
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- 토스트마스터
- CC#3
- publicspeaking
- 분석
- Public Spekaing
- 마케팅 지배사회
- 대중연설
- 사이허브
- Toastmaster
- 제약
- PGTM
- 운송법
- 엘뱌키안
- 평창
- 데분
- 연설
- 영화
- 풀러스
- 취업
- 데이터
- 정형데이터
- SQLD
- 구글#빅쿼리#데이터분석
- 공유경제
- 2018계획
- 영문연설
- 임상통계
- Public Speaking
- CC#5
- 영어연설
- Today
- Total
지지플랏의 DataScience
[글또] 데이터 파이프라인 자동화 구축기 with 농수산물데이터, GCP, crontab 본문
예상독자
- 데이터를 주기적으로 수집하는 자동화를 구현하고 싶은 데이터 엔지니어, 분석가, 개발자
목차
- 글의 개요
- GCP 셋업
- GCP 인스턴스 만들기
- 빅쿼리 연결
- 자동화 익히기
- Linux 스케쥴러 Cron 알아보기
- Hello world 출력하는 실행파일 만들기
- OPEN API 데이터 빅쿼리에 저장 자동화하기
- 깃 설치 및 환경설정
- 파이썬 가상환경 설정 및 패키지 설치
- 스크립트 실행 및 자동화 태우기
1. 글 개요
데이터 수집부터 시작하고자하는 데이터 직무라면 파이프라인에 대해서 고민하게 될 것이다. 다양한 방법이 있겠지만 나는 그렇게 부지런한편이 아니니 가장 간단하게 자동화하고 싶은 마음에 GCP을 사용하기로 했다.

본 글에서는 GCP 서버를 세팅하여(자동화), kamis API에서 데이터를 주기적으로 데이터를 수집하고(수집, 전처리), 이를 데이터베이스에 저장하고(적재) 시각화하여, 제철과일을 싸게 먹겠다(액션 플랜) 라는 목적으로 시작된 사이드 프로젝트이다. 이를 위한 빌드업은 다음 글에 작성하였다.
- 프로젝트 목적: 마트에 있는 딸기 얼마가 합리적인 가격일까?
[분석] 마트에 있는 딸기 얼마가 합리적인 가격일까?
1. 아이디어 흔히 봄에는 딸기철이라고한다. 나와 아내는 봄에 딸기가 출하되면 항상 냉장고에 딸기를 상시...
blog.naver.com
- GCP 세팅을 위한 기본적인 기술지식: GCP 셋업를 위한 기본 지식: 하드웨어와 OS 개념
GCP 셋업를 위한 기본 지식: 하드웨어와 OS 개념
이글을 쓰게된 이유 부트캠프에서 자동화 강의를 준비하다보니 생각보다 컴퓨터 기본 하드웨어 지식이 부족한 사람들이 많다. 컴퓨터 내에 덕지덕지 RAM을 차지하고 있는 프로그램이 있는지 모
snowgot.tistory.com
2. GCP 셋업
✅ GCP 인스턴스 만들기
Google Cloud Console -> Compute Engine에 들어간다.

상단의 인스턴스 만들기를 클릭한다. 여기서 인스턴스란 컴퓨터라고 생각하면 된다.
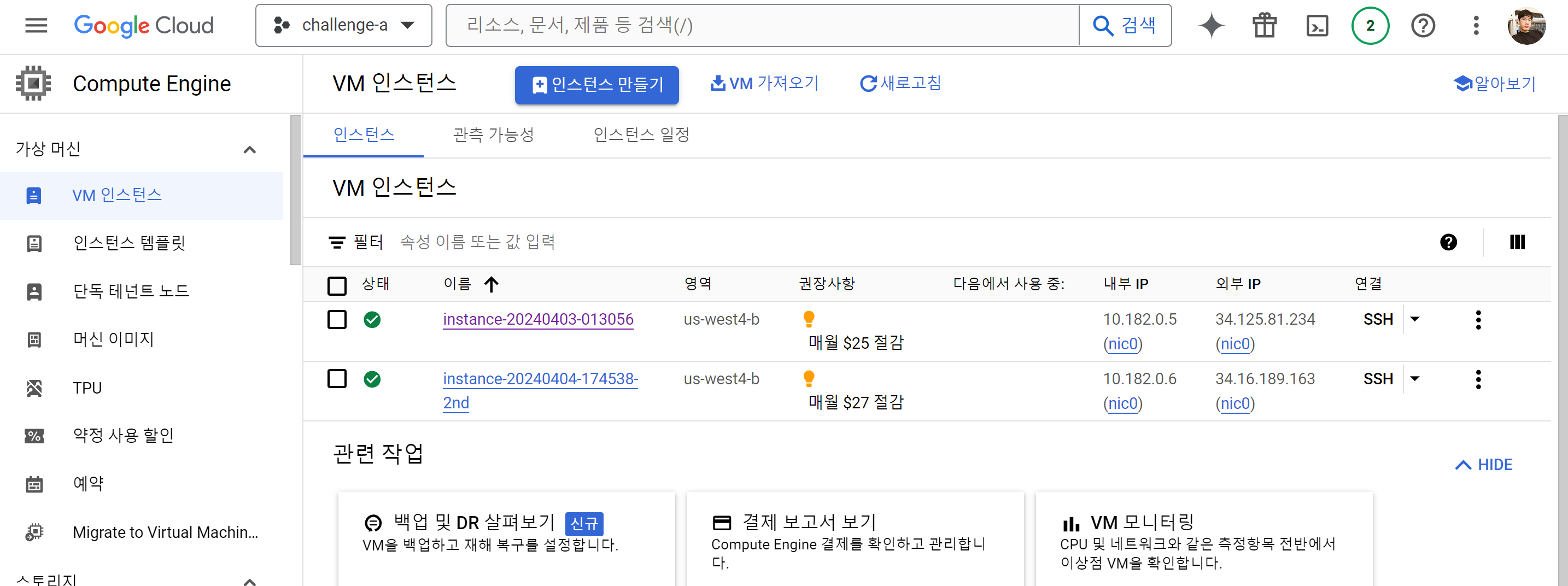
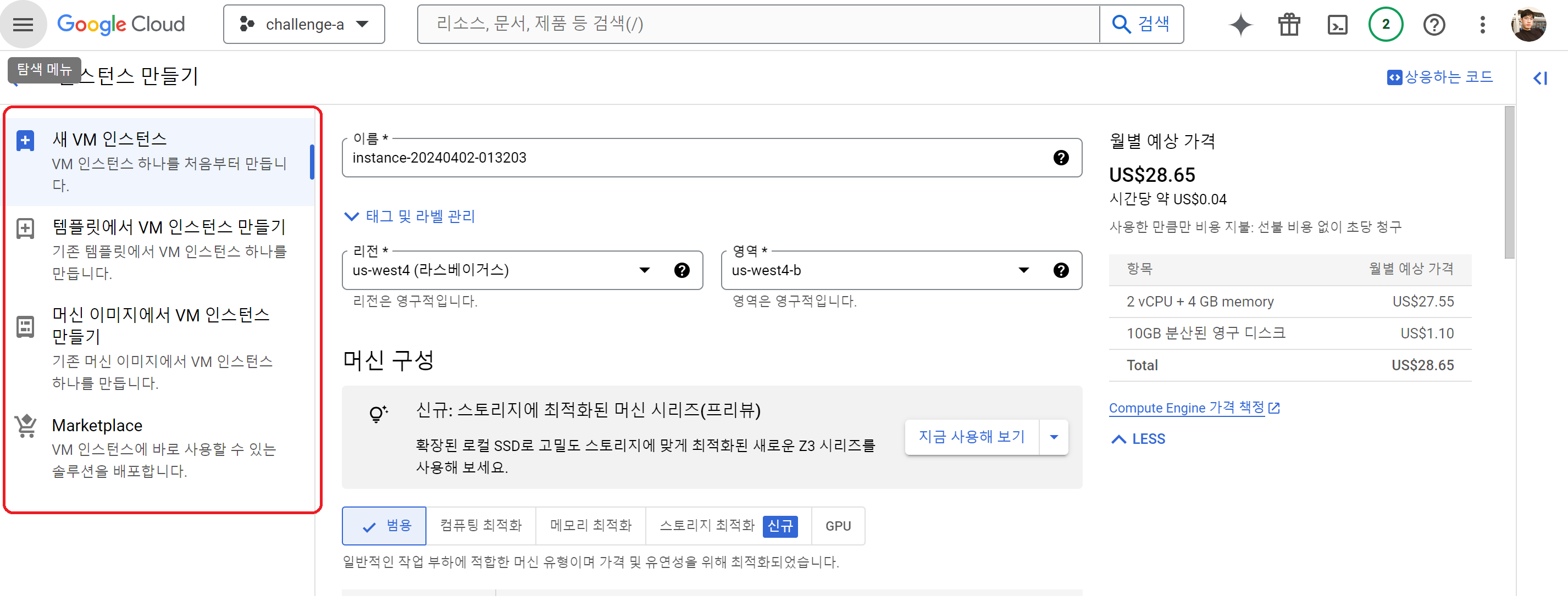
이때 3분할의 화면이 보이는데
- 좌측: 처음부터 셋팅할 것인지 템플릿을 가지고 만들지 선택할 수 있다.
- 우측: 현재 기본 세팅으로 했을 때 나오는 예상 가격이다. 당연하지만 성능이 좋아질수록 가격이 올라간다.
구글로부터 컴퓨터를 "대여" 하는 것이기 때문에 빌리는 것만으로도 비용이 나온다. 마치 집에 있지 않아도 나가는 우리집 관리비 처럼 ~_~ - 중앙: 인스턴스를 셋업하기 위한 상세 설정이다. 사양 등 세부 설정을 할 수 있다.
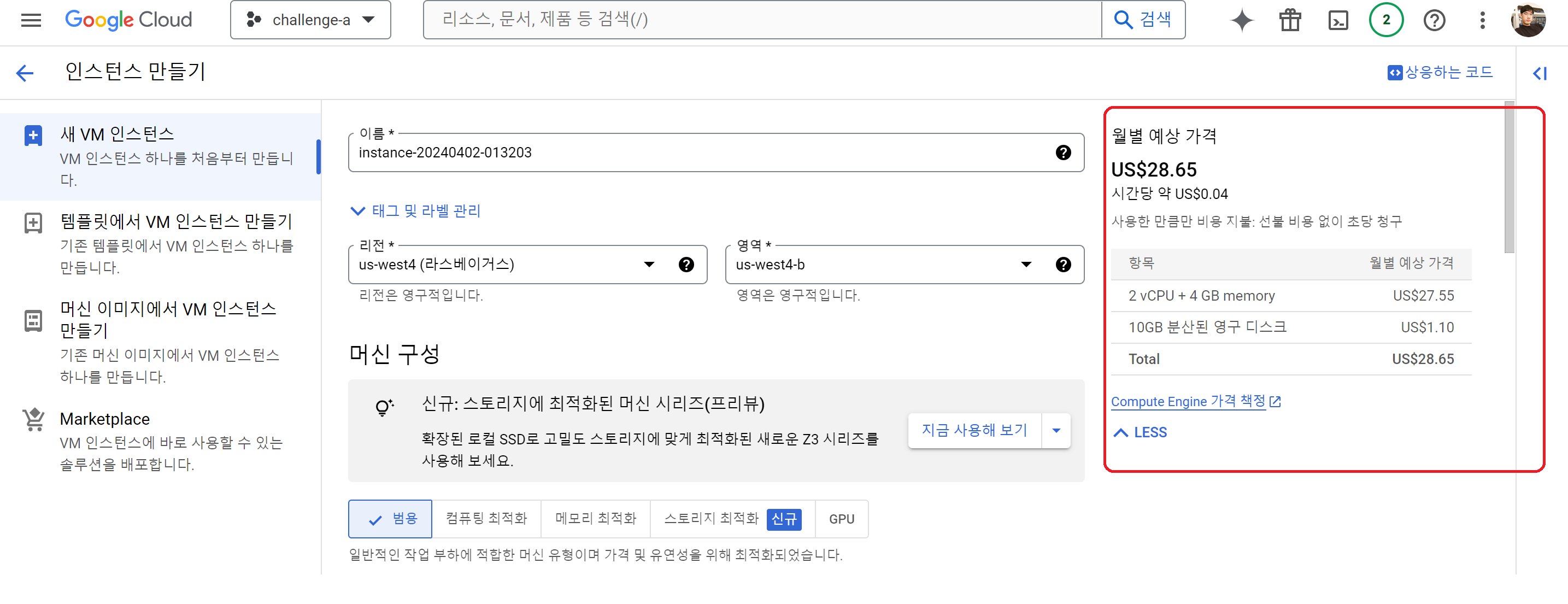
인스턴스 세부 설정에서 확인할만한 사항은 다음과 같다.
- 리전(Regions) : Google Cloud Platform 서비스들이 제공되는 서버의 물리적인 위치
- 영역(Zones) : 리전(Regions) 내 Google Cloud Platform 리소스의 배포 영역
리전과 영역 설정에 따라 예상가격이 달라진다. 서울권을 설정하면 Latency와 같은 부분이 더 좋아질 수 있다고는 하나 공급이 다른 지역보다 적기 때문에 가격이 올라간다. 우리의 경우 Latency가 그렇게 큰 부분은 아니기 때문에 기본지역으로 설정했다.
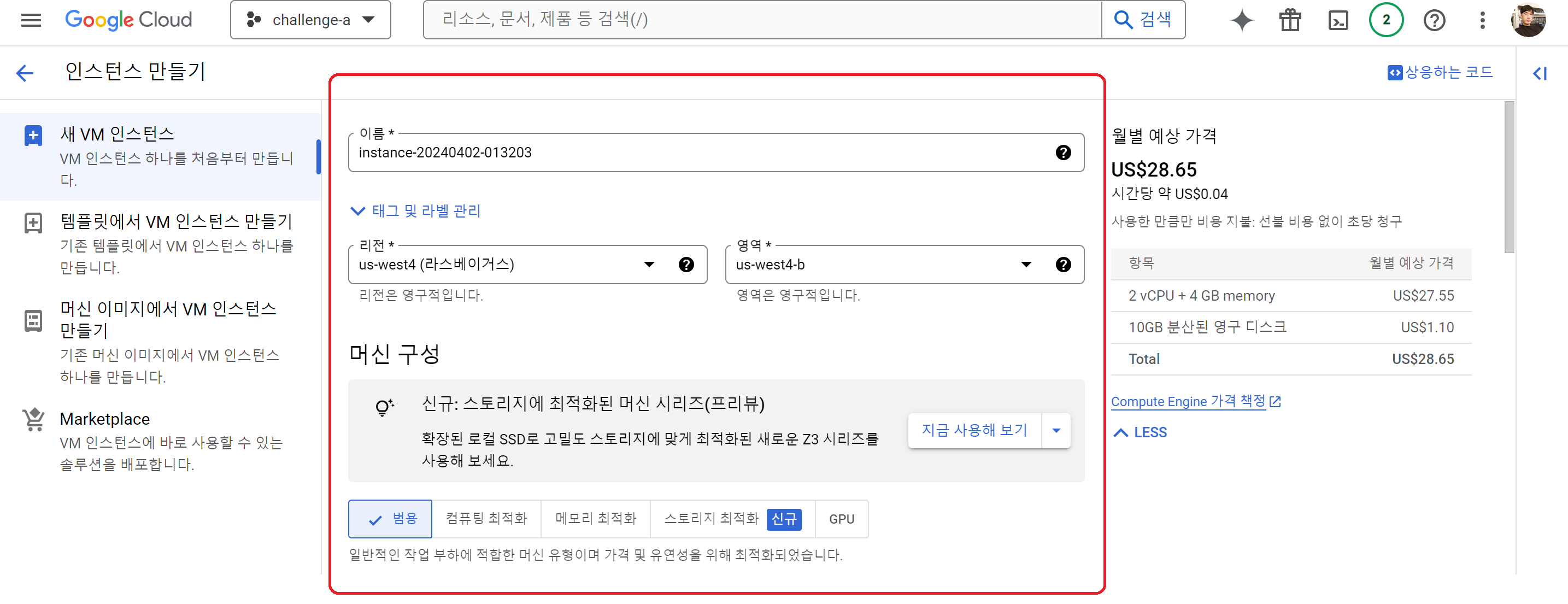
- 머신 구성: 인스턴스 자원 변경 가능
- 부팅디스크: 디스크와 운영체제(리눅스 배포판)을 선택 가능
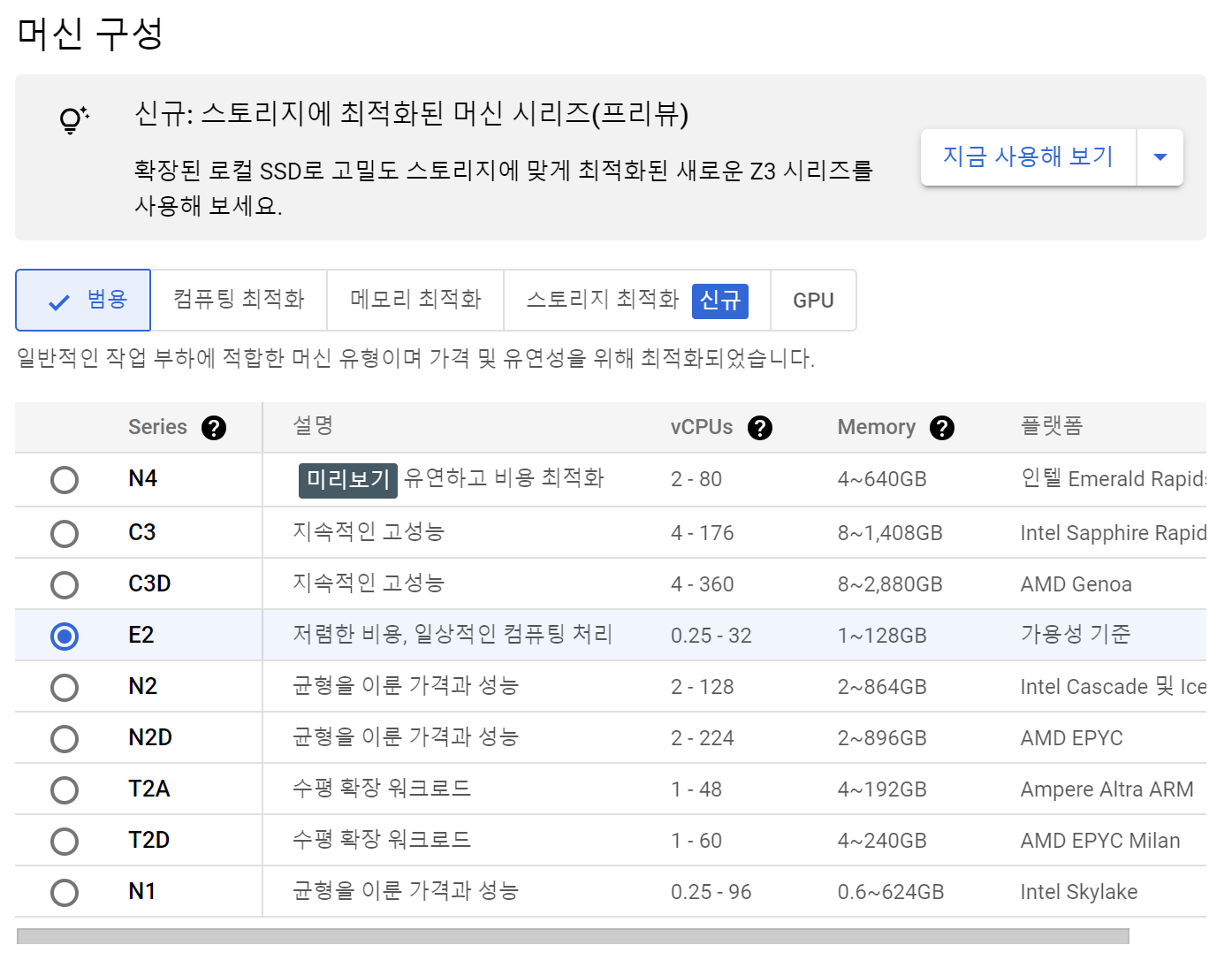

이후 방화벽에서 HTTP 트래픽 허용을 누르고 만들기를 클릭하면 수분 내 인스턴스가 생성된다.
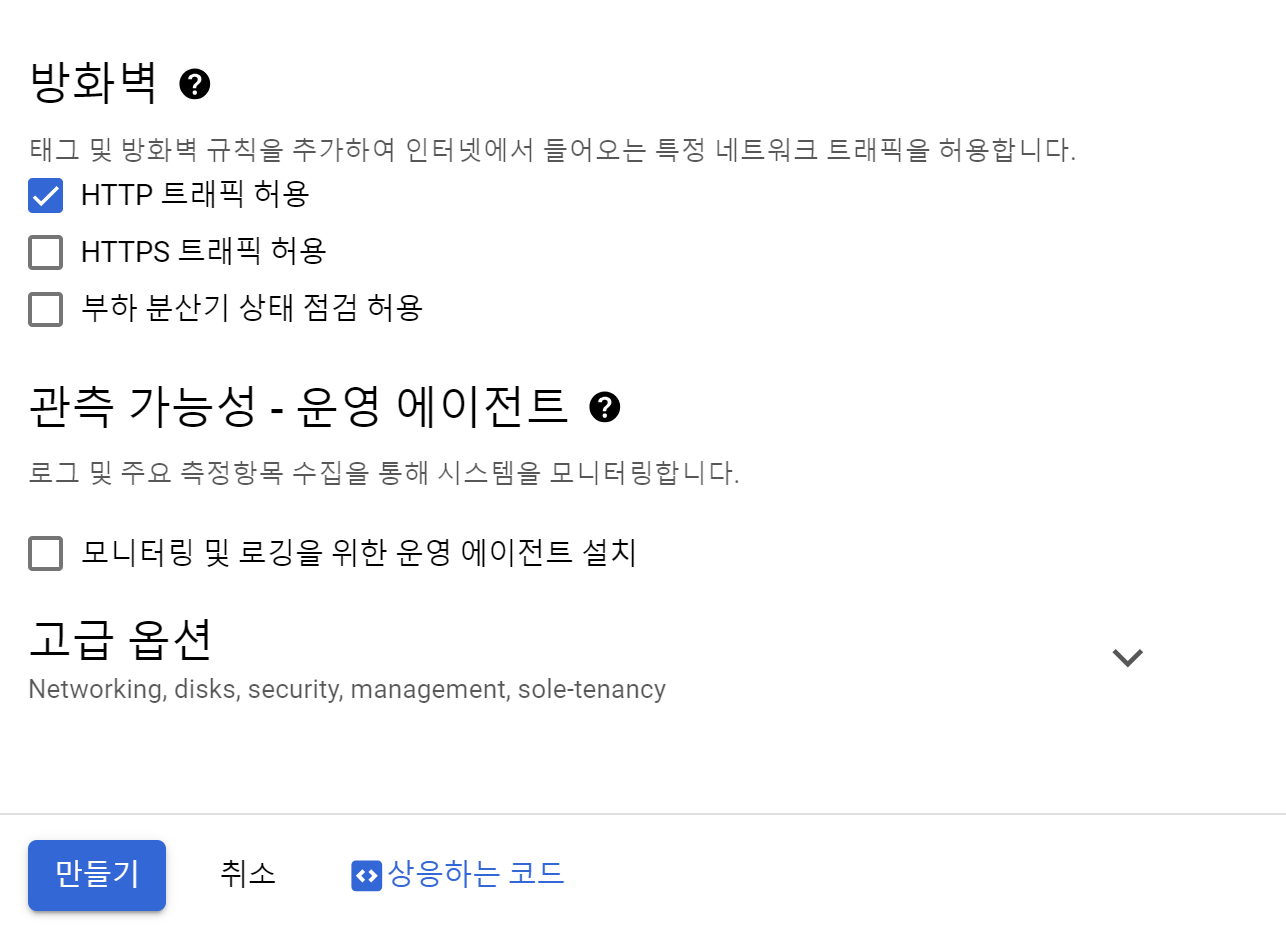
생성이 완료되면 다음과 같이 뜨며, 내부IP, 외부IP와 연결 부분이 생성된다. 내부IP는 말그대로 내부 네트워크(Google 서버내)에서만 접근 가능 하기 때문에 보안이 우수하다. 또한 지연속도가 적고(속도가 빠름) 비용이 저렴한 특징을 가지고 있다. (외부 인터넷을 사용하지 않아도 되니)한 장점이 있습니다. 외부 IP는 우리가 사용하는 인터넷 IP이다.
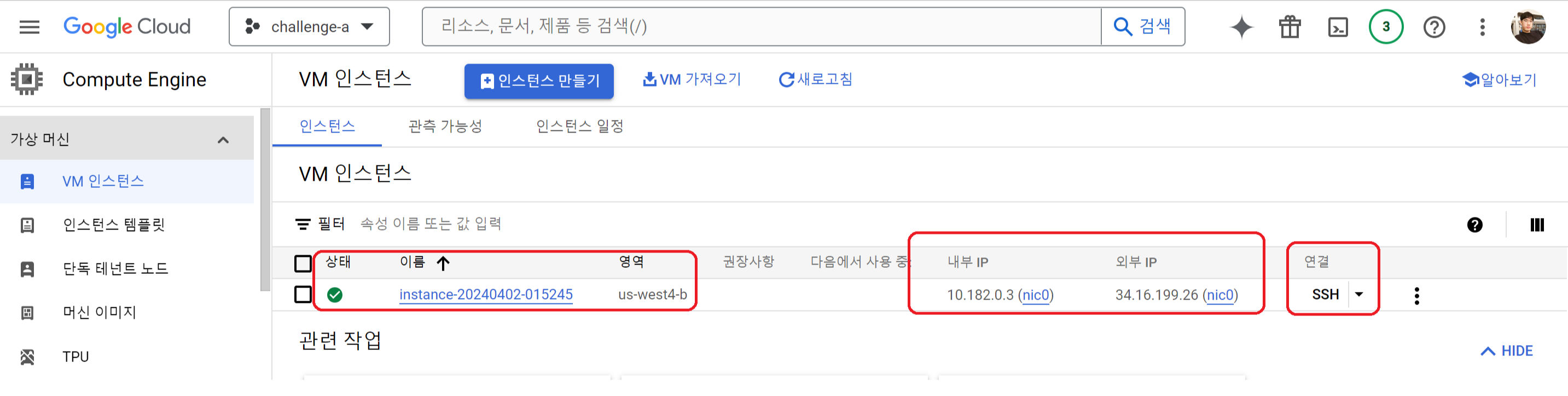
위해서 연결부분의 점 세개를 누르면 브라우저 창에서 열기를 통해 접속이 가능하다.

무료 크레딧으로 인해 과금은 안되지만 추가 비용을 막거나 인스턴스를 내리고 싶다면 같은 방법으로 중지/정지/삭제가 가능하다.
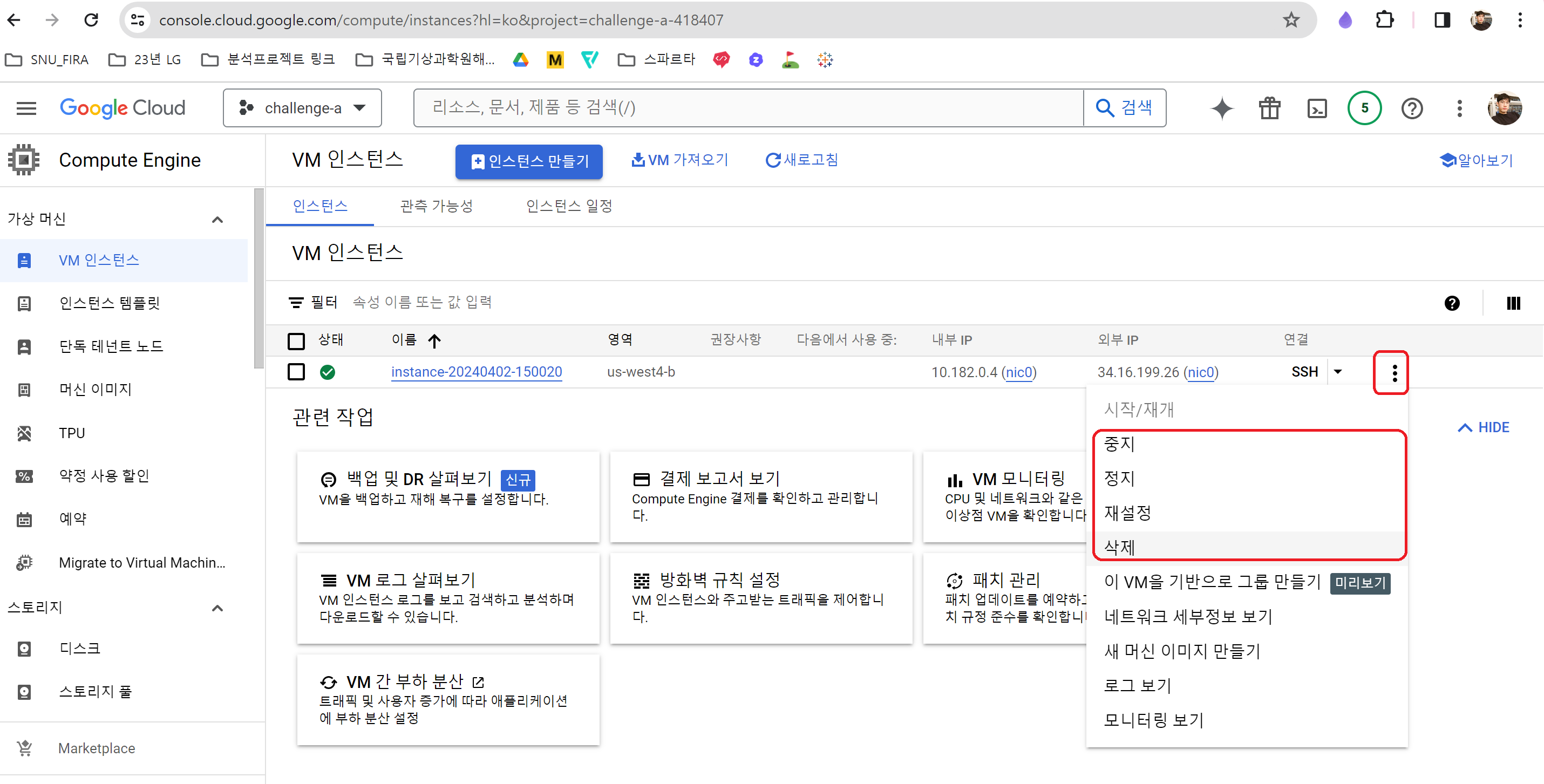
- 중지: 일시정지에 해당하며 OS, 메모리를 그대로 유지하는 상태, 60일 이후 정지로 변경
- 정지: 인스턴스가 종료되며 OS를 종료하게 된다.
더 자세한 내용은 다음 글을 참고해 볼 수 있다.
VM 일시정지 및 재개 | Compute Engine 문서 | Google Cloud
의견 보내기 VM 일시정지 및 재개 컬렉션을 사용해 정리하기 내 환경설정을 기준으로 콘텐츠를 저장하고 분류하세요. Linux Windows 이·문서에서는·가상·머신(VM) 인스턴스를 일시정지·및 재개하
cloud.google.com
[GCE] VM이 중지 / 일시중지 상태일 때 각각 청구되는 비용은?
안녕하세요, 베스핀글로벌 GCP Support팀입니다. 이번 아티클에서는 주제로 "GCE VM의 상태별 청구되는 비용"을 다루고자 합니다. GCE VM의 상태별 청구 비용 GCE VM의 실행이 필요하지 않을 때, 비용을
support.bespinglobal.com
기본적으로 GCP 인스턴스를 생성하면 Python은 깔려있다. 그 외에 필요한 유틸리티는 apt를 통해 직접 설치해야한다.
python3 --version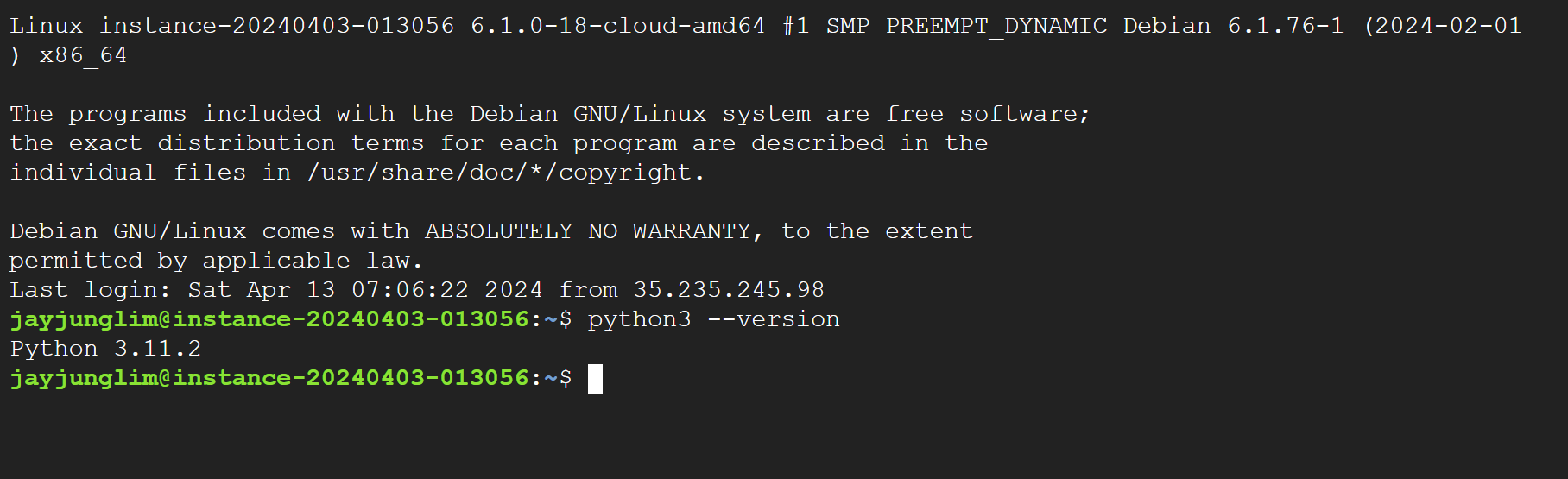
기본적인 리소스 확인도 가능하다. top 유틸리티는 조금 못생겨서, htop을 설치한다.
#기본 자원관리자
top
#htop 설치
sudo apt-get install htop
htop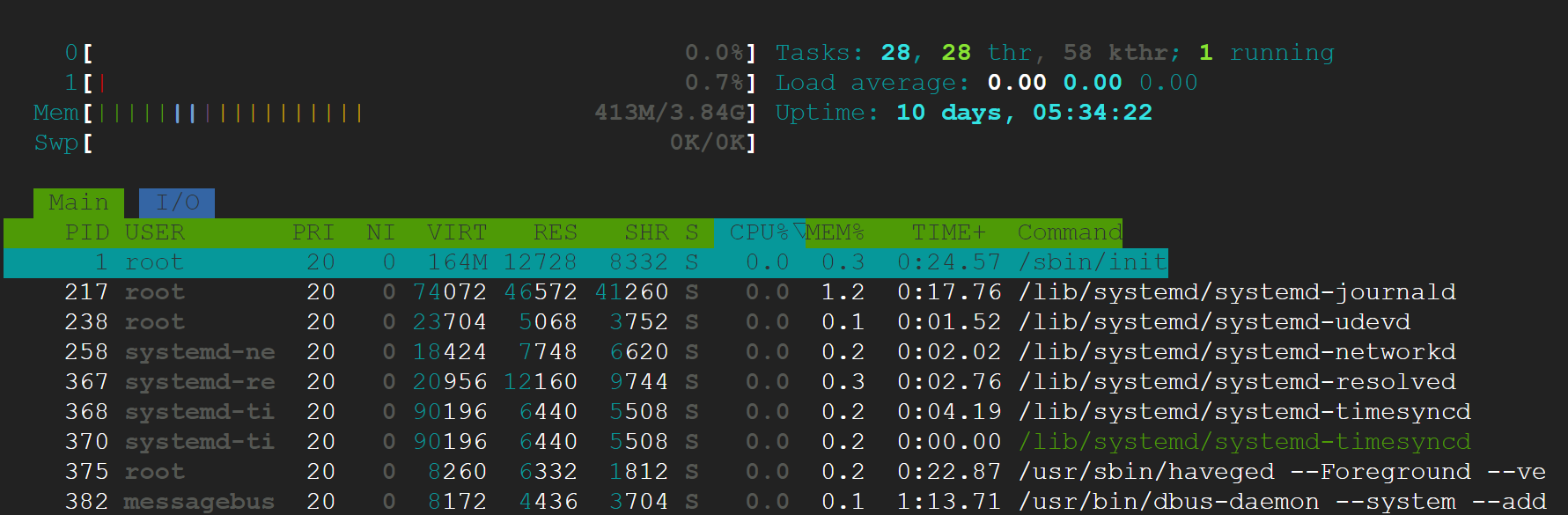
✅ 빅쿼리 연결
같은 Google 제품이다보니 gcloud 명령어가 설정되어있고 손쉽게 bigquery를 연동할 수 있다.
gcloud auth login
#이후 나오는 링크를 통해 인증
#현재 기본프로젝트가 설정되어있지 않다면
#현재 계정에 있는 프로젝트 리스트 확인
gcloud projects list
#프로젝트 선택
gcloud config set project <프로젝트명>나는 kamis.str 데이터를 이미 빅쿼리에 올려놓아서 설정하여 볼 수 있다.
#bq명령어는 빅쿼리를 볼때 사용하는 명렁어
#현재 데이터 셋 확인
bq ls
#현재 데이터셋의 테이블 명확인
# bq ls <데이터셋 명>
bq ls kamis
#SQL 쿼리날리기
# bq query 'SQL 명령어'
bq query --use_legacy_sql=false 'SELECT * FROM `kamis.str`'
3. 자동화 익히기
✅ Linux 스케줄러 Cron 알아보기
gcp 설정을 마쳤다면 Linux 의 스케쥴러인 Cron을 익혀볼 차례다. Cron이란 스케쥴링을 담당하는 Linux 유틸리티로, Crontab은 Cron table의 약자로, 실행할 명령어를 담고있는 파일이다.

- Cron 주기
- * * * * * {실행 명령}
- 순서대로 분(0-59), 시(0-23), 일(0-31), 월(21), 요일(0-6)
- 요일은 0(일), 1(월)… 6(토)
- *은 모든 이라는 뜻이므로
- 예시
- * * * * * {실행명령} : 매 분 마다 실행
- */10 * * * * {실행명령} : 매 10분 마다 실행
- 0 12 * * * {실행명령} : 매일 정오 12시에 실행
- 예시
- crontab 관련 명령어
- which crontab : crontab 위치경로 확인
- crontab -e : 편집
- crontab -l : 작업 내용 확인
- crontab -r : 전체 작업 삭제
Cron 스스로 작동하는게 아니고 sytemctl 이라는 리눅스 서비스 관리프로그램으로 시작과 종료를 시킨다. 따라서 다음 명령어를 사용해야한다. 관리자 권한 sudo 가 필요하다. 또한 Crontab 설정을 변경할 때마다 재시작 해줘야 한다.
-
- systemctl restart cron: cron 재시작
- systemctl start cron : cron 시작
- systemctl stop cron : 중지
- systemctl status cron : 작동확인
✅ Hello world 출력하는 실행파일 만들기
Linux에서 문자를 출력하는 쉘파일(.sh)를 만드는 것은 nano 편집기를 이용해서 .sh 실행파일에서의 출력문인 echo 를 사용하면된다.
#nano 편집기로 만들기
#이름을 정하면 알아서 해당 이름의 파일을 생성
nano hello.sh
#hello.sh 파일에서 다음 내용을 입력
echo "Hello World!"
이후 CTL + X -> Y를 이용해서 nano 편집기 저장 후 나오기를 하면 된다. 이후 .sh 파일을 실행하는 것은 sh 명령어를 사용하면 된다.
sh hello.sh
✅ 매분마다 출력하는 실행파일 만들기
sh 파일을 만들었으니 이를 cron 에 태워서 주기적으로 실행하게 만들면 된다. 이때 설정해야하는 것은 (1) crontab에 해당 sh파일 위치 알려주기 (2) systemlctl을 이용해서 crontab 실행해 주는 것이다.
# 현재 경로확인
pwd
# crontab 편집
crontab -e
# crontab에 매분 해당 파일을 실행하도록 입력
# 동시에 출력을 .log 파일로 보내고
# 2>&1 구문에 따라 오류 메세지도 동일한 파일로 보냄
* * * * * /home/jayjunglim/hello.sh >> /home/jayjunglim/hello.log 2>&1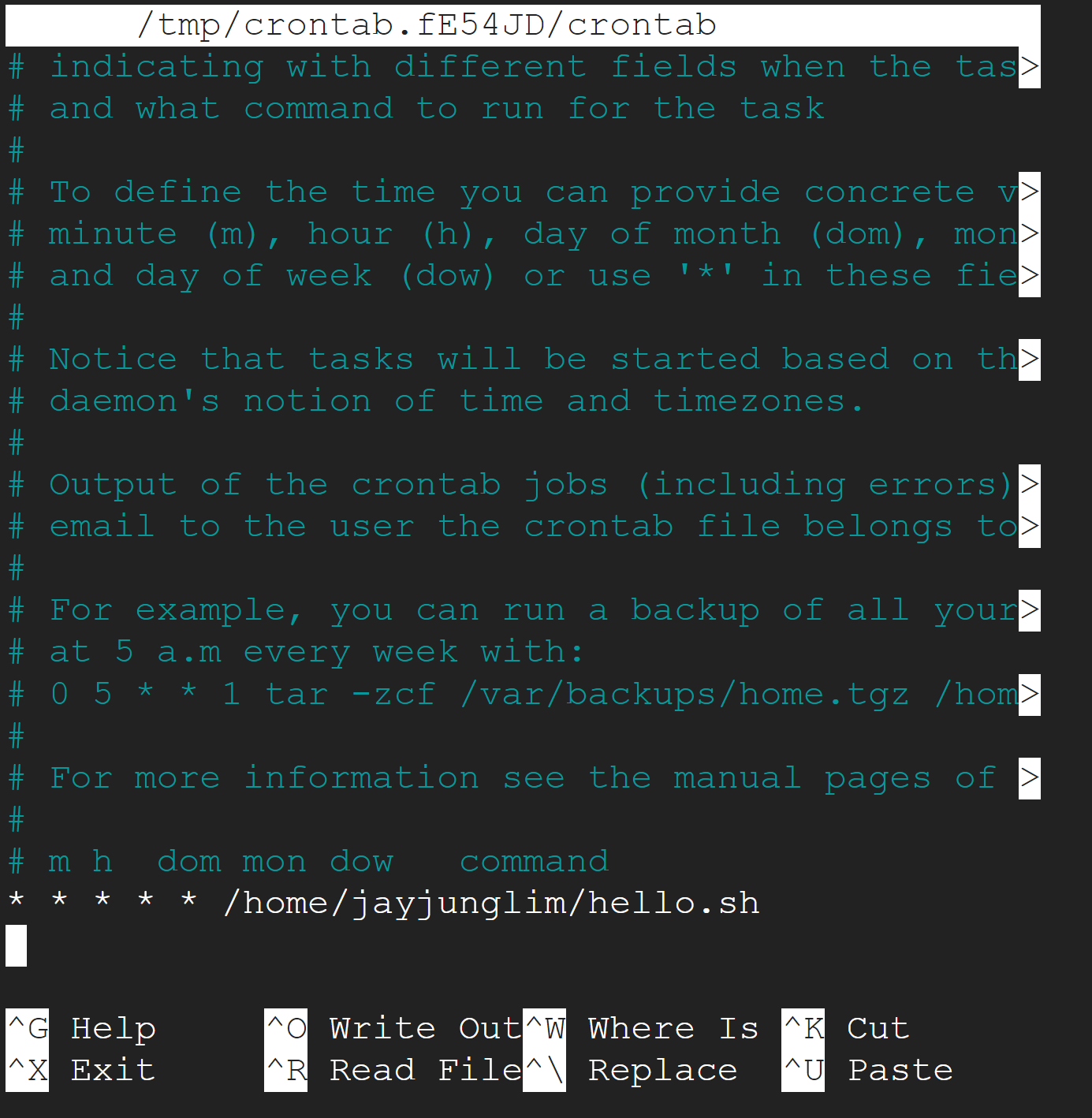
# crontab 나와서 현재 변경내역 확인
crontab -l
#설정한 내용 저장하기 위하여 재부팅
sudo systemctl restart cron
# cron 시작하기
sudo systemctl start cron
# 상태확인
sudo systemctl status cron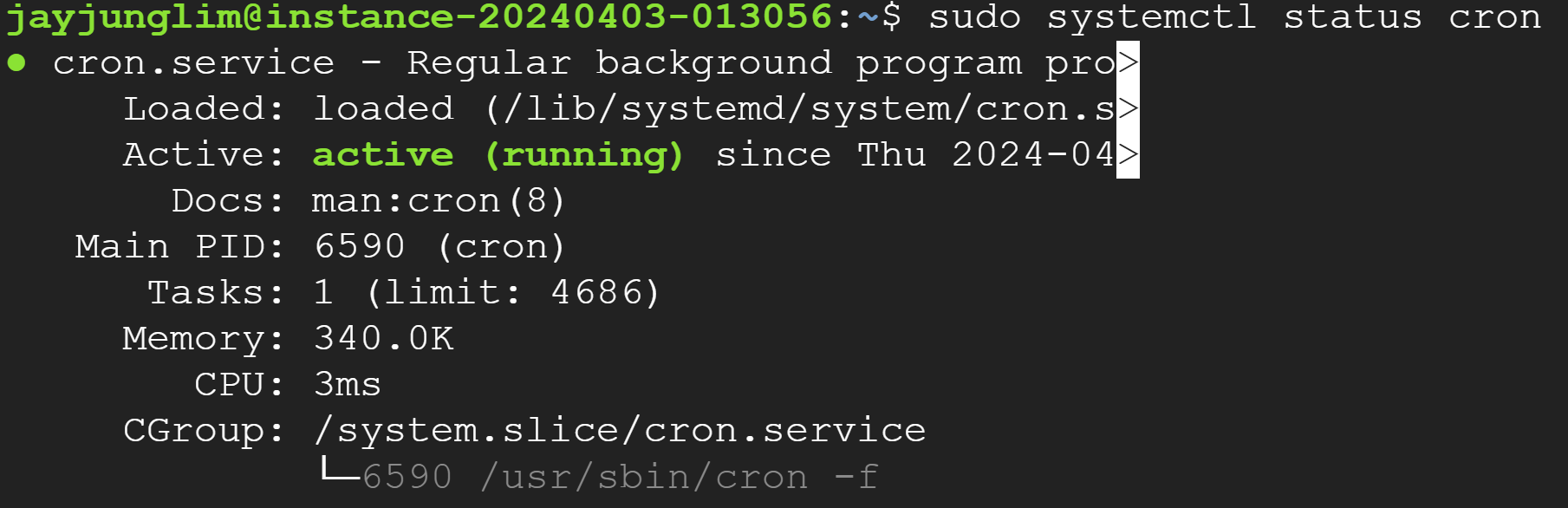
이후 로그 파일을 열어보면 잘 작성됨을 확인할 수 있다.
# 로그 확인
nano hello.log
# cron 종료
sudo systemctl stop cron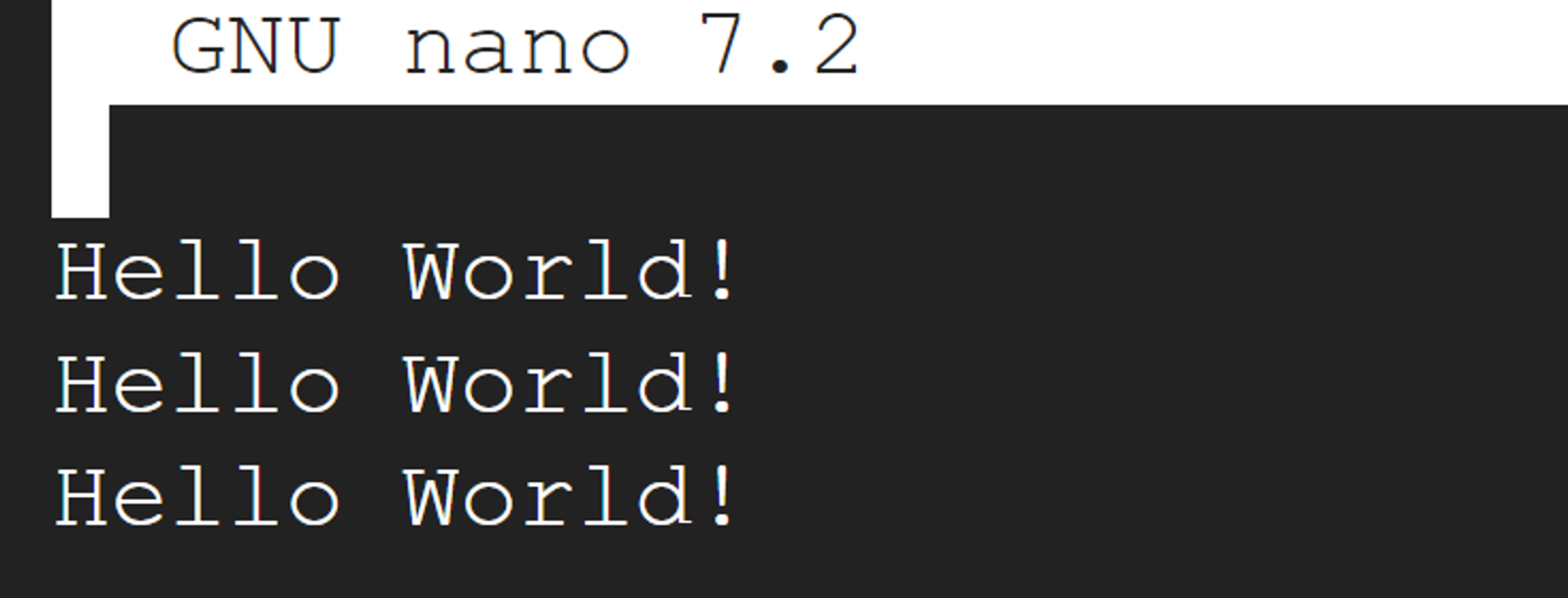
4. OPEN API 데이터 빅쿼리에 저장 자동화하기
이제 이모든 것을 합쳐 OPEN API 로부터 데이터를 가져오고 이를 빅쿼리에 저장할 것이다. 또한 이를 자동화를 태울 것이다. 엄격히 말하면 매일 자동화를 시켜서 누적되는 데이터를 보아야겠지만, 데이터 삭제 & 새로 생성 하는식으로 자동화를 테스트해볼 생각이다.
이전에 환경세팅해줄 것이 몇가지 있다. 먼저 git을 설치하여 github 에 있는 코드 뭉치를 가져올 것이며, python 가상환경 설치를 해야한다.
✅ 깃 설치 및 환경설정
- 깃 설치
# 깃 설치
sudo apt-get install git
#폴더생성
mkdir wheresisplanb
#리포지토리 파일 복사
git clone https://github.com/bellepoque7/whereisplanb.git
#(선택) 만약 repository를 이미 clone하였고, 업데이트 사항이 있다면
git pull https://github.com/bellepoque7/whereisplanb.git해당 리포지토리에서는 데이터를 불러오고 전처리하는 web_api_kamis.py 파일과 이를 빅쿼리에 kamis2bq.py 적재하는 파일을 사용할 예정이다. 만약 빅쿼리가 어색하고 파이썬으로 데이터 적재하는 법을 알고 싶다면 다음 글을 참고한다.
[글또] Google bigquery에 데이터를 적재하고 태블로로 데이터 가져오기
예상독자 로컬 머신와 빅쿼리를 연결해보고 싶은 독자 데이터 적재 자동화를 동해 태블로에 시각화하고 싶은 독자 1. 배경 데이터분석을 넘어 데이터 파이프라인을 만들어 자동화를 하는 경우
snowgot.tistory.com
web_api_kamis 는 농수산물 데이터(kamis)를 가져오기 위한 데이터이며, 이를 빅쿼리에 저장하기 위해서 kamis2bq.py 스크립트를 따로 만들었다. 해당 스크립트는 딸기 데이터에 대하여 데이터를 가져오고 빅쿼리에 데이터가 있다면 삭제하고 업로드 하는식으로 최신화 하는 형태이다.
제일 좋은 건 계속 누적해서 데이터를 수집하는 것이지만 일단 prototype을 만들고 추가 적재를 하기위해서 코드을 추가하기로 하였다.
- kamis2bq.py 스크립트
#GCP debain 환경에서 실행되는 코드
import pandas as pd
from web_api_kamis import *
from google.cloud import bigquery
from google.cloud.exceptions import NotFound
import time
# df_cd = pd.read_csv('./Data/category_detail_code.csv', encoding = 'euc-kr')
#데이터 불러오기 및 전처리
start = time.time()
df_str = kamis_api_2(itemcode ='226')
df_str = df_str.assign(date = lambda x : df_str['연도'] + '/' + df_str['날짜'])
df_str['date'] = pd.to_datetime(df_str['date'], format = 'ISO8601')
df_str = df_str.assign(price_100g = lambda x: x['가격'].str.replace(',','').str.replace('-','0').astype('int')/20)
df_str.columns = ['itemcode','kindcode','countrycode','market','year','origin_date','tot_price','date','price_100g']
print('1/4 데이터 전처리 완료')
#빅쿼리 연결 설정
project_id = 'challenge-a-418407'
client = bigquery.Client(project=project_id)
dataset_id = 'kamis'
table_id = 'str'
full_dataset_id = "{}.{}".format(client.project, dataset_id)
print('2/4 빅쿼리 연결 설정 완료')
#스키마 설정(빅쿼리에 올라갈 데이터 형태)
schema = [
bigquery.SchemaField("itemcode", "STRING"),
bigquery.SchemaField("kindcode", "STRING", mode="NULLABLE"), # NULL 값을 허용
bigquery.SchemaField("countrycode", "STRING"),
bigquery.SchemaField("market", "STRING", mode="NULLABLE"), # NULL 값을 허용
bigquery.SchemaField("year", "STRING"), # 연도가 숫자로만 구성되어 있더라도, 여기서는 문자열로 처리
bigquery.SchemaField("origin_date", "STRING"), # 날짜를 문자열로 처리할 수 있지만, DATE 타입을 사용하는 것이 더 적합할 수 있음
bigquery.SchemaField("tot_price", "STRING"),
bigquery.SchemaField("date", "DATE"), # datetime64[ns] 타입은 BigQuery의 DATE 타입으로 매핑
bigquery.SchemaField("price_100g", "FLOAT64"), # float64 타입은 BigQuery의 FLOAT64 타입으로 매핑
]
job_config = bigquery.LoadJobConfig(schema=schema)
dataset_ref = client.dataset(dataset_id)
# 데이터셋이 없을 경우, 데이터셋 생성
try:
client.get_dataset(dataset_ref)
print("{} 데이터셋 이미 존재".format(full_dataset_id))
except NotFound:
dataset = bigquery.Dataset(full_dataset_id)
dataset.location = "asia-northeast3"
client.create_dataset(dataset)
print("{} 데이터셋 생성".format(full_dataset_id))
print('3/4 dataset 생성체크 완료')
# 테이블 존재 여부 확인
table_ref = client.dataset(dataset_id).table(table_id)
try:
client.get_table(table_ref)
client.delete_table(table_ref)
print("{} 테이블이 존재하여 삭제.".format(table_id))
except NotFound:
print("{} 테이블이 없어 생성필요".format(table_id))
job = client.load_table_from_dataframe(df_str, table_ref, job_config = job_config)
job.result()
end = time.time()
print("4/4 작업완료, {}초 소요".format(round(end-start)))
또한, cert_info.py을 생성해야하는데 이 부분은 kamis api를 사용하기 위한 인증키 파일이다.
- cert_info.py
# 개인키와 이메일은 비공개
# return '' 본인들 key 랑 id 넣으시면 됩니다.
def cert_key():
return '본인 key'
def cert_id():
return '본인 id'
이후 pip 패키지 관리자를 설치한다.
sudo apt install python3-pip
#pip 확인하기
pip --version✅ 파이썬 가상환경 설정 및 패키지 설치
Debian Linux에서는 글로벌 파이썬 패키지 설치가 불가능하고 권장되지 않으므로 가상환경을 설정한다.
sudo apt install python3.11-venv
#가상환경 생성(이름:env11)
python3 -m venv env11
#가상환경 실행
source env11/bin/activate
# 가상환경 종료
# deactivate
#설치된 리스트 보기
pip3 list
# 가상환경 활성화 되어있을 때
# Python 모듈 통합설치
pip3 install -r requirements.txt
#혹은 개별 설치
pip3 install pandas requests matplotlib pyarrow pandas-gbq
#google모듈 import 에러 해결
pip3 install --upgrade google-api-python-client
pip3 install google-cloud-bigquery
#설치확인
pip3 list위 설정이 모두 마무리가 되었다면 준비는 끝났다.
✅ 스크립트 실행 및 자동화 태우기
python3 kamis2bq.py
빅쿼리스튜디오에서도 테이블 세부정보를 보면 잘 작동했음을 확인할 수 있다.
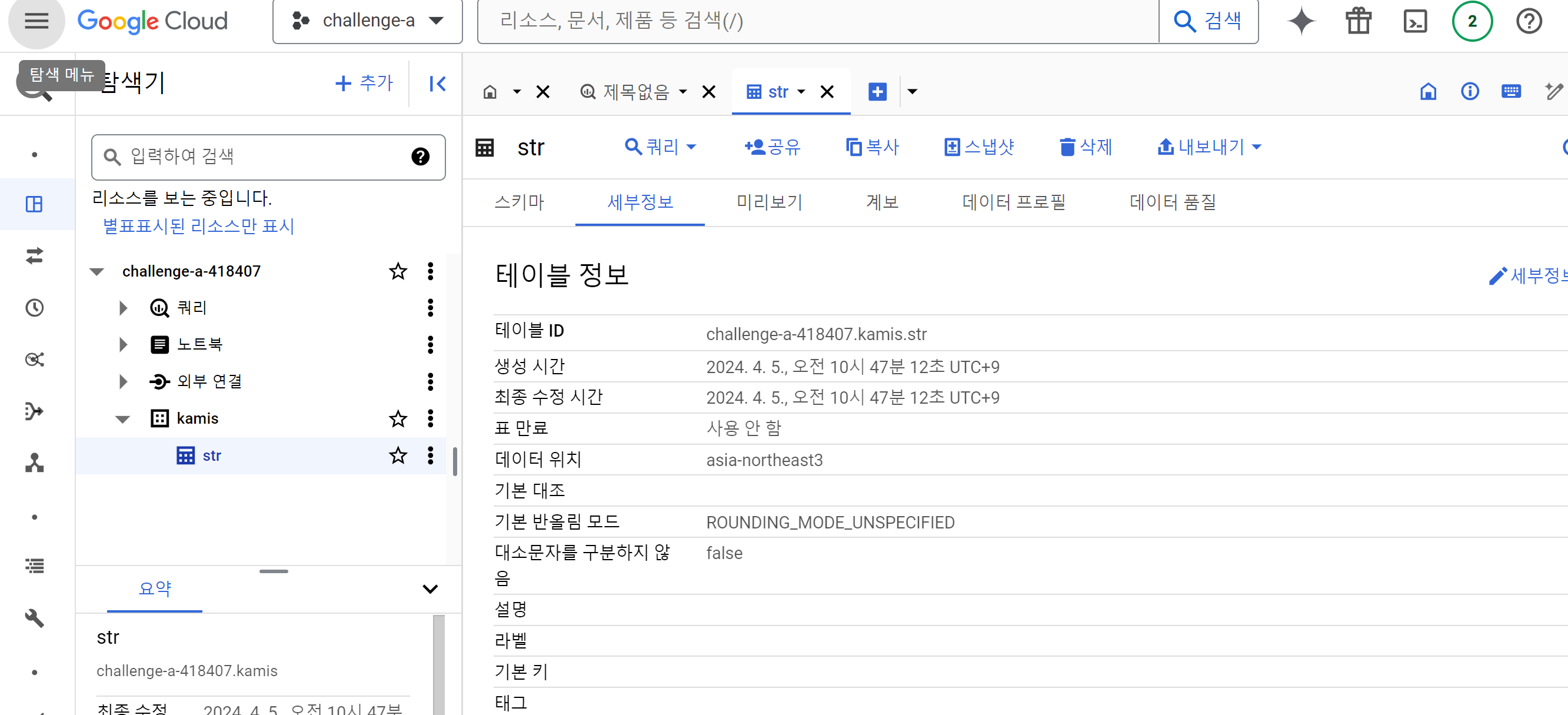
자동화를 태우고 싶으면 crontab 파일을 설정해주면 되며, 이때 중요한 점은 가상환경으로 설정했기 때문에 가상환경 경로의 Python 디렉토리를 구체적으로 작성해주어야 정상적으로 실행된다.
#cron 접속
crontab -e
# 다음 텍스트 삽입
# (매일 정오 마다) / (가상환경의 파이썬3으로)
# (다음 경로의 파일을 실행해라) / (로그를 남겨라)
0 12 * * * /home/jayjunglim/env11/bin/python3 /home/jayjunglim/whereisplanb/kamis_api/kamis2bq.py >> /home/jayjunlimg/kamis.log 2>&1
# 설정변경했으니 재시작
sudo systemctl restart cron
# 스케쥴링 시작
sudo systemctl start cron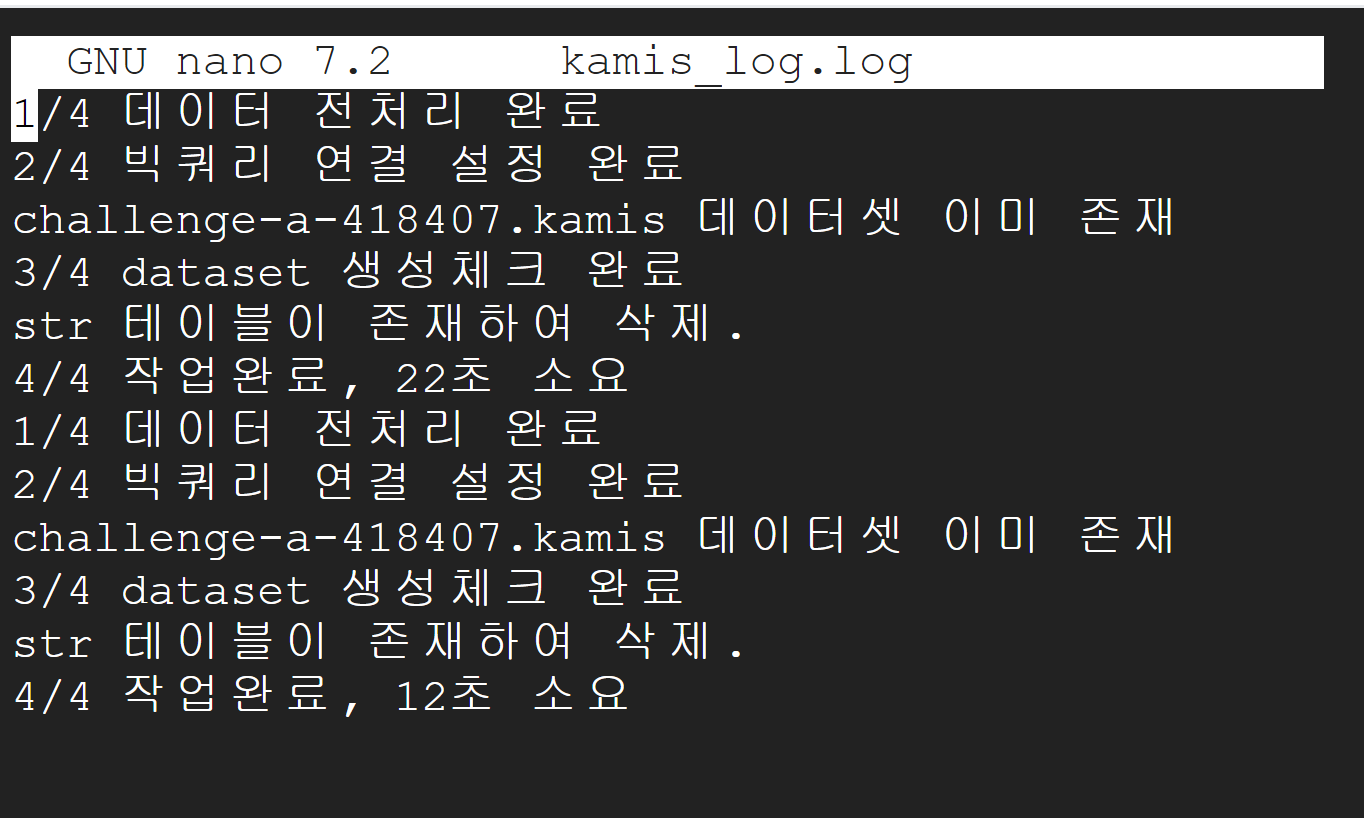
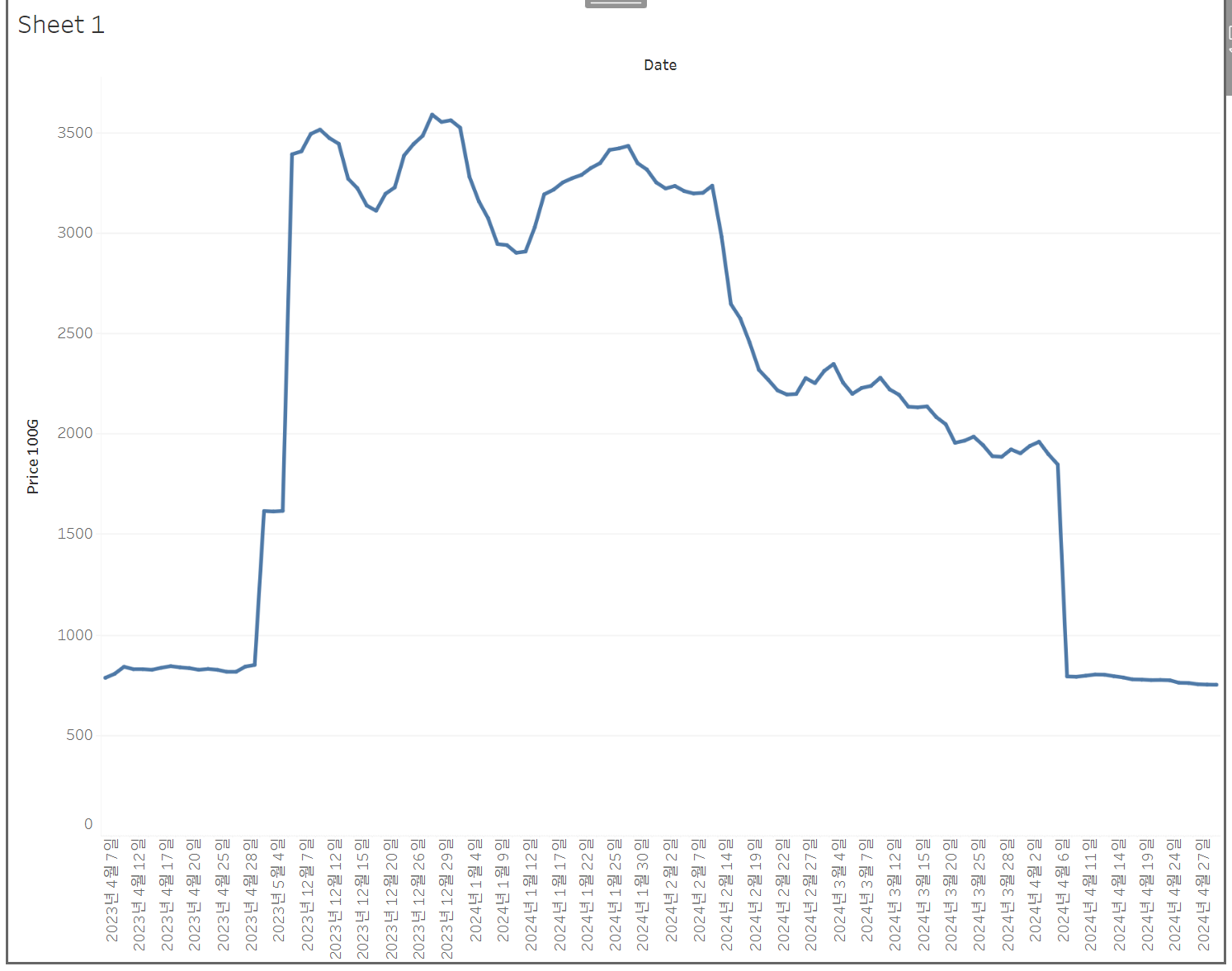
이후 대시보드에 연결해서 100g당 도매 가격현황을 볼 수 있다.다음은 딸기의 가격이다. 도매 기준으로 100g당 1000원에 정착하고 있으므로 마트 구매에 참고하시라. 요즘 1000원대로 많이 내려온 걸 실제로 확인할 수 있었다.
이렇게 해서 미루고 미뤘던 데이터 적재 자동화 프로토타입 만들기까지 완성했다. 작년초부터 만들어야지 하면서 미뤘던 건데, Linux에 익숙하지도 못했어서 삽질을 많이 했는데 이번에는 반나절정도에 해결할 수 있어서 매우 뿌듯하다. 이제 해야할일은 주기적으로 데이터 적재해서 현재 적절한 가격을 볼 수있게 만드는 것! 아무래도 간단하게 steamlit으로 구현하면 되지 않을까 싶다.

7. 글또 9기 글 모음
'Data Science > Engineering' 카테고리의 다른 글
| GCP 셋업를 위한 기본 지식: 하드웨어와 OS 개념 (0) | 2024.04.13 |
|---|
