
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 데분
- 정형데이터
- 영어연설
- 대중연설
- publicspeaking
- 토스트마스터
- CC#5
- 엘뱌키안
- 구글#빅쿼리#데이터분석
- 사이허브
- 데이터
- 공유경제
- 영화
- CC#3
- Toastmaster
- 임상통계
- SQLD
- 2018계획
- 평창
- F분포
- 인과추론
- 풀러스
- 카이제곱분포
- 연설
- 데이터분석
- 분석
- Public Speaking
- 취업
- PGTM
- 제약
- Today
- Total
지지플랏의 DataScience
DDIA Chapter 2: 데이터 모델과 질의 언어 본문
대부분의 데이터분석의 자료의 출처는 관계형 데이터베이스(RDB)를 말합니다. 정형데이터를 관리할 수 있는 Standard로 여겨졌고 실제로도 Oracle을 필두로한 데이터베이스 시스템이 과거 주류를 차지했습니다. 하지만 RDB의 정규화의 특징으로 나타나는 문제들이 발생할 수 있고 그에 따라 파생된 NoSQL 데이터 모델들이 등장했습니다. 이번 글에서는 데이터 모델의 역사와 종류 그리고 어플리케이션을 설계할 때 있어서 어떤 데이터 모델을 선택해야하는지에 대한 근거를 알아보도록 하겠습니다. 본 글에서는 New, Difficulty, Amendment 형식에 따라 작성하겠습니다.

1. 관계형 데이터베이스
관계형 데이터베이스(RDB)는 1980년대부터 약 30년간 주류를 이뤄왔습니다. 트랜잭션(transection)는 데이터베이스의 상태를 변경시키는 작업단위로, 원자성(Atomicity), 일관성(Consistency), 격리성(Isolation), 지속성(Durability) 의 ACID의 개념을 중심으로한 특징을 가지고 있으며 다음 링크에 잘 설명되어있습니다.
트랜잭션이란? 특징과 사용법에 대해 쉽게 알아보자
트랜잭션(Transaction)트랜잭션은 DB의 상태를 변경시키기 위해 수행하는 작업 단위입니다.여기서 DB의 상태를 변경시킨다는 SELECT, UPDATE, INSERT, DELETE 와 같은 쿼리를 날려 연산을 수행하는 것입니다.
hstory0208.tistory.com
비즈니스 데이터 처리에 중점을 둔 RDB가 장기간 집권하였습니다. 반면, 컴퓨터를 더 다양한 목적으로 사용함에 따라 쓰기 확장성, 특수 질의, 동적이고 풍부한 표현력을 가진 데이터베이스 니즈에 따라 2010년 NoSQL의 탄생이 이루어졌습니다. 다음은 링크드인을 예시로하는 링크드인 예시로 보는 관계형과 문서형 DB의 구조 차이입니다.

3. 문서형 데이터베이스
관계형 데이터베이스의 Schema는 엄격하지만 또한 성능의 저하도 일으키는 문제를 가지고 있습니다. 예컨데 ALTER TABLE을 통한 스키마 변경을 위해서는 테이블 사용을 중단해야하는 등의 이슈가 있습니다. 이를 대안으로 가져온 Schemaless한 구조가 NoSQL이였고 Elasticc Search 가 대표적인 서비스로 Kibana는 이와 호환되는 시각화 툴 입니다.


(Amendment) 실제로현대에는 관계형 데이터베이스와 문서형 데이터베이스의 혼합이 이루어지고 있으며, 종종 프로젝트 주제로 나오는 starbuck 데이터에서 Table안에 JSON 형식을 가지고 있는 것이 생각났습니다. 또한 빅쿼리의 구조체(Structure)도 이런 일환 중 하나일까 생각이 들었습니다.


- 데이터를 위한 질의 언어
질의 언어는 SQL와 같은 선언형 질의 언어와 흔히 말하는 프로그래밍과 유사한 명령형 코드로 나눌 수 있습니다. 명령어는 특정 순서로 연산을 하게끔 구체적으로 지시합니다. Loop을 돌리며 조건을 만족하는지 판단하고 추가 Loop를 지속하거나 중단하는 등의 분기점을 나눕니다. 반면 선언형 질의언어에서는 방법이 아닌 알고자하는 패턴에 대해서 기술하게 됩니다. 다음은 선언형 질의언어의 예시인 SQL 의 문법 구조입니다.
SELECT {컬럼}, {집계함수}
FROM {테이블}
WHERE {조건}
GROUP BY {컬럼}이 점에서 SQL이 LLM의 자연어 질의와 비슷하다고 생각했습니다. 두 질의언어 모두 구체적인 명령이나 절차에 대해서 명시하지 않으며 상징적으로 선언하며 그 내부의 로직을 LLM이나 쿼리최적화에 맡긴다는 점이 공통적이였기 때문입니다. 또한, 웹에서 CSS 선택자(selector), XPATH 표현식 역시 선언형 질의언어라는 형식이라는 것이 재미있었네요.
4. 그래프 데이터베이스
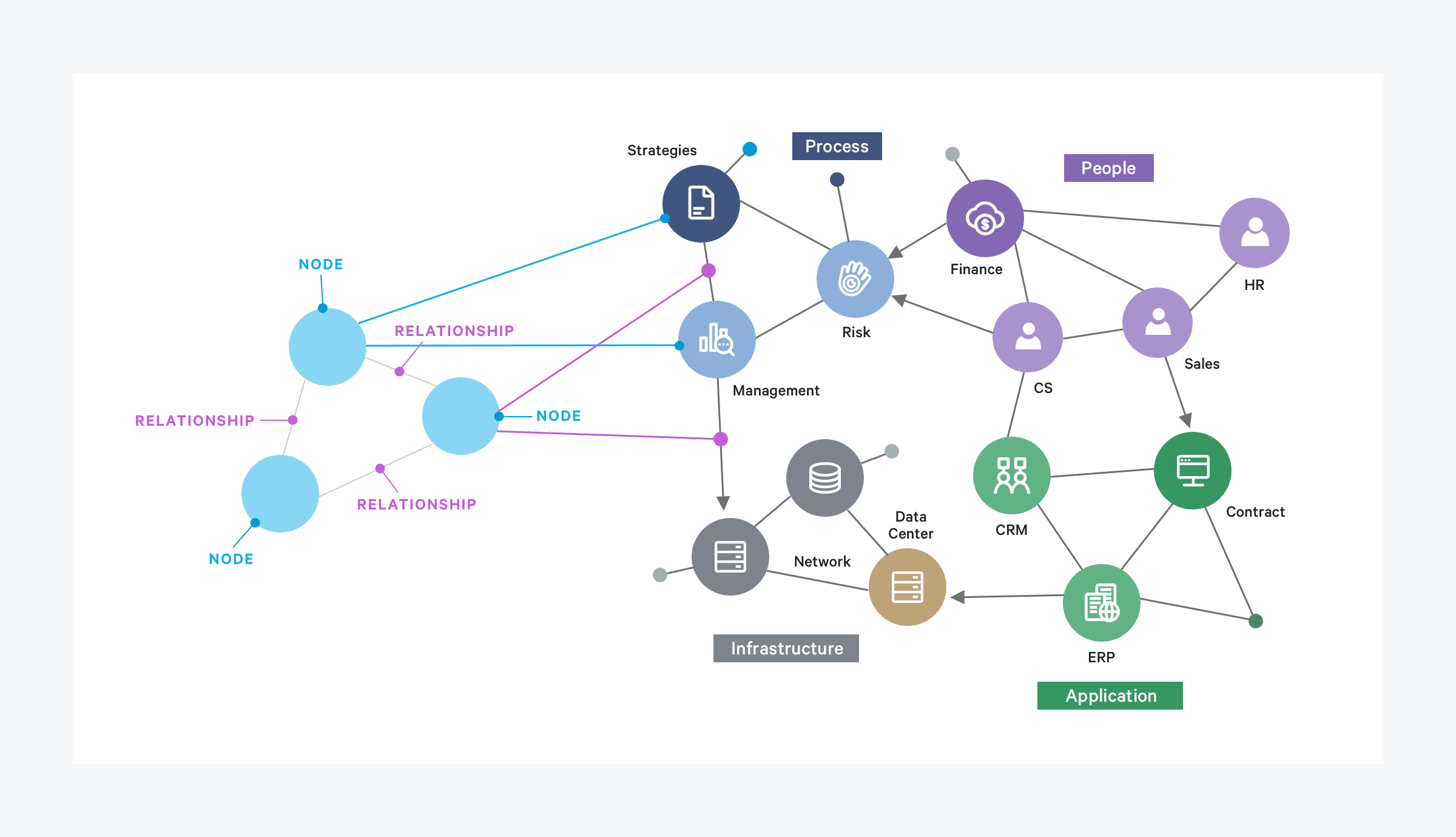
어플리케이션이 주로 일대다 관계이거나 레코드 간에 관계가 없다면 문서 모델이 적합 할 것입니다. 하지만 다대다 관계가 일반적인 소셜네트워크와 같은 경우면 그래프형 모델링이 더 자연스럽다고 할 수 있겠습니다. 그래프는 Vertex(정점 혹은 노드, 엔터티라고 불림)과 Edge(간선 혹은 관계)의 개념을 중심으로 하는 모델입니다. 예를 들어 자동차 네비게이션과 같이 도로 네트워크에서 두 지점간 최단 경로를 검색하는 등의 동작이 그래프 모델의 활용 방법이 될 수 있으며 그래프의 장점은 동종 데이터에 국한되지 않는다는 점입니다.
01-1 그래픽 데이터베이스란 ?
[TOC] 그래픽 데이터베이스를 설명하기 위해서는 기존의 관계형 데이터베이스와의 차이를 살펴볼 필요가 있다. 관계형 데이터베이스는 SQL이라는 쿼리를 사용하며 데이터는 테이…
wikidocs.net
- (New) 그래프 데이터베이스 Neo4j
Neo4j 의 핵심개념은 노드(Node), 관계(Relationship), 속성(Properties), 라벨(Label)등으로 이루어져있으며, Cypher 쿼리 언어로 노드와 관계를 탐색하고 조작합니다. 대표적으로 Cypher 쿼리 언어의 코드는 다음과 같습니다.
1. 노드 생성
CREATE (n:Person {name: '홍길동', age: 30})2. 관계 생성
MATCH (a:Person {name: '홍길동'}), (b:Company {name: 'ABC기업'}) CREATE (a)-[:WORKS_AT]->(b)3. 데이터 조회
MATCH (n:Person)-[:FRIEND_OF]->(friend) WHERE n.name = '홍길동' RETURN friend.name4. 데이터 업데이트
MATCH (n:Person {name: '홍길동'}) SET n.age = 315. 노드 및 관계 삭제
MATCH (n:Person {name: '홍길동'}) DETACH DELETE n
5. 데이터 모델의 차이점
| 관계형 데이터베이스 | 문서형 데이터베이스 | 그래프 데이터베이스 | |
| 핵심키워드 | SQL, 정규화, 테이블, 관계 | JSON, 비정형 데이터, Schemaless | Vertex, Edge |
| 장점 | 강력한 데이터 무결성, 복잡한 쿼리(SQL) 가능, 데이터 구조가 명확함 | 유연한 스키마, 직관적인 데이터 저장 가능, 수평 확장 용이 | 복잡한 관계(N:N) 데이터 빠르게 탐색, 네트워크 분석 |
| 단점 | 스키마 변경 어려움, 대규모 데이터 처리 시 성능 저하 | 데이터 중복 가능성, N:1 관계 적합하지 않음 | 대규모 데이터셋에서 성능 튜닝 필요 |
| 사용 예시 | 금융 시스템, 전통적인 웹 어플리케이션 백엔드(MySQL) | 콘텐츠 관리 시스템, 로그 및 이벤트 데이터, 전자상거래(MongoDB) | 추천시스템, 지식 그래프 |
종합적으로 각 데이터 모델을 살펴보니 어플리케이션의 목적에 따라 데이터 모델을 선택해야하는 점을 명확히 할 수 있었습니다. 고전적인 비즈니스 데이터 처리에는 관계형 데이터베이스를 컨텐츠 보관과 schemaless한 빠른 저장은 문서형 데이터 베이스, 다대다 관계를 염두에 둔 처리는 그래프 데이터베이스를 선택해야할 것입니다. 모호한 데이터 모델들에 대해서 이해할 수 있는 과목이였고, 물론 그래프 데이터베이스를 직접 마주한 적은 없어서 모호한 면이 있었지만 재미있게 읽었습니다.
'Data Science > 데이터 중심 어플리케이션 설계(DDIA)' 카테고리의 다른 글
| DDIA Chapter 8: 분산 시스템의 골칫거리 (0) | 2025.03.28 |
|---|---|
| DDIA Chapter 6: 파티셔닝 (0) | 2025.03.15 |
| DDIA Chapter 3: 저장소와 검색 (1) | 2025.02.21 |
| DDIA Chapter 1: 신뢰할 수 있고 확장 가능하며 유지보수 하기 쉬운 어플리케이션 (1) | 2025.02.05 |



