예상독자
- 로컬 머신와 빅쿼리를 연결해보고 싶은 독자
- 데이터 적재 자동화를 동해 태블로에 시각화하고 싶은 독자
1. 배경
데이터분석을 넘어 데이터 파이프라인을 만들어 자동화를 하는 경우가 생긴다. 제일 좋은 것은 데이터 엔지니어 혹은 개발자에게 요청하는 것이겠지만 prototype 혹은 나만의 product를 만드는 관점에서 진행해보고자 한다.
GCP 혹은 AWS와 같은 서버(인스턴스)를 생성하여 서버를 사용하는 법이 있긴 하지만 초보자들에게는 서버관리의 어려움도 있고 삽질을 조금 해야해서 최대한 간단한 방법인 google SDK 를 이용해서 big query에 데이터를 저장하는 방법을 알아보겠다. 본 글에서 구현하고자하는 기능은 다음과 같다.
- Google Cloud Storage 로그인
- Google Cloud SDK를 이용한 로컬과 big query 연결
- big query에 해당 데이터를 저장
- big query에서 태블로온라인으로 데이터 가져오기
2. 본문
- Google Cloud Storage 로그인
GCP 에 처음 접속하면 무료 계정을 생성하라 하며, 개인 정보와 결제정보를 요구하는데, 첫 가입에는 300$ 약 40만원의 크레딧을 지급해줍니다. 순순히 가입해봅니다. 우리는 용량을 그렇게 많이 쓰지 않을 것이니 걱정은 덜으셔도 됩니다.
만약 이미 GCP에 가입해있다면 이번 단계를 넘기셔도 되며, 첫 로그인임에도 입력하는 창이 안 뜨면 뜰때 입력하시면 됩니다.(저의 경우 이미 GCP에 가입되있어서 어떤 단계에서 진행되는지 모르겠네요)
https://cloud.google.com/?hl=ko
클라우드 컴퓨팅 서비스 | Google Cloud
데이터 관리, 하이브리드 및 멀티 클라우드, AI와 머신러닝 등 Google의 클라우드 컴퓨팅 서비스로 비즈니스 당면 과제를 해결하세요.
cloud.google.com

만약 본인이 빅쿼리를 지나치게 많이 쓴거 같다 싶으면 위와 같은 GCP 콘솔 홈화면에서 크레딧 사용량을 보면 됩니다.
2. Google Cloud SDK를 이용한 로컬과 bigquery 연결
Google Cloud SDK란?
Google Cloud SDK란 Google Cloud 제품 및 서비스와 상호작용하기 위한 도구 및 라이브러리입니다. 쉽게말해 내컴퓨터와 bigquery를 연결하는 방법이며 따로 프로그램을 깔아주어야 합니다. 단 개발용 설정이므로 서비스용으로 사용하기에는 적절하지 않습니다. 서비스용으로 진행하려한다면 Json 형식의 서비스 계정 키를 로컬에 발급받아야합니다. 다음 구글 공식문서를 참고해주세요.
https://cloud.google.com/docs/authentication/application-default-credentials?hl=ko
돌아와서 SDK 설치 진행방법으로 계속하겠습니다.
설치주소: https://cloud.google.com/sdk/docs/install?hl=ko
gcloud CLI 설치 | Google Cloud CLI 문서
의견 보내기 gcloud CLI 설치 컬렉션을 사용해 정리하기 내 환경설정을 기준으로 콘텐츠를 저장하고 분류하세요. 이 페이지에는 Google Cloud CLI 설치를 선택하고 유지하기 위한 안내가 포함되어 있습
cloud.google.com

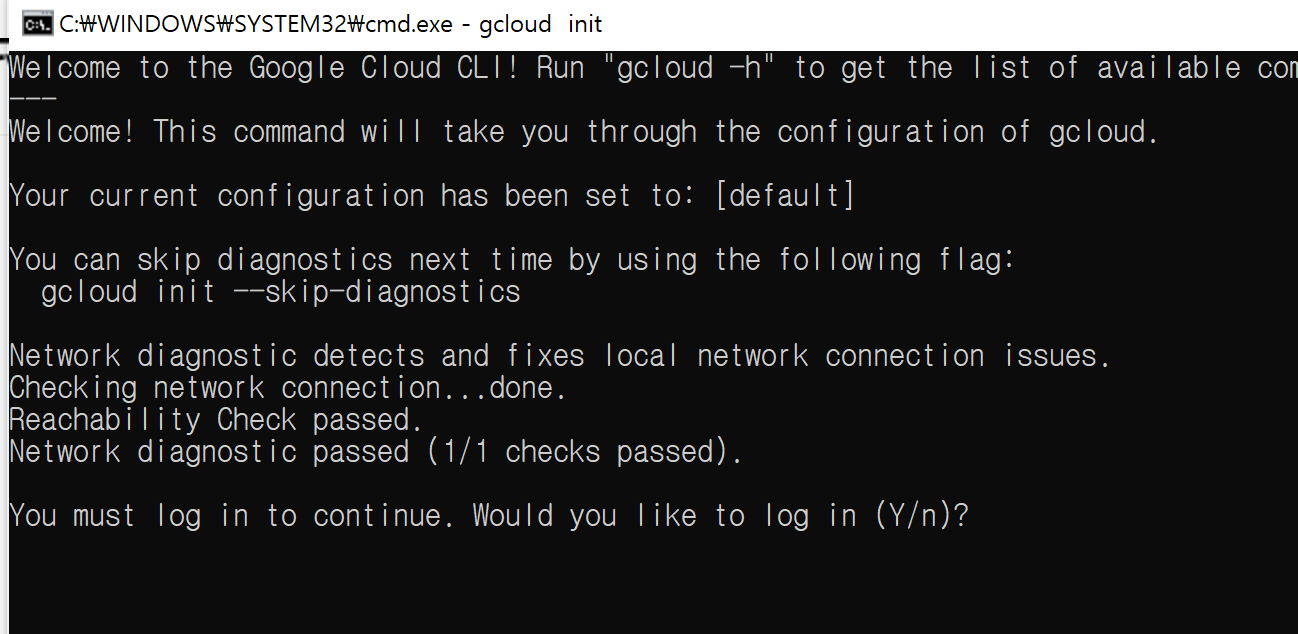

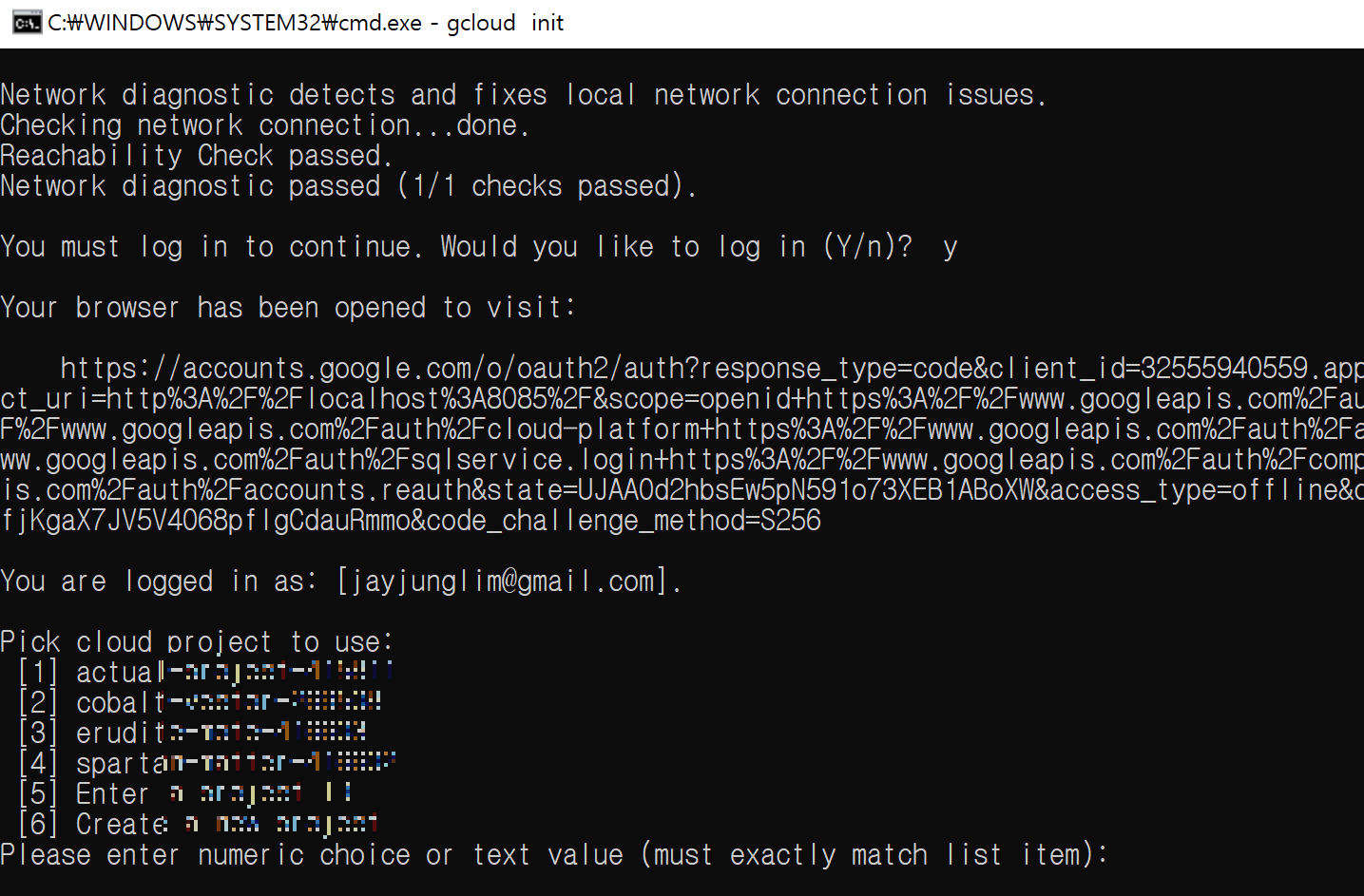
설치가 완료되면 어떤 프로젝트를 고를지 뜹니다. GCP 홈페이지에 들어가면 기본 프로젝트 명을 확인할 수 있습니다. 혹은 다음 명령어로 프로젝트 리스트를 확인할 수 있습니다.
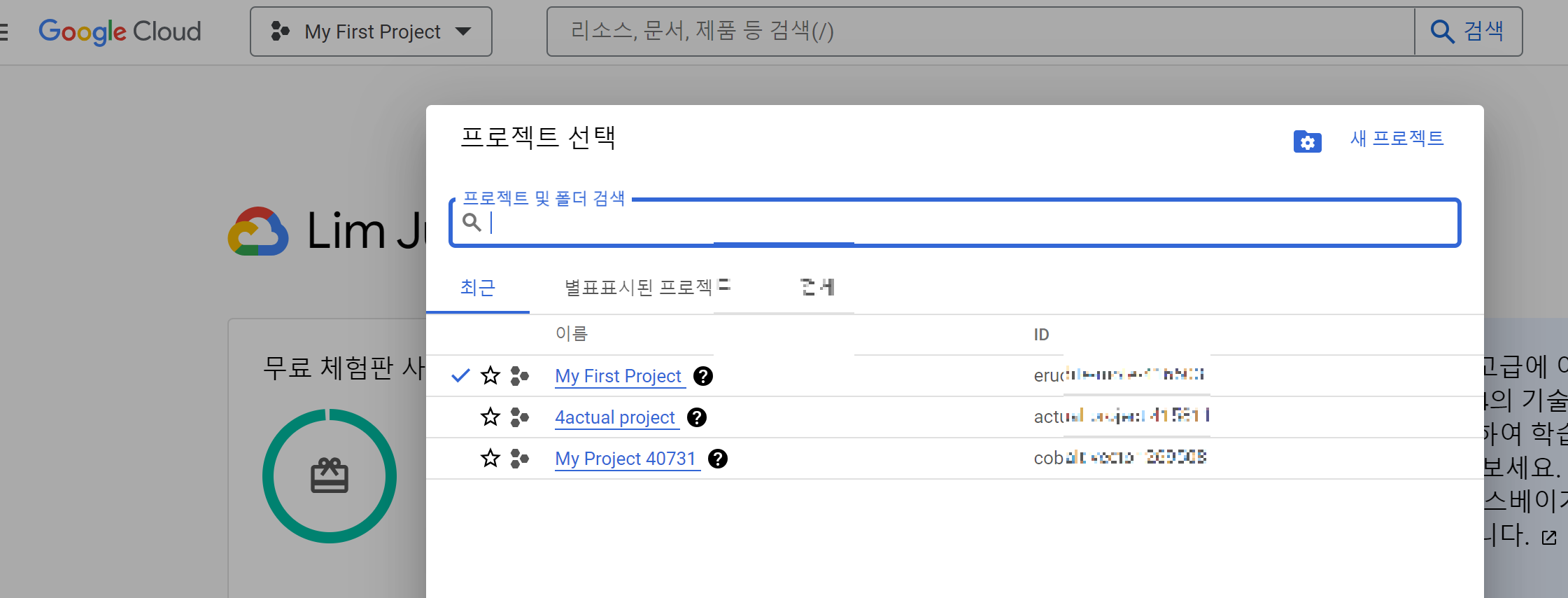
gcloud projects list반면 홈페이지로 볼때는 이름은 MyFirstProject인데 프로젝트 리스트를 보면 eru 로 시작하는 ID 로 확인되네요
위 cmd 창에서 3번을 입력하면 gcloud 와 상호작용할 수 있는 명령줄이 나옵니다.
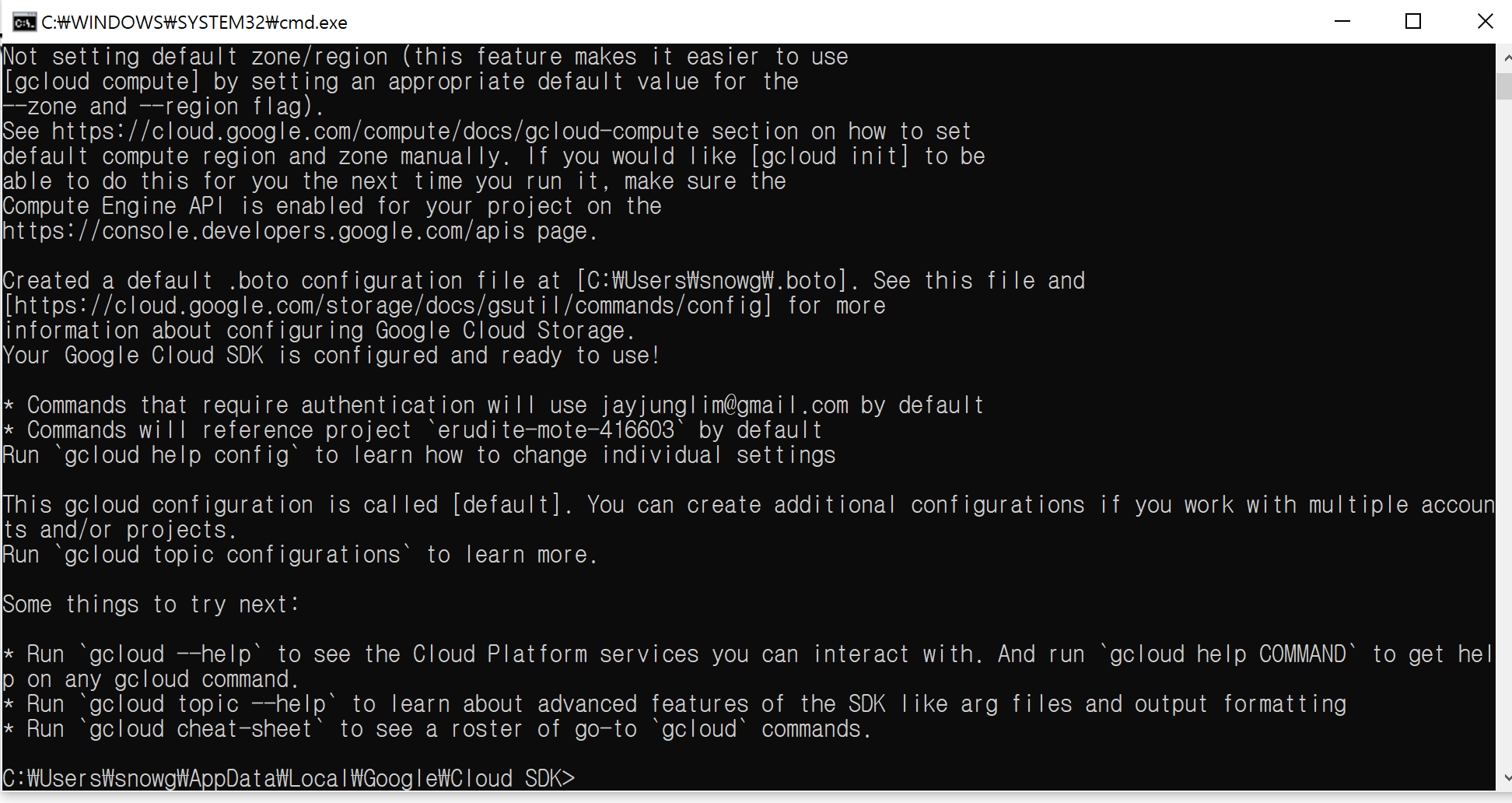
고인물 들은 cmd로 하시는 것에 익숙하겠지만 저는 그렇지 않으므로, 창을 닫도록 하겠습니다.
만약 프로젝트를 바꾸고 싶다면 다음 명령어를 치시면 됩니다.
gcloud config set project <프로젝트id>2. 윈도우에 환경변수 설정
SDK는 설치했지만 환경변수에 등록되지 않은 경우 Python 스크립트에서 빅쿼리연결이 안 됩니다. 이를 위해 먼저 SDK연결이 된 경로를 확인해 봅니다.
윈도우의 경우 "C:\Users\snowg\AppData\Local\Google\Cloud SDK" 이 경로에 있습니다. 내PC 혹은 탐색기를 이용하면 접근할 수 있는데 만약 폴더가 안보인다면 보기옵션 - 숨긴항목 체크를 하면 숨겨진 폴더가 나옵니다.
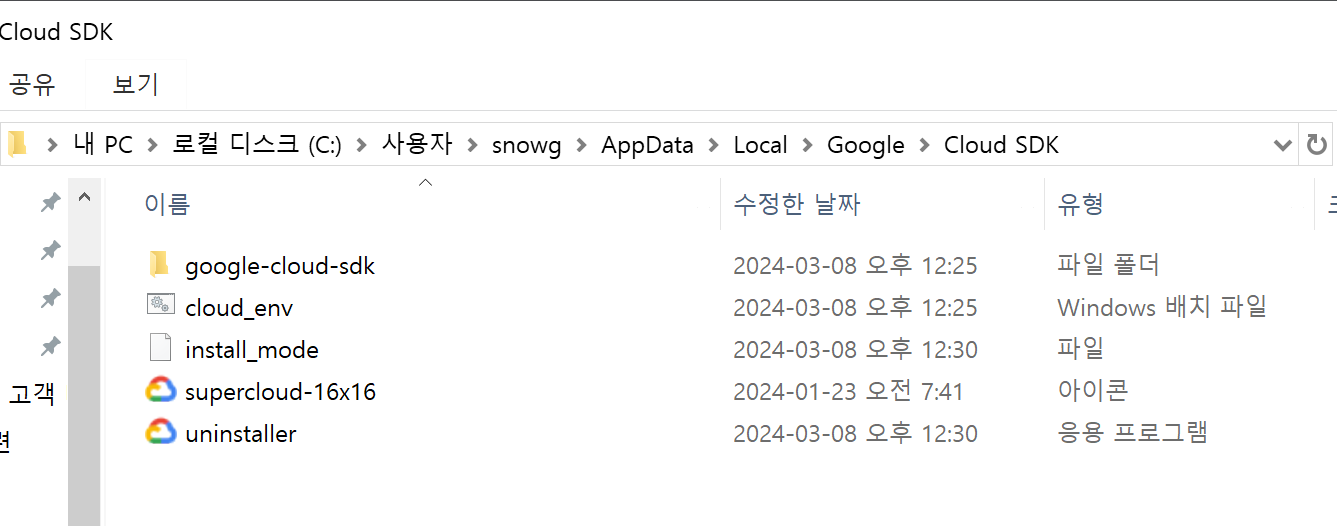
이번에는 해당 경로를 윈도우가 인식하도록 환경변수를 설정해주겠습니다.
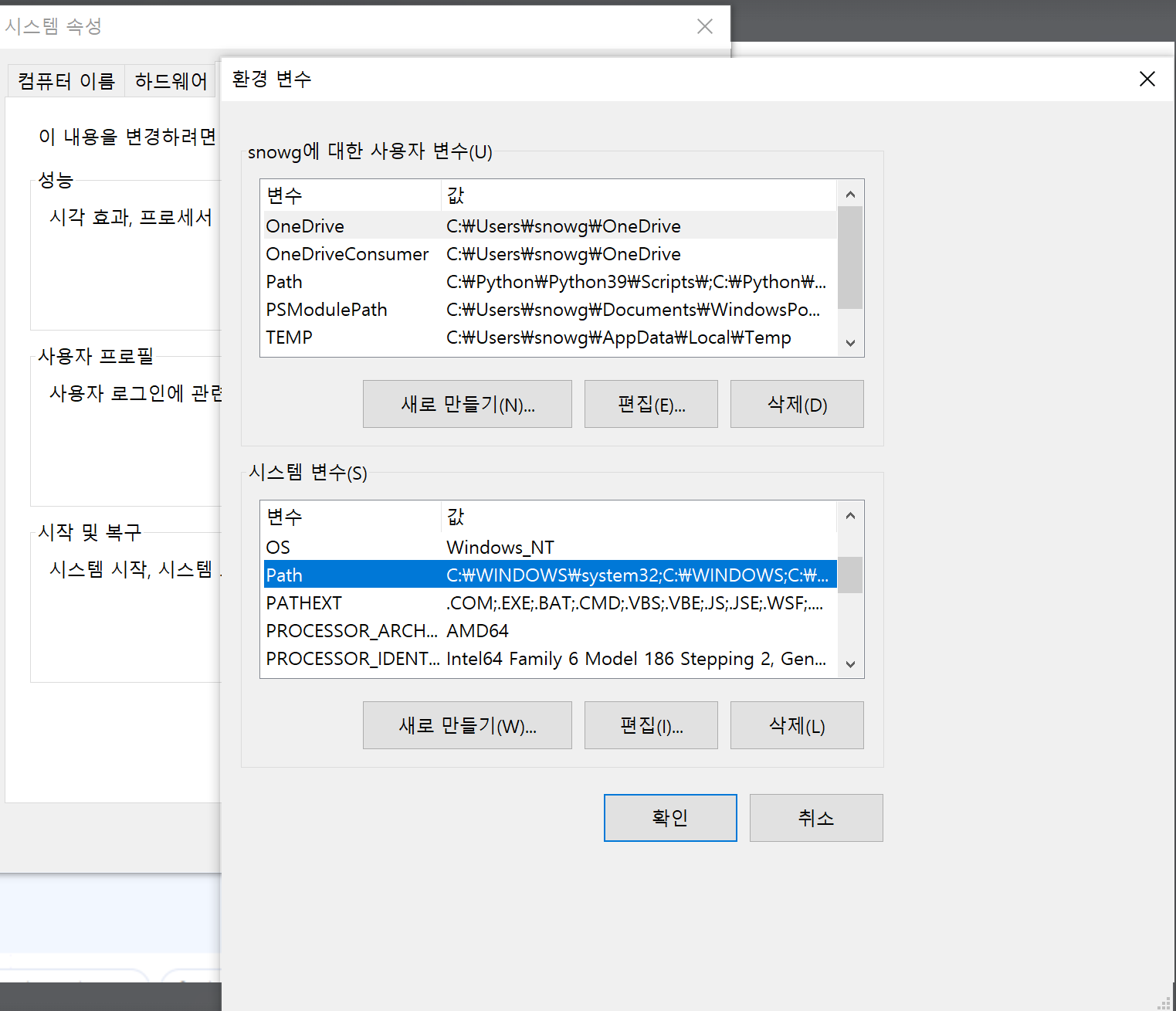
제어판 - 시스템 - 고급 시스템 설정 - 환경 변수 탭을 선택하면 다음과 같은 화면이 나오며, 시스템 변수에서 Path 변수를 확인할 수 있습니다. Path 변수 클릭 - 편집 - 새로만들기 하여 다음 과 같은 경로를 추가해줍니다.
경로명: C:\Users\snowg\AppData\Local\Google\google-cloud-sdk\Cloud SDK\bin
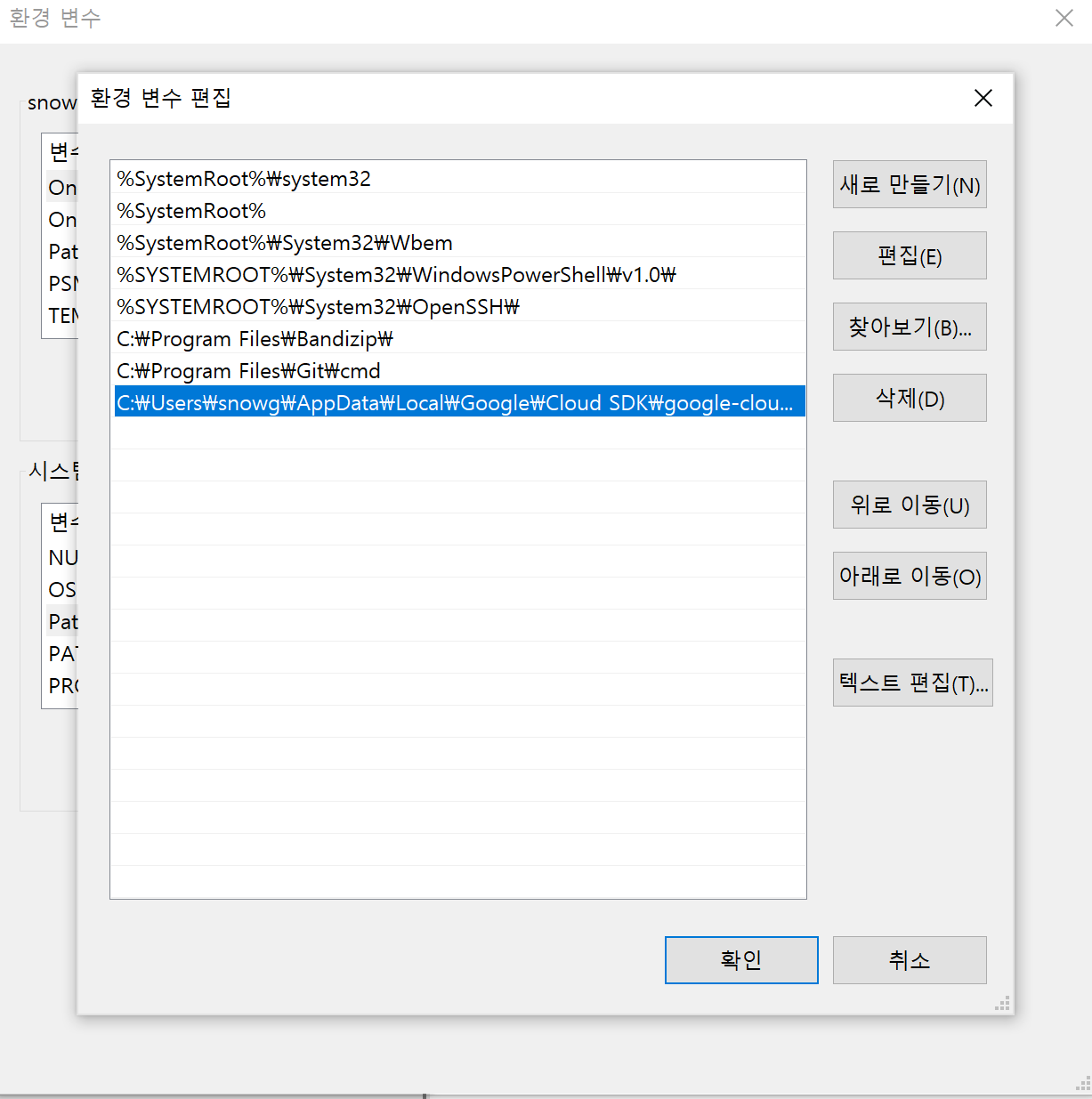
모두 확인을 누르고 나가줍니다.
환경 변수 설정이 잘 되었는지 보기 위해서 cmd 창을 열어 1번 마무리에 띄워서 cloud에 접속했던 것과 동일하게 하려면 다음 윈도우키 - 명령프롬프트를 실행한 뒤 다음 코드를 치면 됩니다. 그럼 구글 이메일로 인증화면이 오면서 gcloud에 접속할 수 있게 됩니다.
gcloud auth login* 주의 *
이 부분에서 엇갈리는 분기가 있습니다. 바로 서비스계정이냐 개발용 계정이냐의 차이입니다.
만약 서비스 계정이라면 보안의 이유로 인해 위의 SDK설치로 진행하는 것은 권장되지 않으며 google application credential 획득을 big query가 제공해주는 json 형식의 서비스 계정 키를 사용하는 것이 적절합니다. 하지만 우리는 간단하게 연결할 것 이기 때문에 SDK로 진행할 것입니다.
왜 이 얘기를 하게 되었냐면 SDK로 설치할 경우 따로 서비스 계정 키를 사용하지 않으므로 다음 명령어를 통해서 이메일을 이용하여 계정의 인증정보를 로컬 시스템에 저장할 것입니다.
gcloud auth application-default login3. Python을 이용하여 빅쿼리에 데이터 넣기
- GCP 콘솔로 돌아와 좌측 줄 세개 - Big Query - BigQuery Studio를 선택해줍니다.
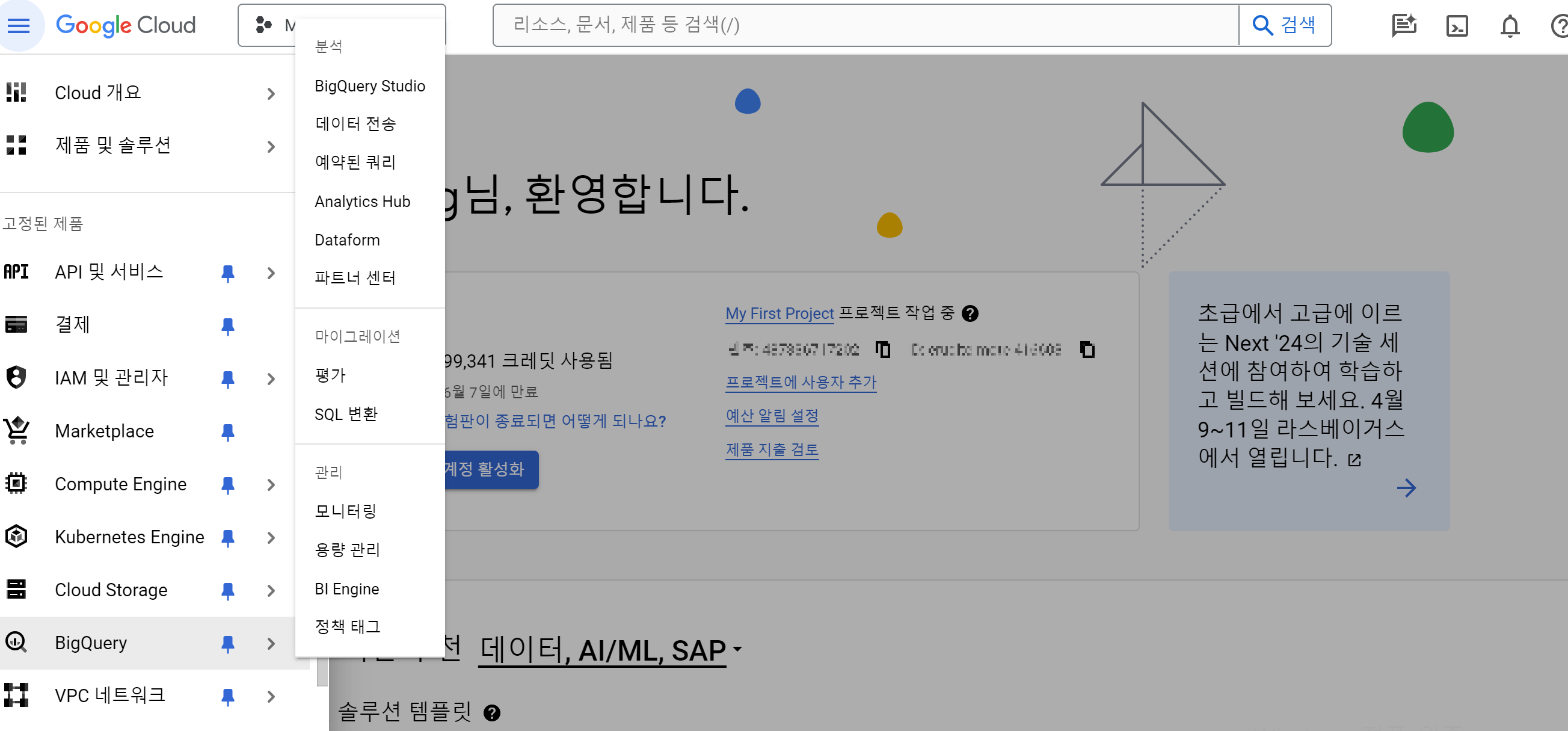
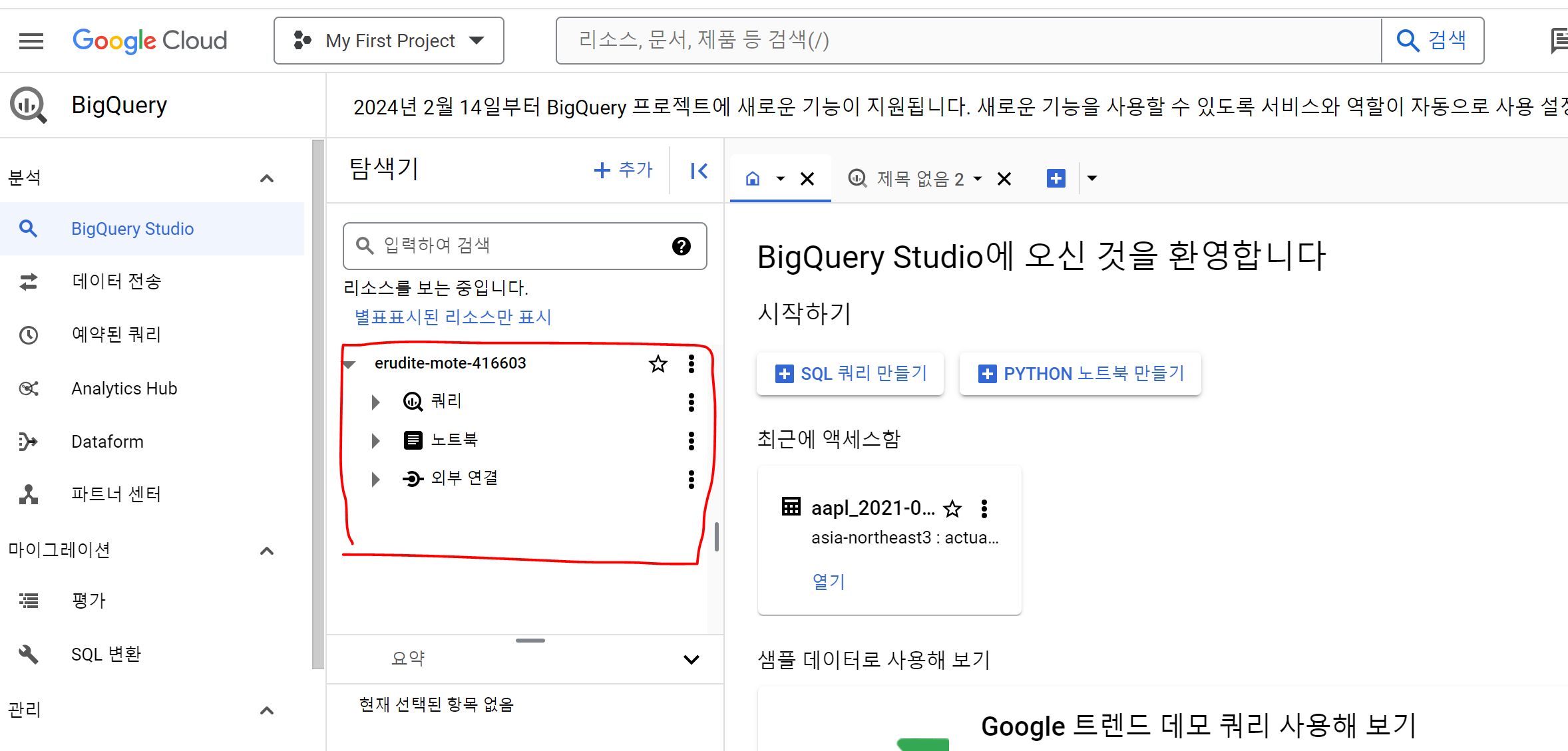
erud로 시작하는 경로에는 아무것도 현재 없는 걸 볼 수 있습니다.
이제 vscode를 이용해서 데이터를 불러오고 bigquery에 데이터를 적재해보겠습니다. 저는 간단하게 yfiance데이터를 가져오겠습니다.
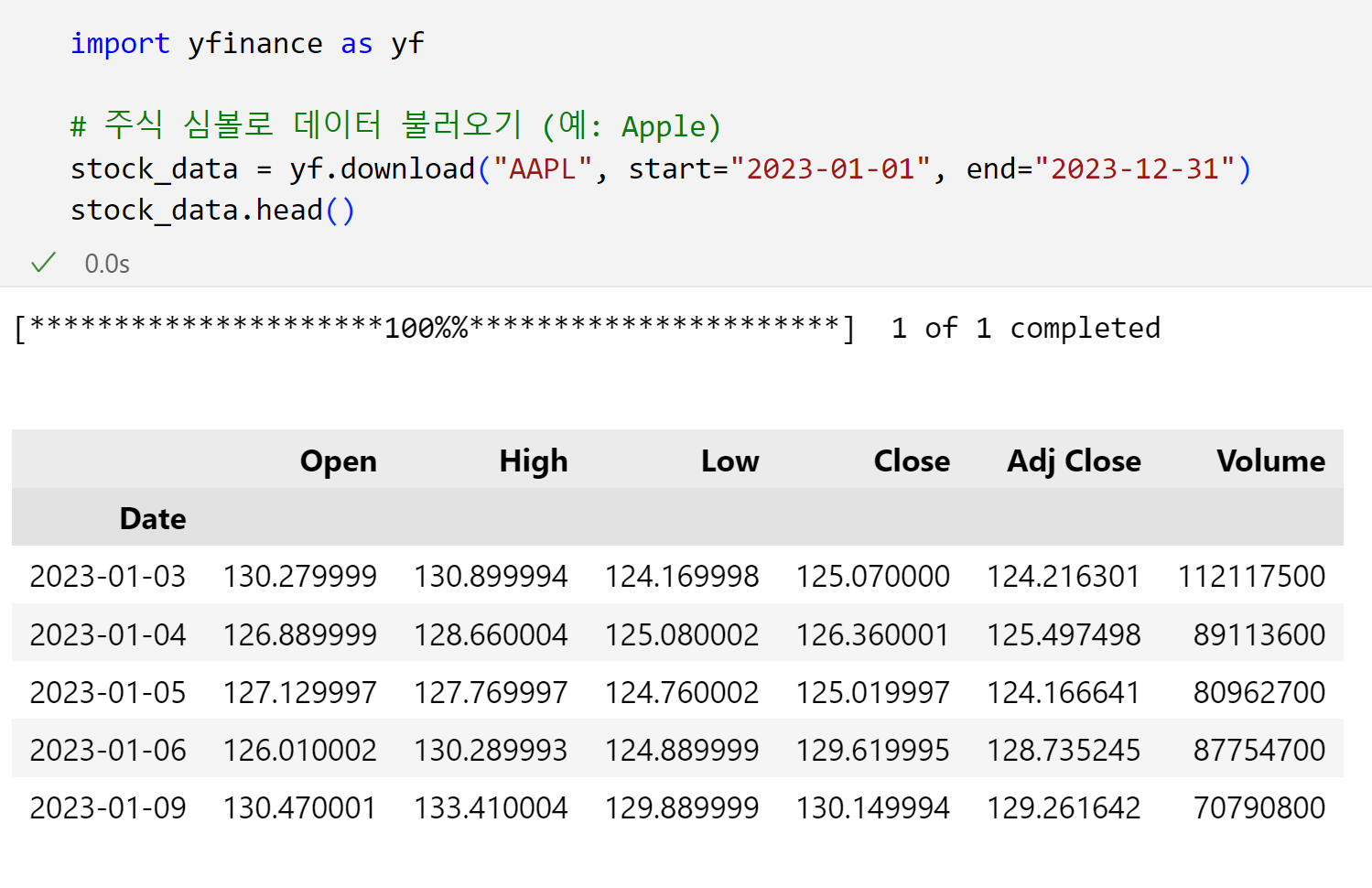
- 그리고 처음이라면 googl.cloud 모듈을 설치해줍니다. 파이썬이 google cloud에 접근할 수 있도록 해주는 모듈입니다.
- 또한, pandas의 데이터프레임 객체를 google bigquery(gbq)에 올리는 라이브러리는 pandas 2.2.0. 버전부터 없다고 하니 따로 pandas-gbq 모듈을 설치주어야 합니다.
!pip install google.cloud
!pip install pandas-gbq
그리고 다음 코드를 이용하여 데이터셋을 생성하고, 데이터를 넣어줍니다. 여기서 설정해주어야하는 것은 데이터셋의 이름(my_dataset), 테이블명(my_table)과 빅쿼리에 올릴 데이터프레임 객체(stock_data)입니다.
from google.cloud import bigquery
from google.cloud.exceptions import NotFound
# BigQuery 클라이언트 생성
client = bigquery.Client()
project_id = client.project #현재 gcloud 명령어를 통해 접속한 프로젝트
### 여기 설정 ###
dataset_name = 'my_dataset' # 데이터셋 명명
### 여기 설정 끝 ###
# 데이터 세트 ID 설정. 이 ID는 '[YOUR_PROJECT_ID].[DATASET_ID]' 형식이어야 합니다.
dataset_id = "{}.{}".format(project_id, dataset_name)
# 데이터 세트 참조 생성
dataset_ref = bigquery.DatasetReference.from_string(dataset_id)
try:
# 데이터 세트가 존재하는지 확인
client.get_dataset(dataset_ref)
print("Dataset already exists.")
except NotFound:
# 데이터 세트가 존재하지 않으면, 데이터 세트 생성
dataset = bigquery.Dataset(dataset_id) # 데이터 세트 설정
dataset.location = "asia-northeast3" # 데이터 세트의 지역을 설정(서울로 설정)
dataset = client.create_dataset(dataset) # API request # 데이터 세트 생성
print("Created dataset {}.{}".format(project_id, dataset.dataset_id))
### 여기 설정 ###
table_name = 'my_table' # 데이터 테이블 명
### 여기 설정 끝 ###
table_id = "{}.{}".format(dataset_name,table_name)
# 구글빅쿼리(gbq)에 올릴 데이터프레임 변수를 기입
stock_data.to_gbq(destination_table=table_id, project_id=project_id, if_exists='replace')그럼 다음과 같이 업로드 되었다는 출력이 나옵니다.
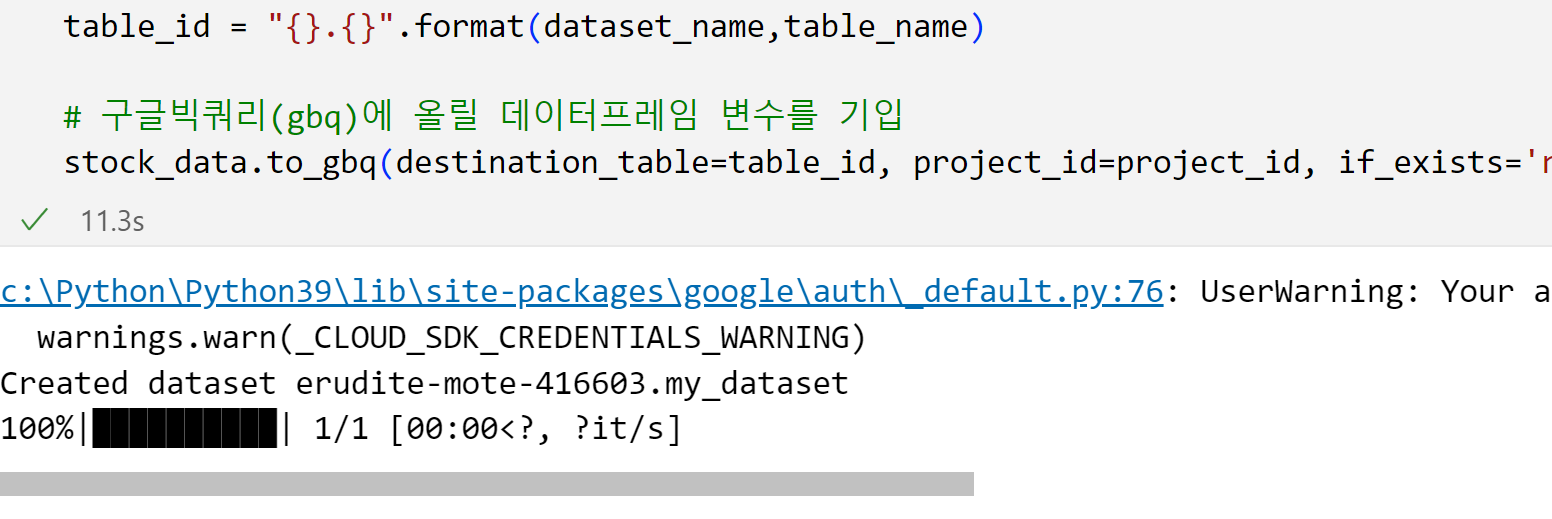
또한, bigquery studio에서 데이터셋과 테이블이 생성된 것을 볼 수 있습니다.
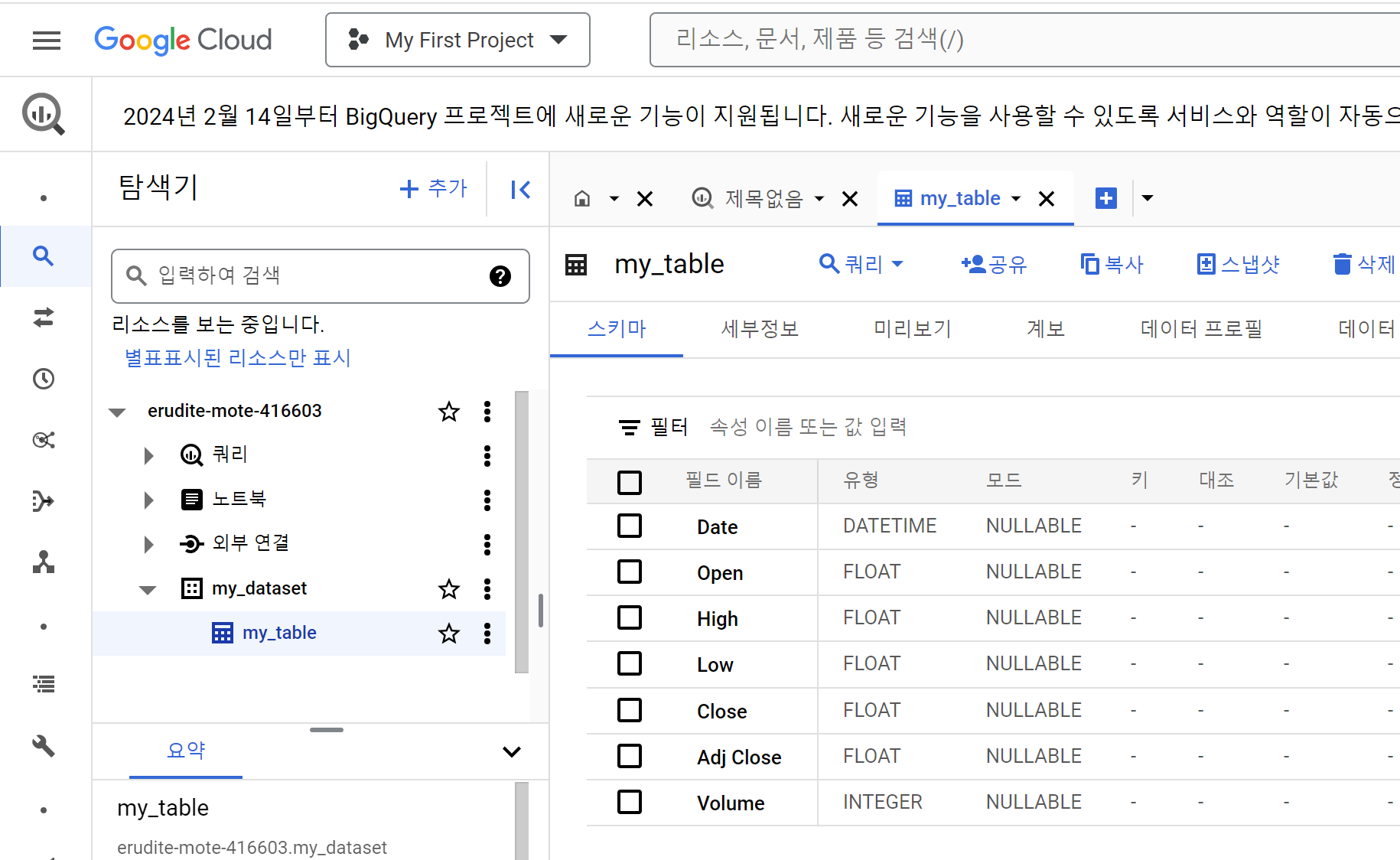
이로서 로컬에서 가공하거나 데이터 예측을 수행한 데이터를 빅쿼리에 올리는 과정까지 마쳤습니다.
*혹시*
위 과정에서 DefaultCredentialError 가 뜬다면 제대로된 인증정보를 찾지 못하였다는 것입니다. 새롭게 설치하는 환경에서 이런 문제가 생기던데, 이경우 다음 코드를 통해 gcloud 모듈을 다시 설치하면 해결되는 경우가 많았습니다.
!pip install google.cloud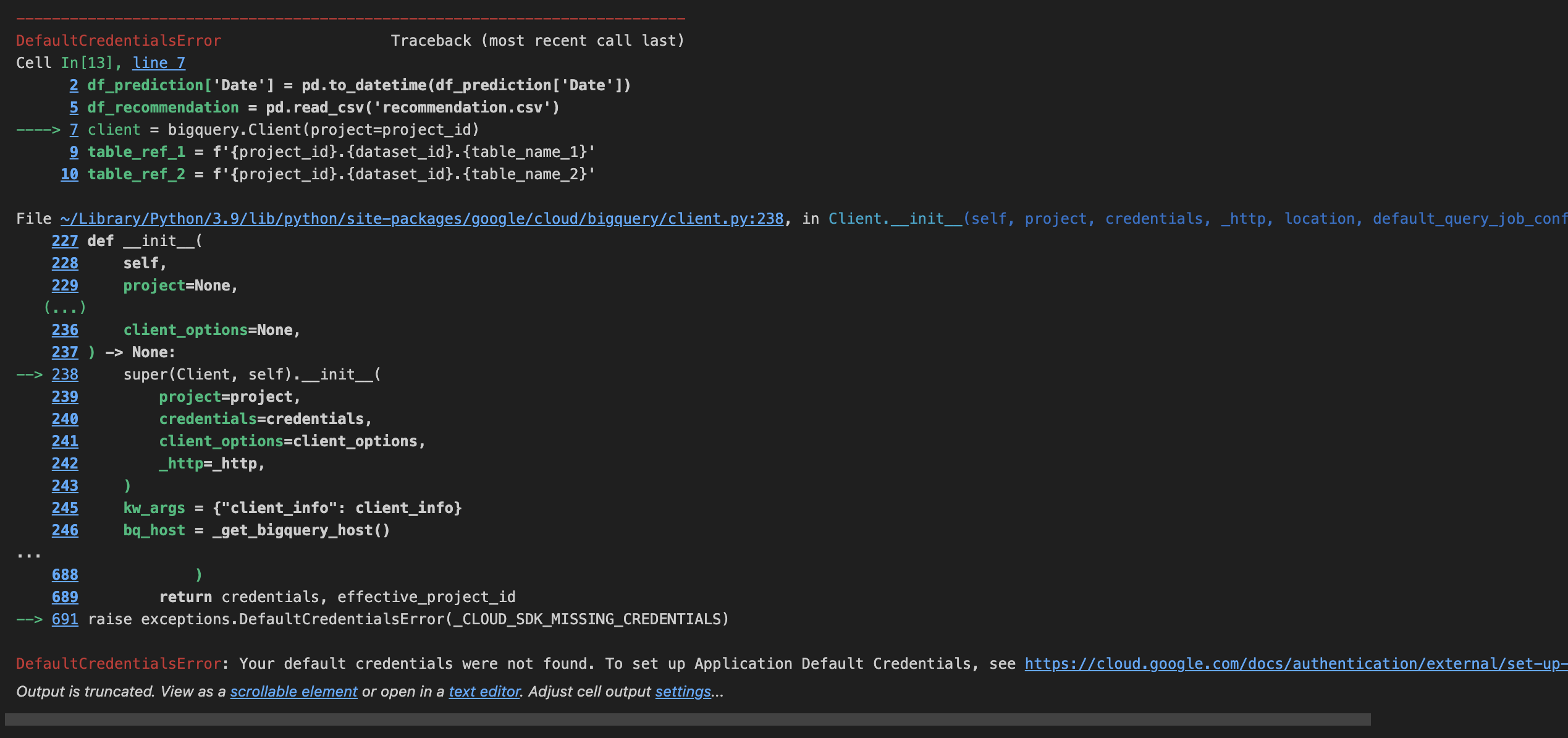
아마 SDK를 설치하면서 중간에 google.cloud 모듈이 꼬이는 것 같은데 정확한 원인은 알 수 없네요 😥
4. bigquery에서 태블로온라인으로 데이터 가져오기
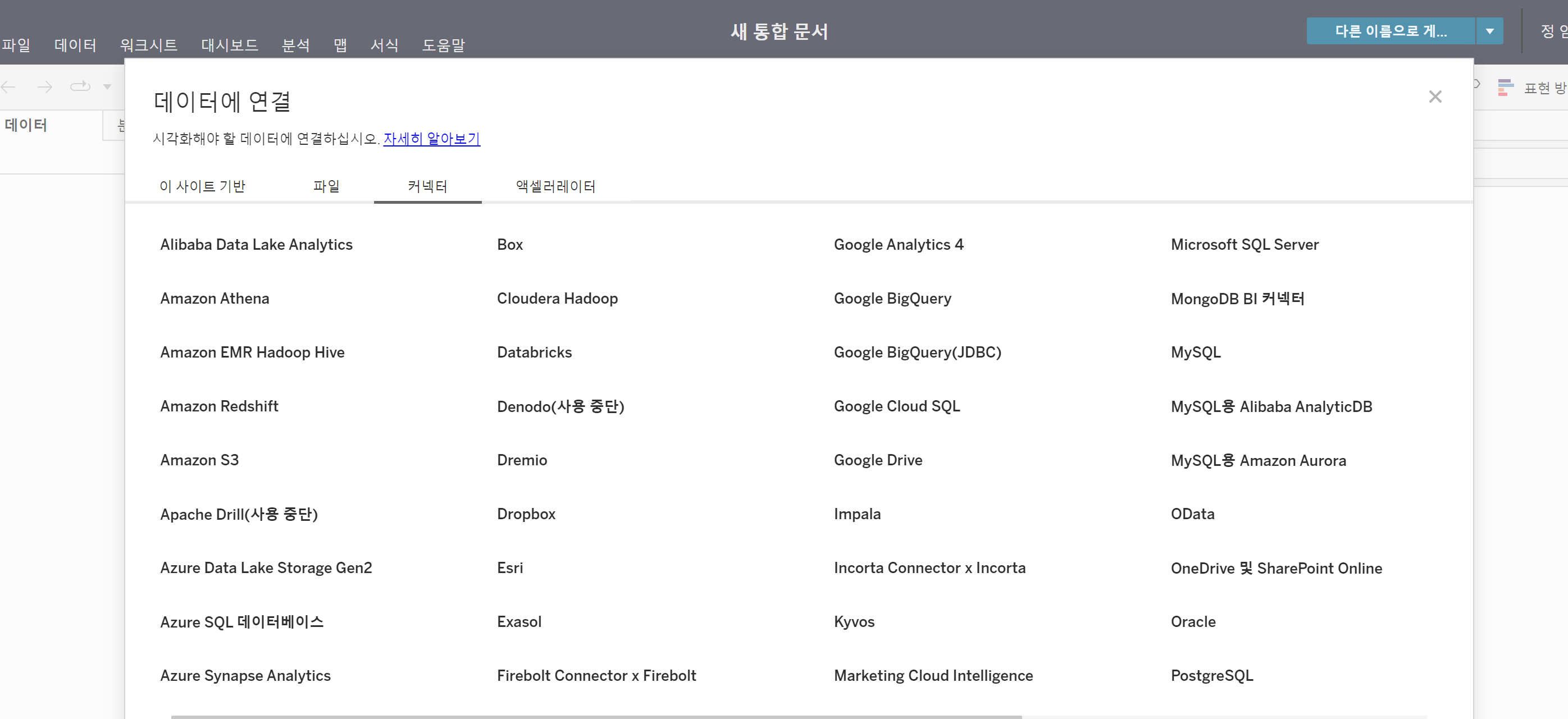
새로운 통합문서를 연 뒤 데이터에 연결 - 커넥터 - 구글 빅쿼리(JDBC)를 선택해 줍니다.
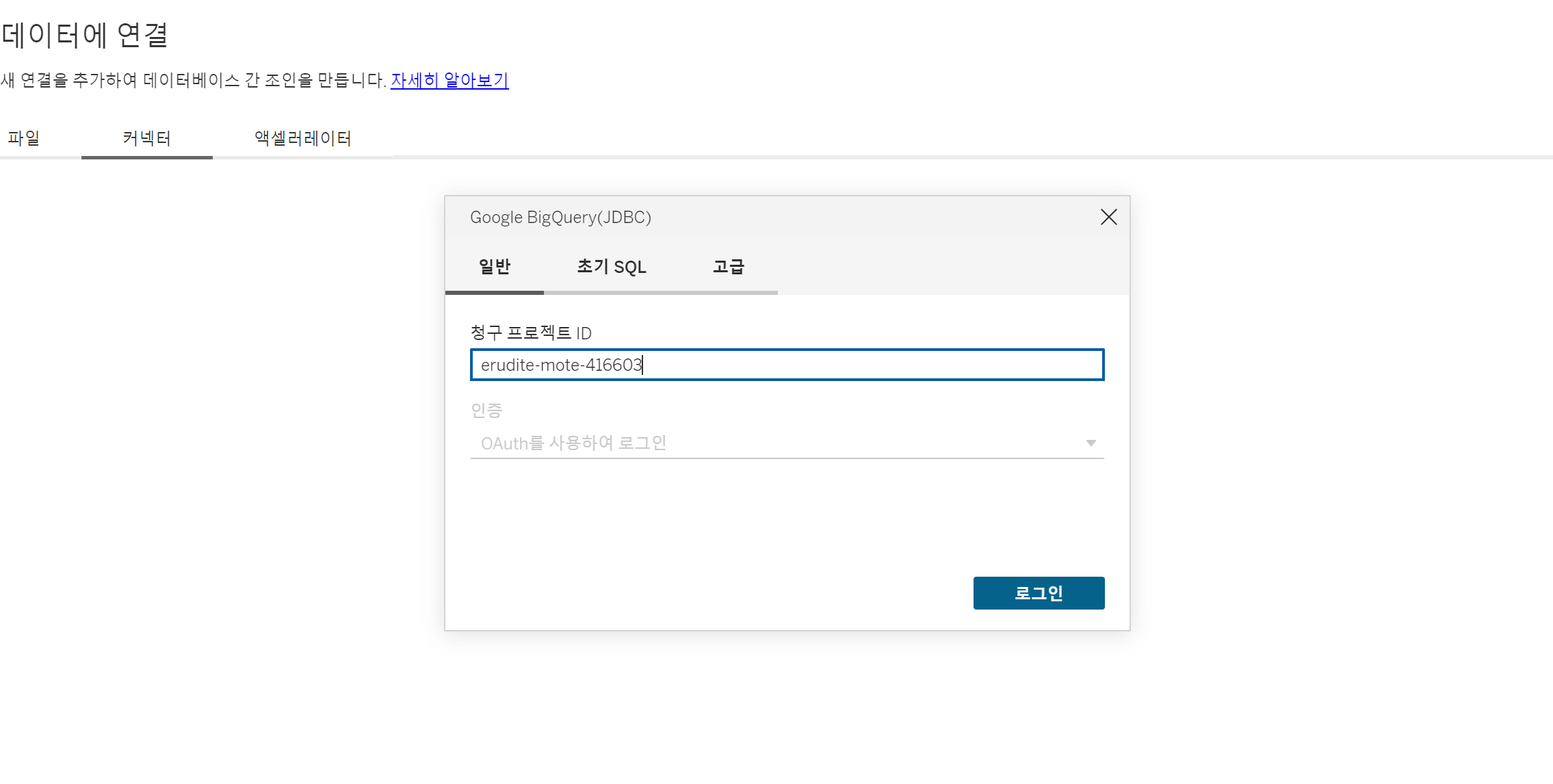
그럼 다음과 같이 청구 프로젝트ID를 입력하라고 하는데, bigquery studio에 있는 프로젝트ID를 선택해주면 됩니다.
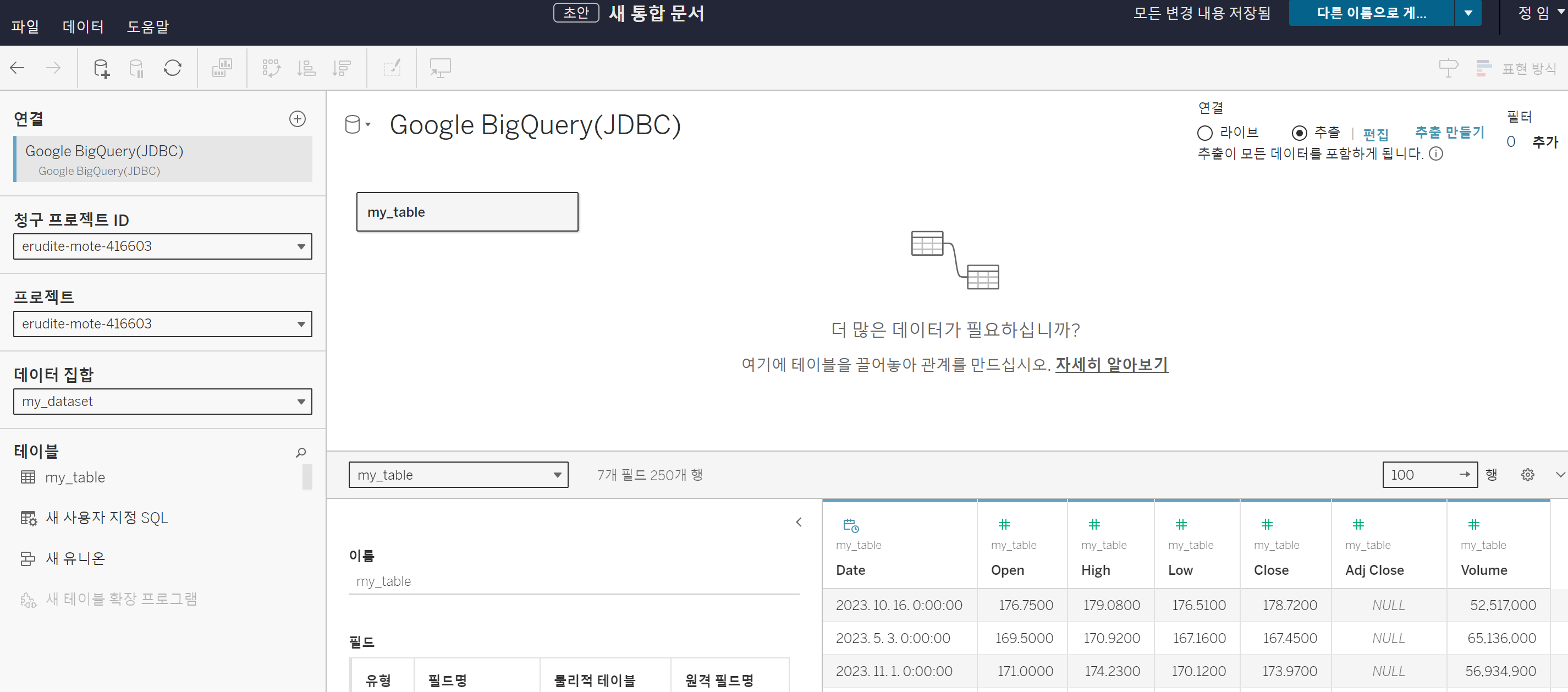
이후 프로젝트와 내 테이블을 드롭다운 메뉴로 선택하게 되면 데이터를 정상적으로 불러올 수 있습니다. 혹시모르니 "라이브"가 아닌 "추출"로 우측 상단 선택하시고 데이터를 업데이트하시면 확인 가능합니다.
마무리로 혹시 이 짧은 데이터에서도 크레딧이 청구가 되었는지 확인해 보겠습니다.
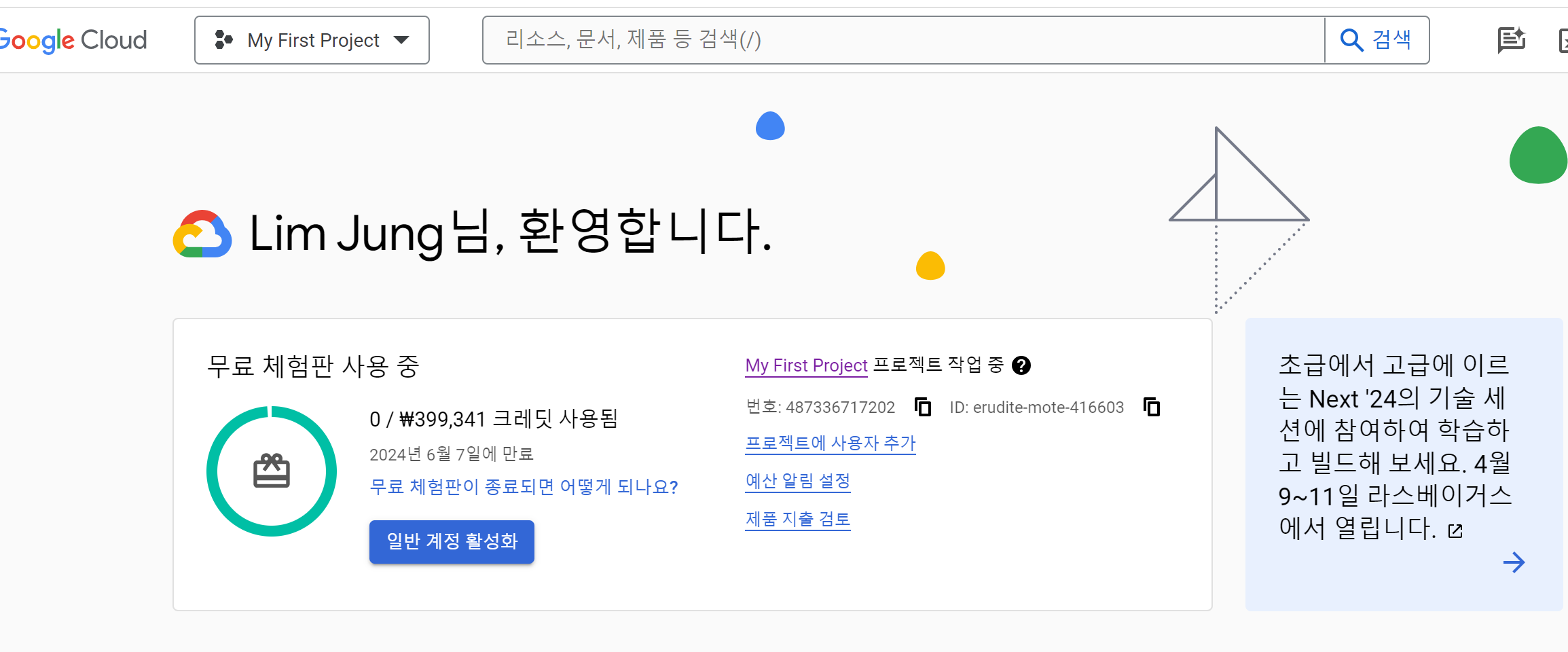
사실 데이터가 너무 작아서 크레딧 사용이 안되긴 하였다. 여기에서 우측에 있는 My First Project 프로젝트 명을 선택하면 사용량을 확인 할 수 있다.
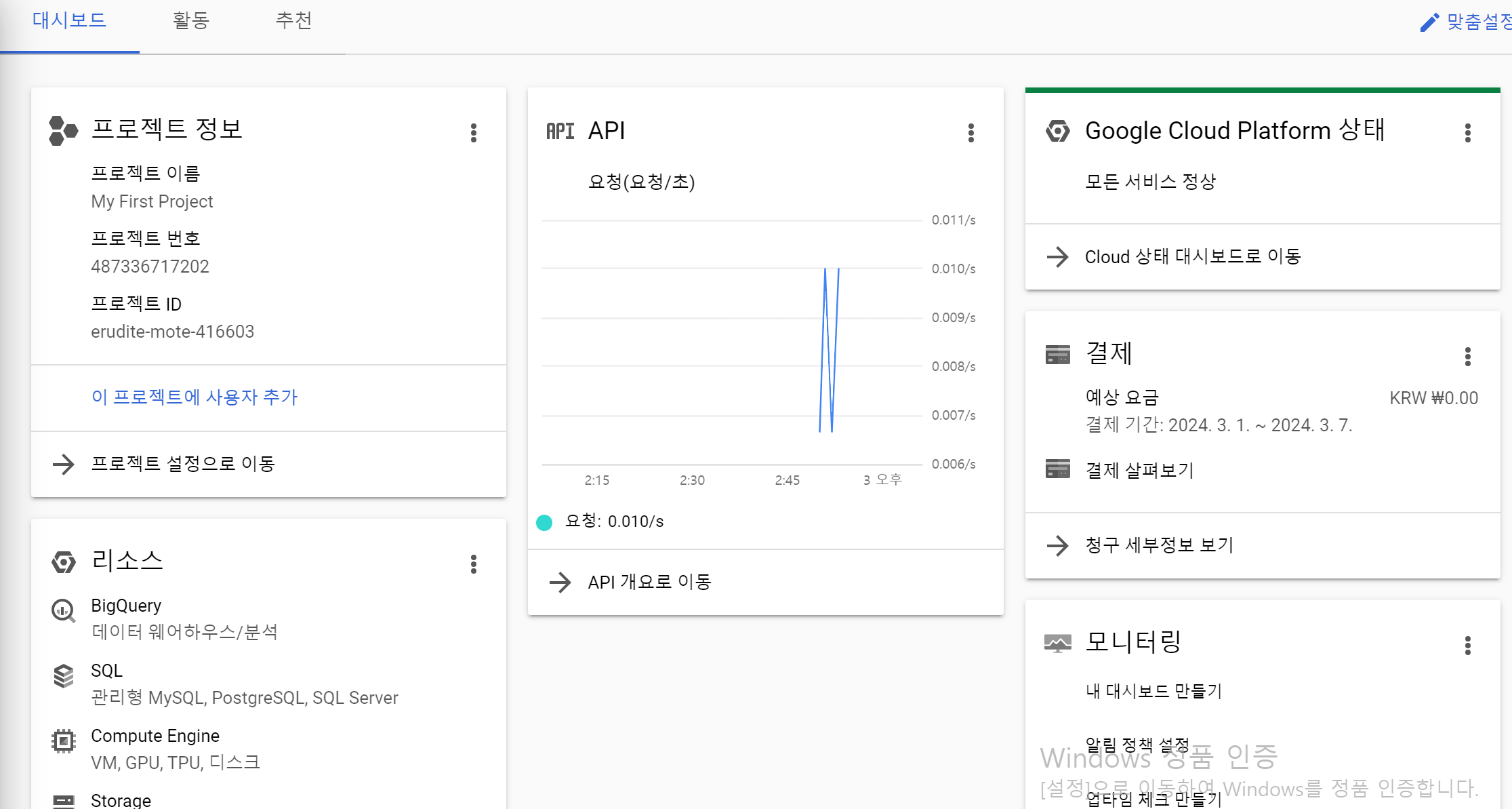
아무래도 크레딧이 계정당 정해져 있고, 혹여나 데이터가 큰 경우 크레딧 남발이 될 수 있으니, 이 사용량을 잘 확인하면서 빅쿼리를 사용하면 되겠다. 같은 맥락으로 태블로에서도 라이브가 아닌 추출로 설정하여 단발로 사용하길 권하는 것이다.
3. 마무리
한창 프로젝트 하겠다고 AWS Micro service를 몇개 설정하고 했는데, 제일 힘들었던게 막 열어버린 나의 서버들을 한땀한땀 중지시키고 요금 발생할 곳을 검토하는게 어려웠다. 알고보니 서버가 덜 닫혀서 과금된 기억이 있다. 그래서 더 이런 클라우드 서비스를 할 때 최대한 관리가 가능하도록 글을 썼다. 물론 서버를 만들고 사용하는 것은 좋은 경험이지만, 돈벌러 공부하는데 돈쓰면 슬프니까(그게 수업료일지도...?)
반면에 참 예전보다는 클라우드 서비스 쓰기 좋은 세상이 온 것 같다.
4. 글또 9기 글 모음
- 당신은 절대 글을 잘 쓸 수 없다.
- 기호주의와 연결주의로 알아보는 AI의 발전
- 알고리즘은 데이터 분석가에게 필요할까?
- Analytics Engineer 직무 뜯어보기
- 데이터 분석을 위한 준비하고 배울 것들
- 시계열 Prophet 모형과 하이퍼파라미터 뜯어보기 with 주가데이터
- Google bigquery에 데이터를 적재하고 태블로로 데이터 가져오기
'Data Science' 카테고리의 다른 글
| DataScience 책 추천(교양, 통계, 데이터과학, 머신러닝, 프로그래밍 등 ) (1) | 2024.06.10 |
|---|---|
| [글또] LLM 관련 모듈 동향 살펴보기- OPEN AI, Langchain , Pandas AI (0) | 2024.03.31 |
| [글또]시계열 Prophet 모형과 하이퍼파라미터 뜯어보기 with 주가데이터 (1) | 2024.02.27 |
| [글또] 데이터 분석을 위한 준비하고 배울 것들 (0) | 2024.02.18 |
| [글또]Analytics Engineer 직무 뜯어보기 (4) | 2024.01.21 |