솔직히 말이죠 이런 책을 읽는다는게 쉽지만은 않습니다만, 특히 이번장에서는 데이베이스의 저장구조와 검색에 대한 테크니컬한 내용이 많이 들어가서 중간에 도망갈뻔 했습니다. 그런데 참고 읽다보니 OLTP와 OLAP에 대한 구조가 너무나도 비교가 잘되었고 최근(?) 유행하게 되었는 칼럼 데이터베이스도 눈 여겨볼 수 있는 좋은 단원이였습니다. 얼마나 좋았나면 분석하는 분들에게 일부 문단을 뜯어서 읽어주고 싶은 느낌이였어요. 필자는 2장에서는 어플리케이션 개발자가 데이터 베이스에 데이터를 제공하는 형식을 설명한다면 3장은 데이터베이스 관점에서 데이터를 저장하는 방법과 요청했을 때 다시 찾을 수 있는 방법에 대해서 안내하고 있습니다. 한번 가보시죠~
신규개념
개념
설명
로그(Log)
컴퓨터 시스템과 네트워크에서 발생하는 활동과 사건에 대한 기록
컴팩션(Compaction)
로그에서 중복된 키를 버리고 각 키의 최신 갱신 값만 유지하는 것을 의미한다.
오버헤드(overhead)
어떤 처리를 하기위해 들어가는 간접적인 처리시간
오프셋(offset)
두번째 주소를 만들기 위해 기준이 되는 주소에 더해진 값(like 상대주소)
병합정렬(mergesort)
하나의 리스트를 균등한 크기로 분할을 하고, 분할된 부분을 정렬한뒤 합치면서 전체 정렬하는 방법
SS테이블(Sorted String Table)
세그먼트 파일 형식에서 키-값 쌍을 가진 테이블 형태의 데이터 구조
LSM 트리
Log Structed merge Tree, 정렬된 파일 병함과 컴팩션 원리를 기반으로 하는 저장소 엔진
OLTP
Online Transaction Processing,인터넷을 통해 많은 사람들이 동시에 데이터베이스를 처리하는 시스템
OLAP
Online Analytical Processing, 온라인상에서 데이터를 분석 처리하는 기술
데이터 웨어하우스
Data Warehouse, 다양한 데이터 소스에서 데이터를 추출, 변환, 요약하여 사용자에게 제공할 수 있는 데이터베이스의 집합체
1. 해시색인, B-tree
(New) 데이터베이스를 가장 쉽게 만드는 방법은 키-값 저장소의 형태로 로그(log)처럼 추가 전용(append only)한 특성을 사용할 수 있다. 하지만 레코드가 많을수록 검색의 비용은 O(n)이기 때문에 성능 최적화 측면에서 바람직하진 않다. 따라서 색인(index)를 이용할 수 있다. 색인은 기본 데이터의 파생된 추가적인 구조이기 때문에, 내용에는 영향을 미치지 않지만 단지 질의 성능에만 영향을 준다.
갑자기 생각난건데, 내가 입사한 회사에서는 의료처방기록을 나라에서 공급받아 분석했었는데, 인덱스가 걸려있는 컬럼이 환자 식별자에만 걸려있냐고 물어보니까, 그냥 모든 컬럼을 걸었다고 답변받았던 기억이난다. 이유는 데이터가 실시간도 아니고 행이 몇 억개밖에 안되어서 그렇다고...
key-value 저장소는 보통 해시 맵(has map)으로 구현하며, 색인 전략은 키를 데이터 파일의 바이트 오프셋에 매핑해 인메모리 해시 맵을 유지하는 전략이다.
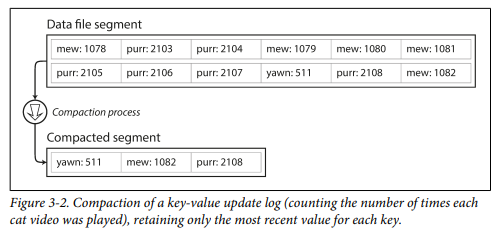
하지만 파일에 항상 추가만 한다면 결국 디스크 공간이 부족해진다. 이는 특정 크기의 세그멘트(segment)로 나누는 방식이 좋은 해결책이다. 이를 컴팩션(compaction)을 수행하여 해결할 수 있다. 컴팩션은 로그에서 중복된 키를 버리고 각 키의 최신 갱신 값만 유지하는 것을 의미한다.
고양이(mew) 동영상의 조회수가 1082 최신값으로 업데이트
내가 운영하는 마인크래프트 서버도 latest.log파일에 저장이 되고 일정 수준이 넘어가면 2025-02-21-(1), (2)와 같이 Segemet가 저장되는데 이것도 일부의 compaction 이라 할 수 있을까? 생각했지만 정보를 덮어쓰거나 하지 않으므로 거리가 있다고 생각했다.
(궁금한 점) Youtube 도 Compaction을 이용해 조회수를 업데이트 할까? 근데 그럼 1시간 전의 조회수나 24시간의 조회수는 나중 시점에 알 수 없는걸까? 갓 구글이 이런 데이터가 없을리 없을 것 같고...그냥 log별로 따로 저장할까? 책의 예시를 Youtube에 저장하려니 조금 결이 안맞는 것 같은 생각이 든다.
2. SS테이블과 LSM트리
(New) 해시테이블은 메모리에 저장해야하므로 키가 너무 많으면 문제가된다. 무작위 접근이 많이 필요하고 가득찼을 때 확장비용이 비싸기 때문. 또한 해시 테이블은 범위 질의(range query)에 효율적이지 않다. 키를 정렬하여 이를 보완한 것이 정렬된 문자 테이블(Sorted String Table)이다. 세그멘트 병합은 병합정렬과 비슷하다(다음 그림)
(Difficulty) 그리고 이 SS테이블과 memtable(쓰기가 들어오면 인메모리 균형트리 데이터구조?)의 동작의 단점으로 memtable의 가장 최신 쓰기가 손실되어 분리된 로그를 디스크 상에 유지하기 위하여 LSM(log-structed Merge Tree)가 나왔다는데 memtable에서 이해가 멈췄다....
데이터 웨어하우스(Data Warehouse)는 분석가들이 OLTP 작업에 영향을 주지 않고 마음껏 질의할 수 있는 개별 데이터베이스이며, OLTP 시스템에 있는 데이터의 읽기 전용 복사본이다.
솔직히 이 단원을 보기 전까지는 웹어플리케이션에서 발생하는 데이터에 대한 경험이 다소 적었기 때문에 OLTP와 OLAP에 대한 특별한 구분점을 찾지 못하였다. 하지만 OLTP 시스템 자체가 비즈니스 데이터 처리(Ex 전자 상거래)를 위해 즉 서비스 운영을 위해 만들어진 본래의 목적을 가지고 있다면, 분석을 그 자체에서 수행한다는 것은 매우 위험한 일임을 이제야 깨닫게 되었다. 따라서 이를 "복제"하여 데이터의 복사본을 가지고 분석을 수행해야함을 이해할 수 있었고, 또한 분석이라는 쿼리 자체의 특성 예를 들면 일부 컬럼을 가져오고 대량의 행을 가져오는 등의 특성에 필요한 데이터베이스의 설계가 필요한 점을 이해할 수 있었다.
(Amendment) 스타스키마(star schema) 다음 databrick 블로그의 인용문구로 대체!
스타 스키마는 데이터베이스에서 데이터를 정리하는 데 사용하는 다차원적 데이터 모델로, 쉽게 이해하고 분석할 수 있습니다. 스타 스키마는 데이터 웨어하우스, 데이터베이스, 데이터 마트 등의 툴에 적용할 수 있습니다. 스타 스키마는 대규모 데이터 세트에 대한 쿼리를 최적화하도록 설계되었습니다. Ralph Kimball이 1990년대에 도입한 스타 스키마는 반복적 비즈니스 정의의 복제를 줄여 데이터 웨어하우스에서 데이터를 빠르게 집계하고 필터링하도록 지원하므로 데이터 저장, 내역 관리, 데이터 업데이트에 효율적입니다. https://www.databricks.com/kr/glossary/star-schema
5. 컬럼지향 데이터베이스
(New) 대부분의 OLTP는 로우 지향의 방식으로 데이터를 배치. 문서 데이터와비비슷하며, 컬럼 지향 저장소는 칼럼 별로 모든 값을 함께 저장함. 또한 압축에 능함!!
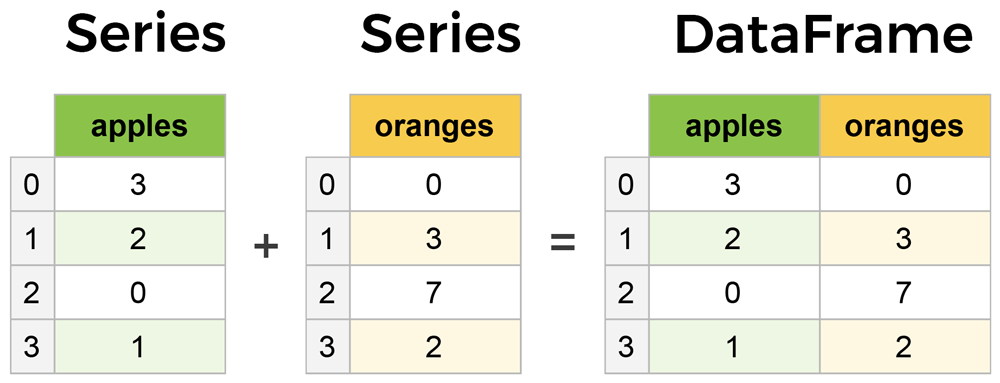
특히, 나는 Pandas라는 모듈을 자주 사용하곤 하는데 이 문단에서 Pandas의 자료형이 생각났다. 해당 모듈에서는 DataFame이라는 행열 구조의 matrix와 Series라는 열구조 2가지의 데이터 자료형을 선언해놓았다. 왜 하필 행 구조가 아닌 열구조인 Series로 선언했을까 고민했을 때 얼핏 보았던, 분석은 컬럼단위로 진행된다는 이 공감이 가서 그렇게 이해했는데 이게 OLAP의 특성과 비슷하다고 생각했다.
6. 마무리
초반에는 지끈지끈 했지만 데이터베이스의 저장과 검색 관점에서 차근히 풀어가는 책의 전개방식이 되게 좋았다. 발생 -> 문제 -> 해결 -> 발전으로 이루어지는 데이터베이스의 발전 방향과 특히 데이터 분석 쪽에 이렇게 연결되어 있는 (책 발간당시는 꽤나 과거) 자료를 이제야 찾다니 그것도 흥미로웠다. 생각보다 어플리케이션 분석은 유래가 오래되었고 이를 잡마켓 수면위로 올라온지 얼마안된 것 뿐이구나 라고 생각했다