| 노드(Node) | 스토리지 단일 서비스 혹은 네트워크 일부를 구성하는 서버 |
| 핫스팟(Hospot) | 특정 파티션에 부하가 집중되는 현상 |
| 해시 파티셔닝 | 데이터를 균등하기 분산시키기 위해서 해시 함수를 사용 |
| 키 범위 파티셔닝 | 연속된 키 범위에 따라 데이터를 분배 |
| 이차 인덱스 파티셔닝 | 검색을 위한 인덱스를 파티셔닝하는 방식 |
| 리밸런싱(Rebalancing) | 노드 추가/삭제 시 데이터를 재분배하는 과정 |
| 라우팅(Routing) | 네트워크에서 경로를 선택하는 프로세스 |
1. 파티셔닝의 정의
- 파티셔닝이란 큰 데이터베이스를 여러 개의 작은 데이터 베이스로 나누는 기법
- 네트워크 분할(Network Partition)과는 다르며 주 목적은 확장성(Scalability) 확보
- 대용량 데이터를 효율적으로 관리하고 고 성능 쿼리 처리를 가능하게 한다.
- 보통 샤딩(Sharding)이라는 용어와 혼동되며 데이터 베이스마다 다르게 불
(Amendment) 사실 파티셔닝이라는 개념은 윈도우 설치할 때 하나의 디스크에 "파티셔닝"하여 C / D드라이브로 만들 때 마주할 수 있다.
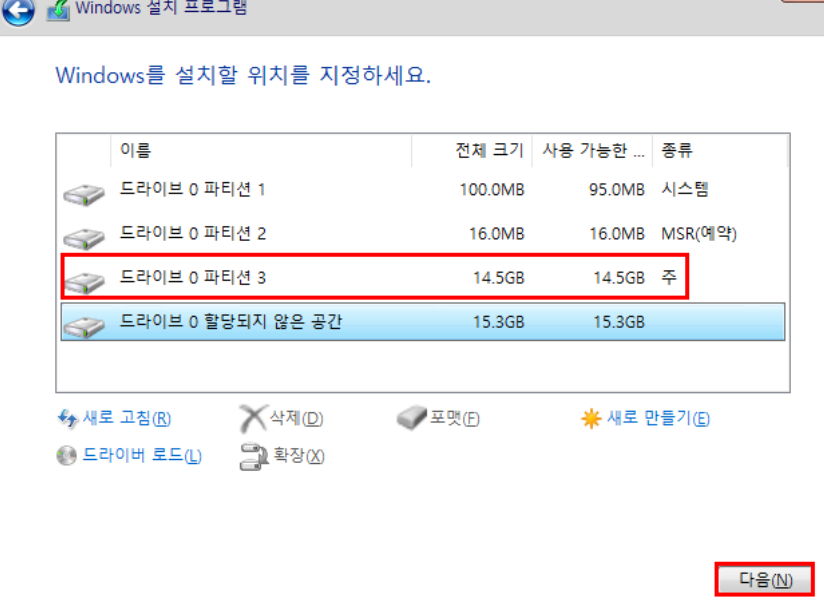
이처럼 파티셔닝은 데이터베이스를 논리적으로나 물리적으로 분할하여 관리하는 기술로, 데이터 베이스의 성능응 향상시키고 관리를 용이하게 합니다. 파티셔닝을 통해 데이터 베이스 조회 속도를 높이고 백업 및 복구시간을 단축할 수 있기 때문입니다.
출처: F-lab 데이터 파티셔닝 전략
2. 파티셔닝과 복제
- 대부분의 시스템에서 파티셔닝과 복제가 함께 사용됨
- 파티셔닝: 데이터를 여러 노드에 나누어서 저장
- 복제: 동일한 데이터를 여러 노드에 저장하여 장애 대비
(Amendment) 파티셔닝과 복제가 주로 이루어지는 이유는 각 목적을 살펴보면 된다. 데이터의 크기가 커질수록 한 노드(서버)에 저장할 수 없게 된다. 이를 여러 노드에 나워서 수평 확장을 노려볼 수 있다. 파티션 단위로 데이터 읽기/쓰기 작업을 하여 성능 향상을 하는 한편, 특정 파티션만 검색하도록 최적화하여 쿼리 성능을 향상시킬 수 있다. 이로 인한 단점은 한 노드에 한 개만 저장되므로 노드 장애 시 데이터 유실 위험이 존재한다.
반면, 복제는 고가용성(High Availability)와 내결함성(Fault Tolerance) 확보가 목적으로 동일한 데이터를 여러 노드에 복제하여 데이터 손실을 방지하며, 특정 노드가 장애가 나더라도 복제본의 데이터를 제공을 가능하게 한다. 읽기 부하(Read Load)를 여러 복제본에 분산하여 읽기 성능 향상이 가능하며 특히 리더 -팔로워 모델이 유용하다. 단점으론느 복제된 데이터를 주기적으로 동기화해야하므로 쓰기 성능 저하 가능하며 데이터 일관성의 유지가 필요하다. 따라서, 파티셔닝. 을 통해 확장성을 확보하는 한편 복제를 통해 가용성을 보장하는 것이 대규모 데이터 베이스의 운영의 핵심이라고 할 수 있다.
3. 파티셔닝 전략
1. 키 - 범위 파티셔닝(Key Range Partitioning)
- 연속적인 키 범위를 기준으로 데이터를 분할
- 장점: 키 순서가 유지되므로 범위 쿼리에 적합
- 단점: 특정 키 범위에 쿼리가 집중되면 핫 스팟 발생 가능
쉽게 말하면 백과사전에서 특정 단어를 찾는 과정과 비슷하며, Hbase, RethinkDB, MongDB에 쓰임. 핫스팟의 문제는 센서 데이터의 예를 들면 편한데, 만약 센서 데이터의 파티션이 날짜로 지정해되면 특정 파티션은 과부화가 걸리는 반면 다른 파티션은 유후상태(Idle)이 된다. 이를 보완하기 위해서 센서이름 + 타임스탬프 형태의 키를 구성하면 각 센서별로 파티션에 나뉘고 이후 시간 순서대로 저장되므로 쓰기 부하가 고루 분산될 수 있는 장점이 있다.

2. 해시 파티셔닝(Hash Partitioning)
- 키를 해시 함수에 통과시켜 균등하게 분산
- 장점: 데이터가 균등하게 분배되어 핫스팟 발생 가능성 적음
- 단점: 키 정렬이 깨져서 범위 쿼리의 어려움

skwed된 데이터와 hotspot의 문제 때문에 고안된 데이터 모델. 파티션 간의 고른 데이터 분배를 노릴 수 있음.
4. 파티셔닝과 이차 인덱스
이차 인덱스는 데이터 베이스에서 기본 키 이외에 다른 컬럼을 기준으로 빠르게 데이터를 검색하기 위한 인덱스이다. 파티셔닝이 적용된 데이터베이스에서는 기본 키를 기준으로 데이터를 찾는 것은 쉽지만, 기본 키가 아닌 다른 컬럼으로 검색할 때 문제가 발생할 수 있으며 이를 해결하기 위해 이차 인덱스가 등장한다.
(Amendement)
CREATE TABLE users (
user_id INT PRIMARY KEY,
name VARCHAR(100),
email VARCHAR(255),
country VARCHAR(50)
);위 경우 user_id가 기본키이므로 user_id = 1234 는 빠르게 검색 가능한 반면, where country = 'USA' 같은 쿼리는 효율적으로 실행되지 않으므로, 다음 이차 인덱스를 생성하여 검색 성능 향상을 노린다.
CREATE INDEX idx_country ON users(country);이런 이차 인덱스를 저장함에 있어서 2가지 방식을 선택할 수 있다.
1. 문서 기반 인덱스( Document-partitioned indexes, Local Index)
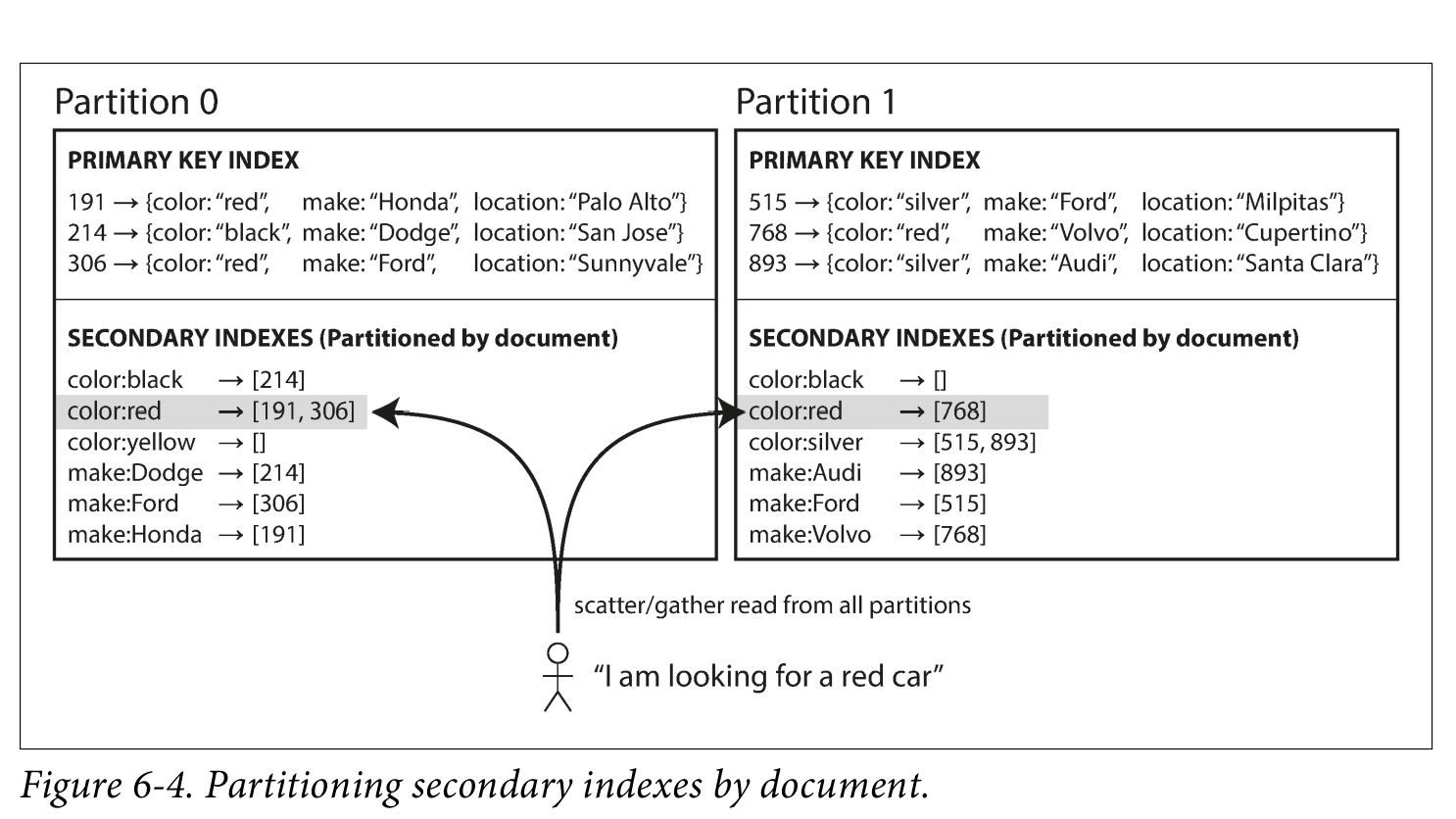
- 이차 인덱스를 해당 데이터가 있는 파티션 내부에 저장
이차 인덱스가 기본키 및 값과 동일한 파티션에 저장됨. 즉 데이터 쓰기를 할때는 해당 파티션 하나만 업데이트하면 되므로 쓰기 성능이 우수하다. 반면 이차 인덱스를 기반으로 조회할 경우 모든 파티션을 검색(Scatter)하고 결과를 모아야(Gather)해야하므로 성능 저하 가능성이 있다.
(Amendment) 예를 들어 country = 'USA" 데이터가 각 파티션에 분산되어 있다면 각 파티션 마다 country 인덱스가 생성 됨. 데이터를 추가하거나 수정할 때 해당하는 파티션만 업데이트하면 되므로 쓰기 성능이 좋으나, 데이터 검색할 때는 쿼리 속도가 느려질 수 있다.
2. 용어 기반 인덱스(Term-partitioned indexes, Global Index)
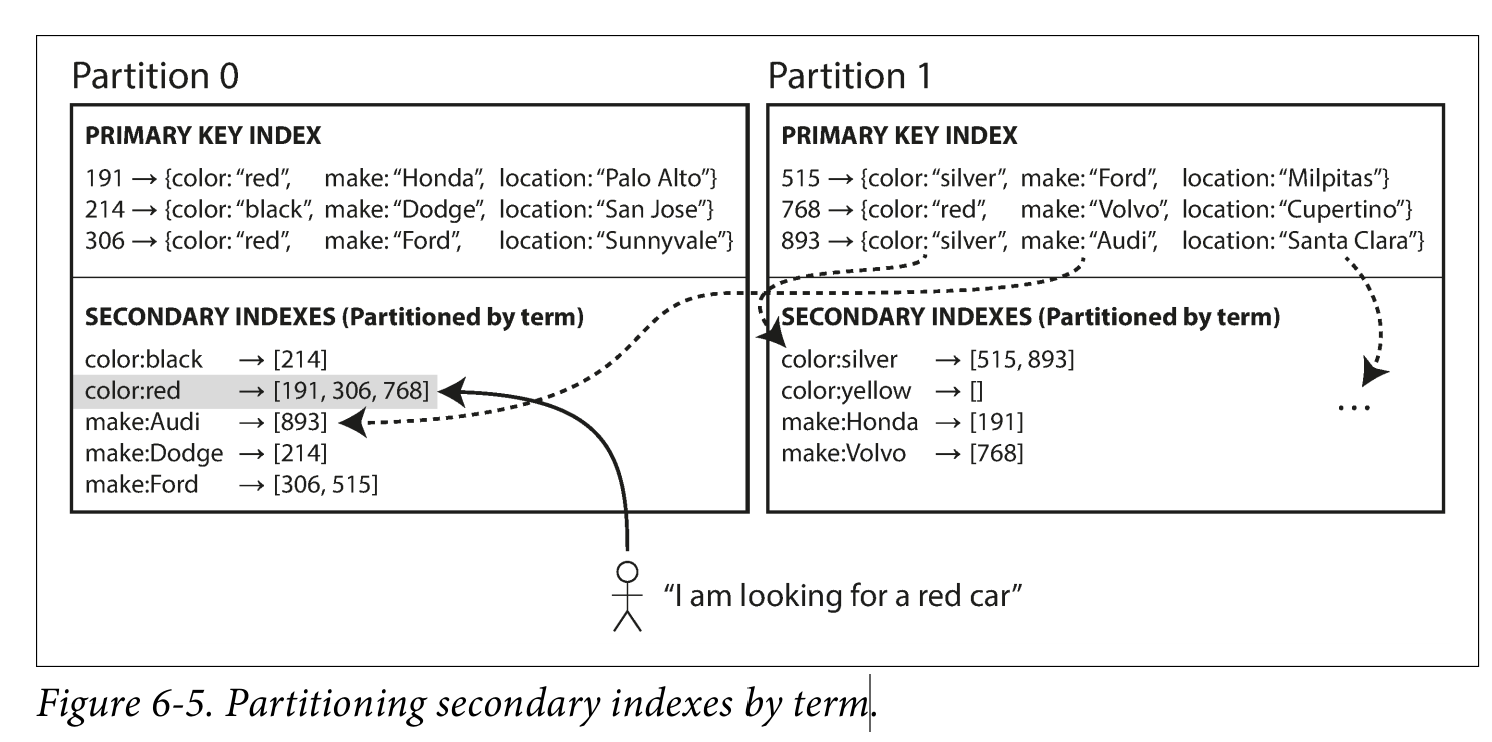
- 이차 인덱스를 별도의 파티션으로 저장
이 방식에서는 이차 인덱스가 기본키와 독립적으로 분할되어 저장되어 이차 인덱스는 특정 필드 기준으로 별도로 파티셔닝된다. 또한 하나의 인덱스 방식이 여러 개의 파티션에 있는 데이터를 포함할 수 있다. 쓰기 시에는 여러개의 파티션을 업데이트 해야하므로 쓰기 성능이 저하될 수 있으나 읽기 시에는 특정 값을 포함하는 단일 파티션에서만 데이터를 가져올 수 있으므로 조회 성능이 향상된다.
(Amendement) where country = 'USA' 검색 시 USA 관련 데이터가 저장된 단일 파티션만 조회하면 되므로 성능이 빠르고 읽기 성능이 최적화, 데이터를 추가할 때, 이차 인덱스가 여러 파티션에 걸쳐 존재하므로 여러 개의 파티션을 업데이트 해야하여 쓰기 성능이 저하될 수 있다.
| 문서기반(로컬 인덱스) | 용어기반(글로벌 인덱스) | |
| 쓰기성능 | 빠름 | 느림 |
| 검색성능 | 느림 | 빠름 |
5. 리밸런싱
개발보다 중요한 것은 운영이라고 했던가 필수적으로 데이터베이스를 운영하다보면 특정 노드에 데이터가 집중되거나 부하가 편향되는 불균형(imbalance)가 일어날 수 있다. 따라서 리밸런싱을 통해서 데이터와 쿼리 부하를 공정하게 분배해야하는 요구사항이 반드시 생겨난다.
또한 리밸런싱을 할 떄 지켜야할 원칙은 ① 리밸런싱 후 노드간의 데이터와 부하가 균등해야하며 ② 리밸런싱 과정에서 읽기와 쓰기에 대한 수행은 계속되어야 하며 ③ 리밸런싱의 속도를 빠르고 네트워크 및 디스크 I/O 부하를 최소화하기 위하여 필요한 데이터 이상의 데이터가 노드 간 이동해서는 안된다. 등 이다.
1. 고정된 파티셔닝(Fixed Partitioning)
- 데이터베이스를 고정된 파티션으로 나누는 기법. 노드가 추가되거나 삭제되어도 파티션의 갯수는 동일
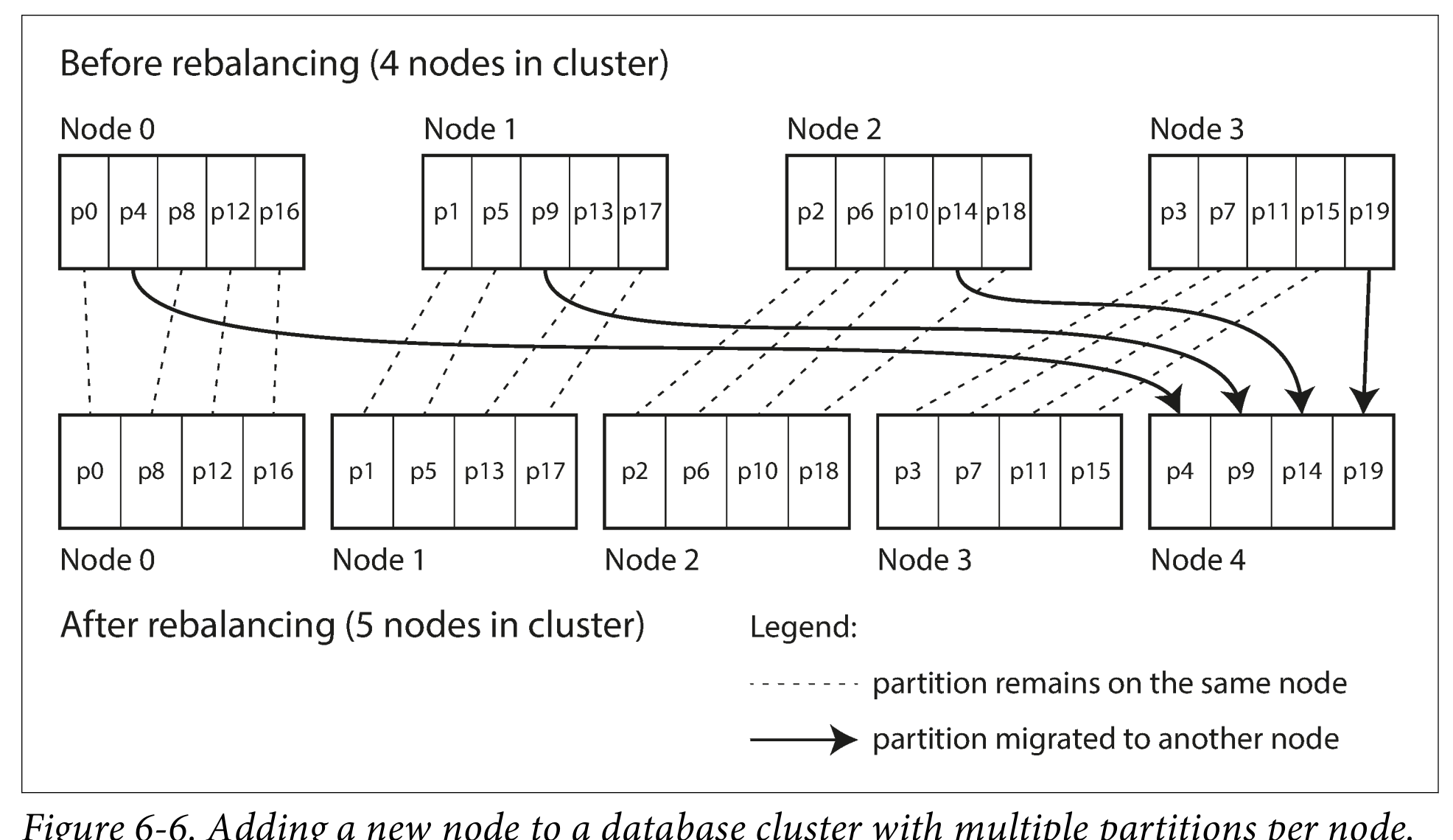
가장 고전적인 방법으로 고정된 파티션의 갯수를 유지하는 방법이다. 하지만 처음에 너무 적은 파티션을 설정하면 확장시 부담이 커지고 많으면 관리 오버헤드가 커진다. 시간이 지나면 특정 파티션에 데이터가 몰려 일부 파티션에만 과부화가 생길 수 있으며, 초기 설정된 파티션의 갯수가 적절한지 어려운 단점이 있다.
따라서 데이터 양이 일정하고 급격한 변화가 없는 경우, 시스템 운영이 단순해야하는 정형데이터의 경우나 리밸런싱 속도가 중요한 경우 고정된 파티셔닝 방법을 고려할 수 있다.
2. 동적 파티셔닝(Dynamic Partitioning)
동적 파티셔닝은 데이터가 증가하면 자동으로 파티션을 2개로 분할하고 반대로 삭제하면 통합하는 방식으로 관리하는 기법이다. 하지만 데이터가 작은 경우 모든 쓰기의 연산이 하나의 노드에서 처리되며 나머지 노드는 유후(Idle)상태가 된다.
6. 라우팅 요청(Request Routing)
리밸런싱이 필요하고 멋지지만 비싼 작업인건 확인해보았다. 그럼 이렇게 수동/자동 혹은 고정/동적인 리밸런싱 과정 속에서 데이터 읽기/쓰기에 대한 요청이 들어왔을 때 누가 중재해줄 것인가에 대한 질문이 자동으로 생긴다. 이를 Service Discovery 라고 한다.
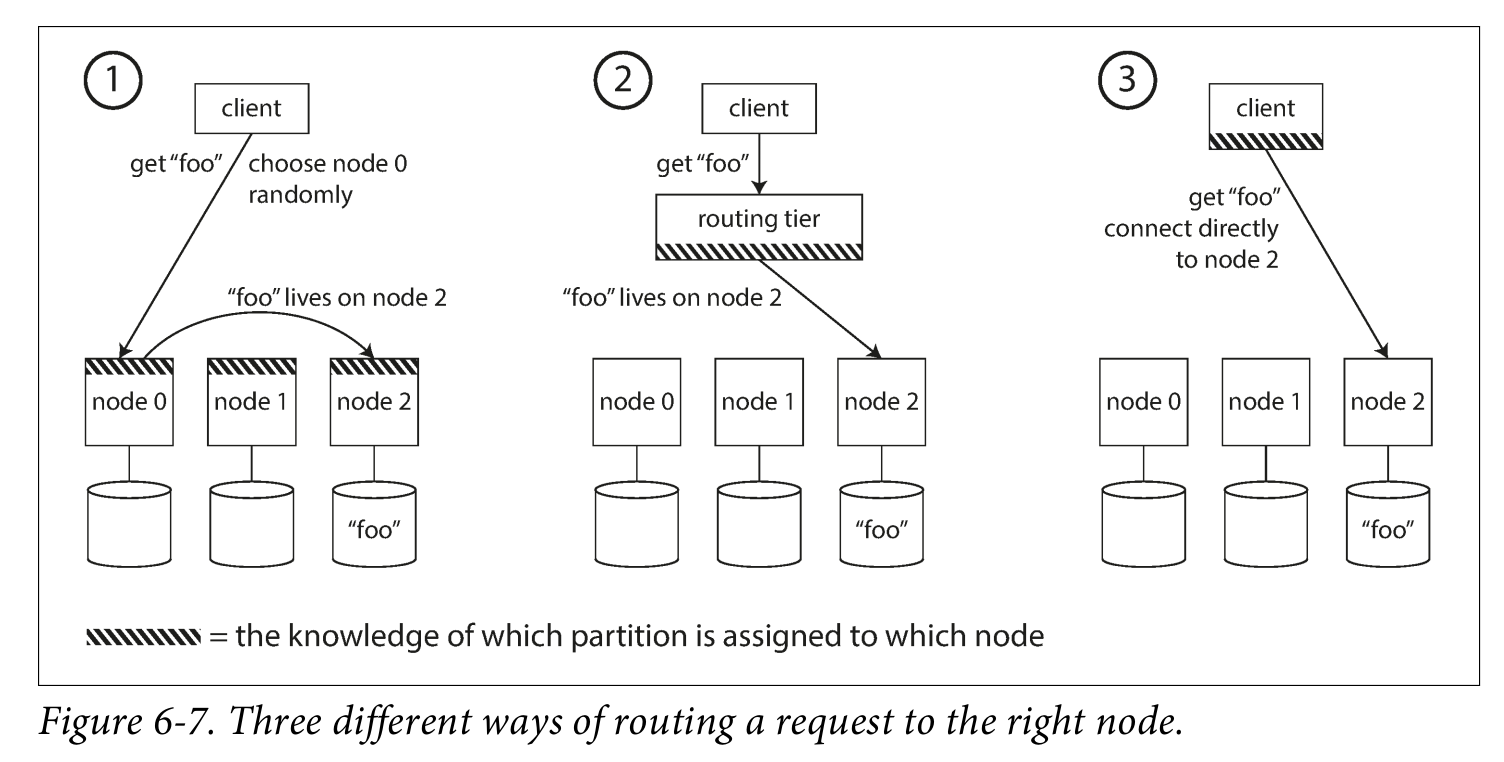
아마 합리적인 방법은 각 파티션이 가지고 있는 key range에 대한 정보를 저장하는 것이고 이를 ZooKeeper 라고 한다.
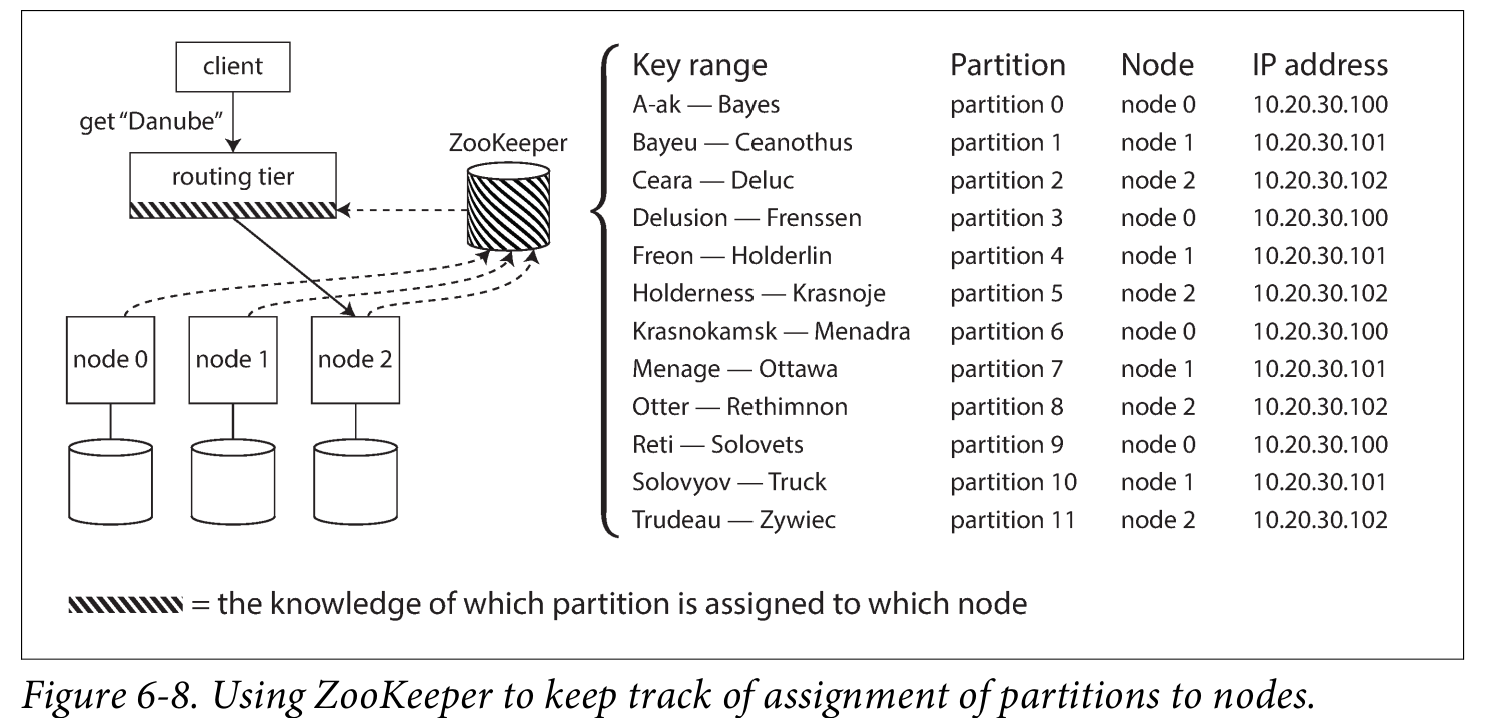
7. 마무리
사실 데이터에 쿼리를 날려만 봤지 대용량 데이터를 저장하는 설계쪽에서는 생각해본적이 거의 없다. 데이터의 무결성과 정합성을 지키기위한 방법부터 초기 데이터베이스에서 확장가능하면서 성능을 최적화하기 위한 파티셔닝 그리고 그 파티셔닝을 운영단계에서 리밸런싱 하는 과정 등을 한번에 볼 수 있는 너무나 좋은 단원이라고 생각되었다. 물론 SaaS 서비스에서는 이를 서비스에 맡기고 인간의 개입은 최소화하겠지만 이런 이론들을 알고 공부할 수 있는 이 책의 전개 흐름과 다이어그램이 너무 좋았다. 또또 공부해보고 싶은 마음이 든다.
이 단원을 통해 앞으로 알았으면 좋겠는 것들은 다음과 같다.
- 대용량 데이터에서 파티셔닝의 중요성과 관리 서비스
- SQL 윈도우 함수에서 파티셔닝을 수행할 때 쿼리 최적화 과정
8. 참고자료
'Data Science > 데이터 중심 어플리케이션 설계(DDIA)' 카테고리의 다른 글
| DDIA Chapter 8: 분산 시스템의 골칫거리 (0) | 2025.03.28 |
|---|---|
| DDIA Chapter 3: 저장소와 검색 (1) | 2025.02.21 |
| DDIA Chapter 2: 데이터 모델과 질의 언어 (0) | 2025.02.15 |
| DDIA Chapter 1: 신뢰할 수 있고 확장 가능하며 유지보수 하기 쉬운 어플리케이션 (1) | 2025.02.05 |



